
AutoPE:自动训练PLM模型的agent
Abstract
蛋白质工程在生物医学应用中至关重要,但传统方法往往效率低下且资源消耗巨大 。尽管深度学习(DL)模型展现了巨大潜力,但对于没有专业计算知识的生物学家来说,训练或应用这些模型仍然充满挑战 。为了解决这个问题,研究者们提出了 AutoProteinEngine (AutoPE),这是一个由大型语言模型(LLM)驱动的智能体框架,专为蛋白质工程中的多模态自动化机器学习(AutoML)而设计 。AutoPE 的一个创新之处在于,它允许没有深度学习背景的生物学家使用自然语言与深度学习模型进行交互,从而显著降低了蛋白质工程任务的技术门槛 。
该框架独特地将 LLM 与 AutoML 相结合,以实现以下功能:
- 处理蛋白质序列和图谱两种模态并进行模型选择 。
- 自动进行超参数优化 。
- 从蛋白质数据库中自动检索数据 。
通过在两个真实的蛋白质工程任务中进行评估,AutoPE 的性能相较于传统的零样本(zero-shot)和手动微调(manual fine-tuning)方法取得了显著提升 。总而言之,AutoPE 通过弥合深度学习与生物学家领域知识之间的鸿沟,使得研究人员无需具备广泛的编程知识即可有效利用深度学习技术 。
1 Introduction
蛋白质工程专注于设计和优化具有特定功能的蛋白质,在药物发现、酶优化和生物材料设计等生物医学领域扮演着关键角色 。然而,传统的蛋白质工程方法,如定向进化和理性设计,通常存在效率低下、成功率低和资源需求高的缺点 。
以 ESM 和 AlphaFold 系列为代表的深度学习模型,极大地提升了蛋白质结构预测等任务的效率和准确性 。但是,对于缺乏专业编程和机器学习知识的生物学家来说,训练或微调这些复杂的深度学习模型是一项重大挑战 。具体困难包括:
- 模型架构复杂:需要深入理解DL原理才能有效修改和解读模型 。
