
论文地址:BioPlanner:Automatic Evaluation of LLMs on Protocol Planning in Biology
BioPlanner:AI生成生物实验protocol和伪代码
Abstract
自动生成精确的科学实验方案是实现科学自动化的关键一步 。然而,大型语言模型(LLMs)虽然在许多任务上表现出色,却不擅长设计科学实验所必需的多步骤问题和长期规划 。此外,评估生成的实验方案的准确性本身就非常困难,因为正确的描述方式有多种,评估需要专家知识,而且通常无法自动执行来验证 。
为了解决这些问题,研究者提出了一个用于自动评估实验方案规划任务的框架 。他们同时推出了一个名为 BIOPROT 的数据集,其中包含了生物学实验方案及其对应的伪代码表示 。具体方法是:利用一个LLM将自然语言描述的实验