- 超参数优化困难:调整超参数以优化性能非常依赖于机器学习的经验和直觉 。
- 数据预处理专业性强:处理蛋白质数据输入模型通常需要专门的预处理技术 。
- 数据呈现多模态:蛋白质数据可以表现为序列(sequence)和图(graph)两种形式,这进一步增加了模型训练和优化的难度 。
尽管自动化机器学习(AutoML)旨在减少训练DL模型所需的人力,但现有的AutoML框架仍然要求用户具备相当的深度学习和编程专业知识,这限制了它们在缺少计算背景的生物学家中的普及 。此外,这些通用框架通常缺乏蛋白质工程领域的特定知识,难以有效处理蛋白质序列和图谱数据 。
为了应对上述所有挑战,作者提出了一个基于大型语言模型(LLM)的智能体(Agent)框架,专门为蛋白质工程量身打造多模态AutoML功能 。利用LLM的对话式交互能力可以降低用户的学习曲线 ,最终目标是弥合DL模型与生物学家领域知识之间的鸿沟,使蛋白质工程的工作流程更加高效和易于使用 。
2 Methods
2.1 LLM-driven AutoML
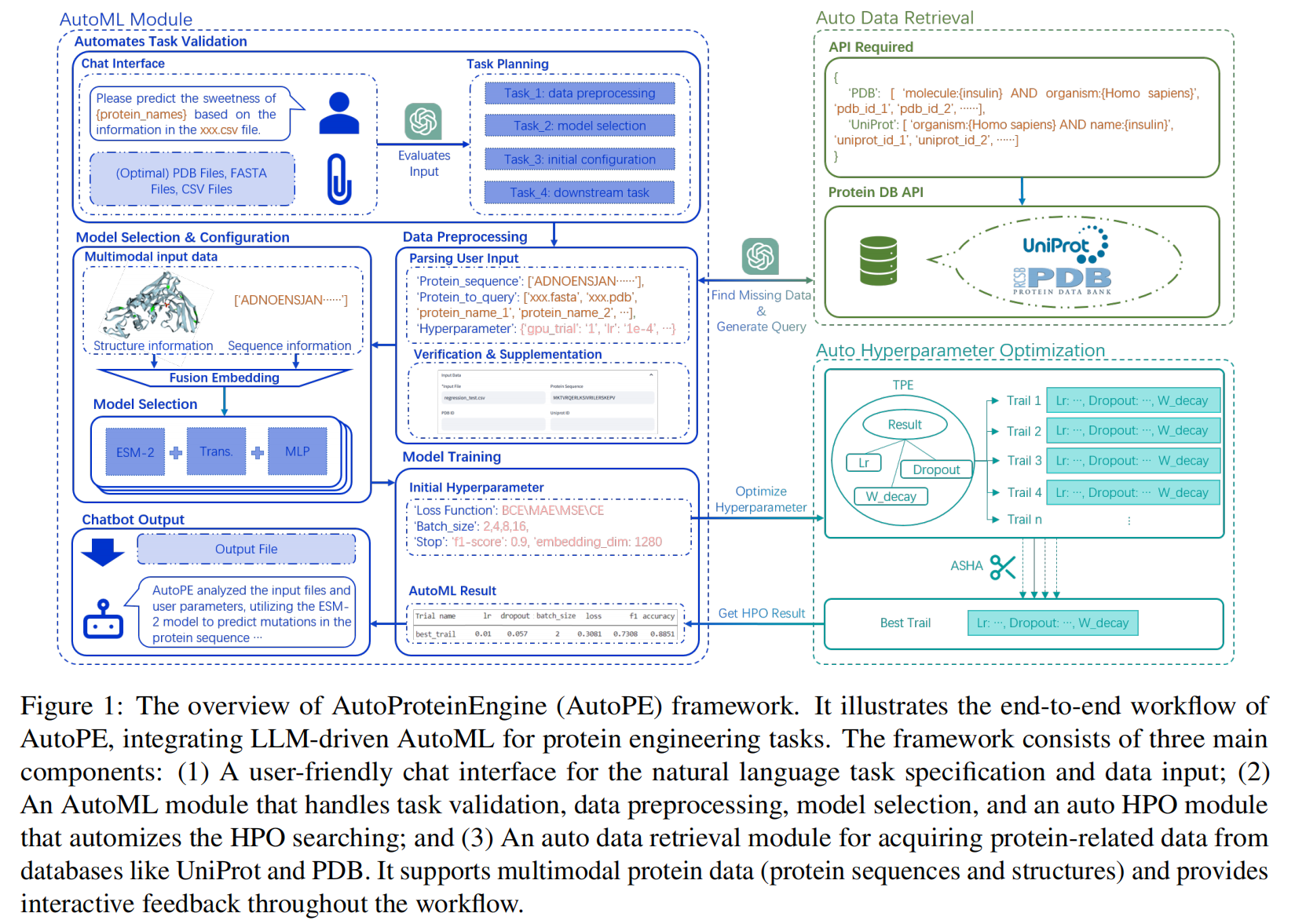
这是 AutoPE 框架的核心,其 AutoML 模块由一个大型语言模型(LLM)驱动,旨在自动化蛋白质工程中的各项任务 。
- 交互方式:用户(例如生物学家)无需深厚的计算专业知识,只需使用自然语言描述他们的蛋白质工程任务,例如“我需要训练一个模型来预测给定蛋白质序列的突变” 。
- 任务验证 (Task Validation):LLM 首先会评估用户的输入,判断任务是否属于 AutoPE 的能力范围,例如蛋白质稳定性预测、蛋白质相互作用预测等 。如果任务描述不清晰或超出范围,系统会通过对话来澄清或修正请求 。
- 任务规划 (Task Planning):一旦任务被验证,LLM 会制定一个行动计划 。该计划涵盖数据预处理策略、模型选择和配置等步骤 。LLM 利用检索增强生成(RAG)技术从相关文献中检索信息,以确保计划包含了蛋白质工程领域的特定知识 。
- 数据预处理 (Data Preprocessing):如果用户输入的数据不完整,数据检索模块会被激活,通过访问 PDB(蛋白质数据库)和 UniProt 等在线数据库来补充数据 。LLM 会根据任务需求自动构建相应的数据库查询语句 。
- 模型选择与配置 (Model Selection & Configuration):AutoPE 根据计划从预定义的模型库(如 ESM 系列、AlphaFold)中选择和配置合适的模型 。针对包含序列(sequence)和图(graph)*两种形式的多模态数据,AutoPE 采用一种*后期融合方案(late fusion scheme),将来自不同模态的嵌入(embeddings)结合起来,以利用互补信息 。
- 模型训练 (Model Training):LLM 会基于一个通用的训练框架进行优化,融入特定模型的细节 。这包括选择合适的损失函数、根据模型和数据集大小确定最优的批量大小(batch size)和学习率,以及实施早停(early stopping)和模型检查点(model check-pointing)来防止过拟合 。LLM 还会应用任务相关的数据增强技术,例如对序列数据进行随机突变 。
2.2 Auto Hyperparameter Optimization
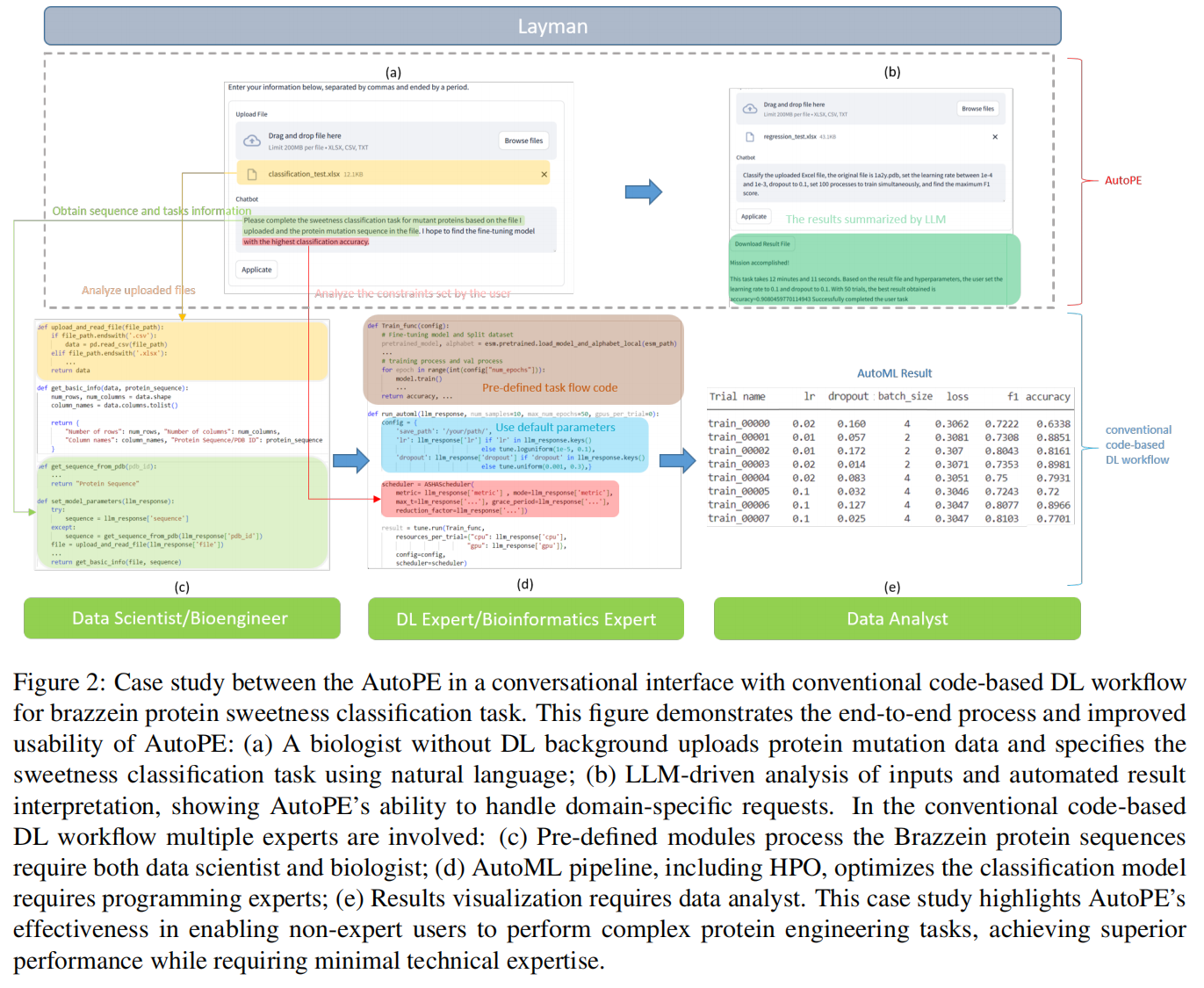
为了进一步提升性能和可用性,AutoPE 引入了一个自动超参数优化(HPO)模块 。
- 核心算法:该模块的核心包含两个阶段的技术:
- 树状结构Parzen估计器 (TPE):TPE 通过对产生好性能的配置进行概率建模,从而高效地探索超参数空间,专注于更有可能提升性能的区域 。
- 异步连续减半算法 (ASHA):ASHA 作为一种调度器,通过提前终止表现不佳的试验,并将计算资源动态地重新分配给更有希望的配置来优化资源利用 。
- 交互与解释:在 HPO 开始前,AutoPE 会与用户互动以确认超参数设置,这允许研究人员利用他们的领域知识 。在优化过程中,系统会提供自然语言形式的反馈,将 MSE 或 F1-score 等数值指标转化为易于理解的摘要,增强了过程的可解释性 。用户也可以通过自然语言指令来分配计算资源,例如指定每个试验分配的 GPU 数量 。
2.3 Auto Data Retrieval
该模块简化了蛋白质工程任务中必要数据的获取过程 。
- 自然语言查询:用户可以通过自然语言提出数据需求,例如“我需要人类胰岛素的序列和结构数据” 。
- 查询生成:LLM 会解析这个请求,识别出关键元素(如蛋白质名称:胰岛素,物种:人类,数据类型:序列和结构),然后自动构建适用于 UniProt 和 PDB 数据库的结构化查询语句 。例如,为 PDB 构建的查询可能是
molecule: {insulin} AND organism: {Homo sapiens}。 - 交互式反馈与灵活性:如果初步搜索没有结果,LLM 会引导用户进行交互式对话,提供替代方案,比如搜索其他哺乳动物的相关结构 。此外,系统还提供一个可编辑的表格界面,允许用户手动输入或验证检索到的数据,这对于整合私有或未发表的数据特别有用 。
- 结果汇总:数据收集完毕后,LLM 会生成一份详细的信息摘要,包括检索到的蛋白质序列来源、相关结构的 PDB ID 及其分辨率、关键的 UniProt 注释,以及数据中存在的任何缺失或潜在问题 。
3 Experiments
3.1 Dataset
为了评估 AutoPE 框架,研究者们分别针对分类和回归任务选择了两种不同的蛋白质 。
- 分类任务 (Brazzein 蛋白质):
- 数据来源:Brazzein 是一种高强度甜味剂蛋白 。
- 数据集构成:包含了 435 个 Brazzein 蛋白质的突变条目,包括单点和多点突变,以及它们对应的相对甜度测量值 。
- 标签划分:研究者以 100(相当于蔗糖甜度)的相对甜度为阈值,将突变体分为“甜”或“不甜”两类 。
- 回归任务 (STM1221 蛋白质):
- 数据来源:STM1221 是一种野生型蛋白质,是一种能特异性移除目标蛋白乙酰基的酶 。
- 数据集构成:包含了在多种突变情况下的 234 个酶活性得分,这些数据是通过湿实验确定的 。这是一个连续数据,用于预测不同突变下的酶活性水平 。
- 数据划分:每个数据集都被随机划分为 80% 的训练集和 20% 的测试集,并采用五折验证 。
3.2 Experiment Design and Implementation
实验旨在将 AutoPE 的性能与两种不同的方法进行比较:零样本推理和手动微调 。
- Zero-Shot Inference:
- 该方法利用预训练的蛋白质语言模型(即 ESM)来提取特征,而不进行任何针对特定任务的微调 。
- 这被用作评估 AutoPE 泛化能力的基线 。
- 在提取特征后,使用逻辑回归和 K-近邻(KNN)等传统机器学习算法进行功能评分预测 。
- Manual Fine-Tuning:
- 该方法通过手动微调预训练的蛋白质语言模型来增强特定任务的性能 。
- 定制化修改包括增加一个自注意力层,以捕捉蛋白质序列中的中长程依赖关系,从而提高模型识别复杂突变的能力 。
- 超参数搜索由一位拥有三年深度学习和蛋白质工程经验的机器学习工程师手动进行 。
- Evaluation Metrics:
- 分类任务:使用 F1-score(平衡精确率和召回率)、ROC-AUC(评估模型整体判别能力)和 SRCC(评估等级保留能力) 。
- 回归任务:使用 MSE(量化预测值与真实值之间的平均平方偏差)、MAE(计算平均绝对偏差,对异常值敏感度较低)和 R² 分数(评估模型的解释能力) 。
- Implementation Details:
- AutoPE 中使用的 LLM 是 TourSynbio-7B 。
- 所有实验都在 8 块 NVIDIA 4090 GPU 卡上进行 。
3.3 Results
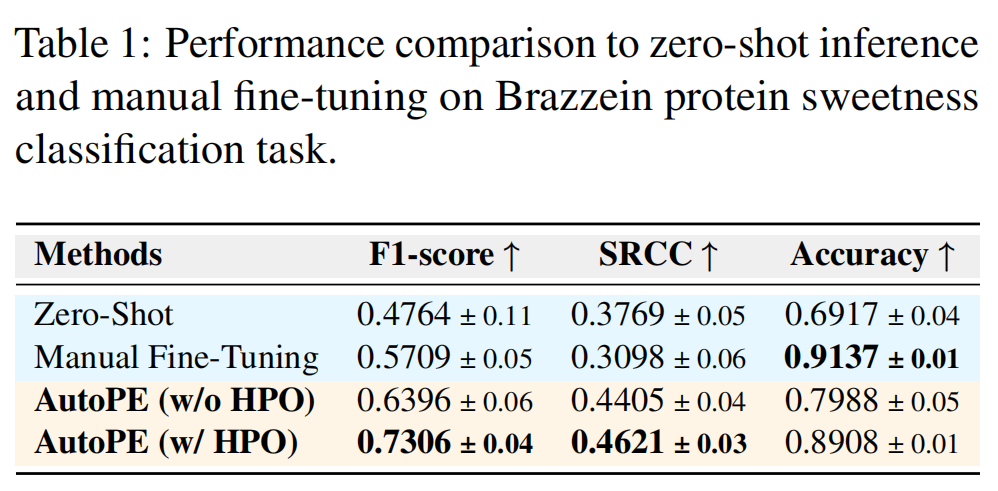
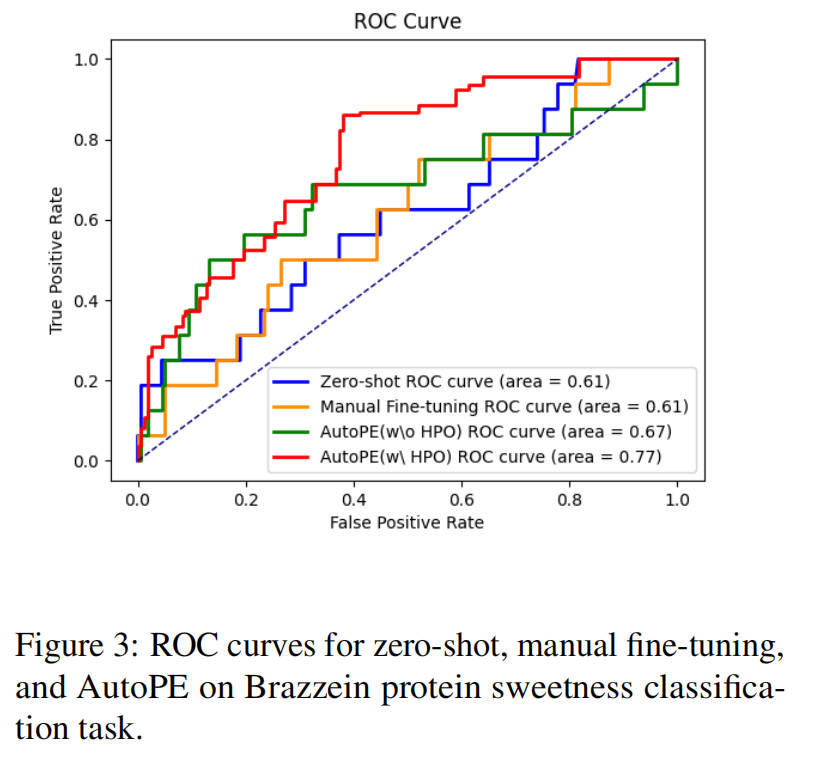
分类任务结果 (见表1和图3):
- AutoPE 表现优异,在所有指标上均展示出卓越性能,其 ROC 曲线最接近左上角 。
- 消融研究证实了 auto HPO 模块的有效性 。启用 HPO 的 AutoPE 取得了最高的 F1-score (0.7306) 和 SRCC (0.4621) 。
- 与手动微调相比,虽然手动微调获得了最高的准确率,但其较低的 F1-score 暗示了潜在的过拟合 。而启用 HPO 的 AutoPE 在高准确率 (0.8908) 与最佳 F1-score 和 SRCC 之间取得了最佳平衡,显示出更强的鲁棒性和泛化能力 。
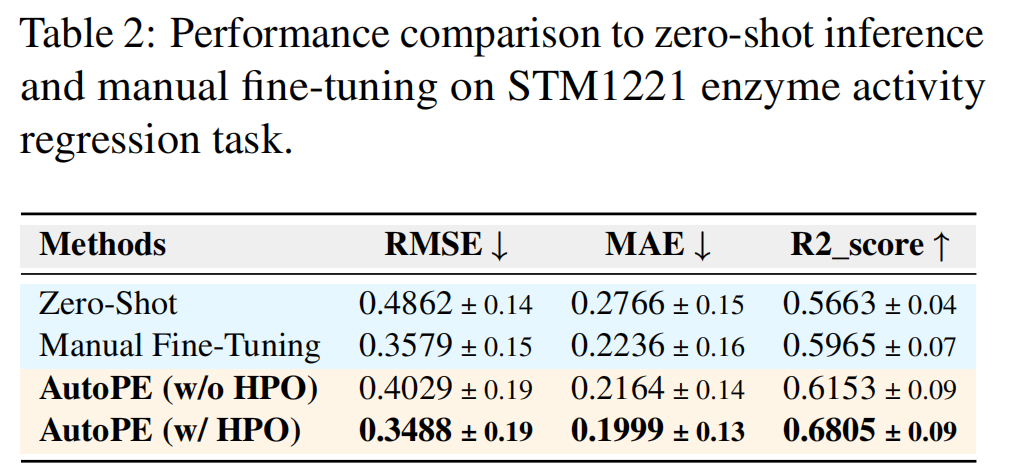
回归任务结果 (见表2):
- AutoPE 同样在所有指标上表现出色 。
- 启用 HPO 的 AutoPE 获得了最低的 RMSE (0.3488) 和 MAE (0.1999),以及最高的 R² 分数 (0.6805),这表明其对目标变量方差的解释能力最强 。
- 尽管手动微调在 RMSE 上表现具有竞争力,但启用 HPO 的 AutoPE 在所有指标上都持续优于它 。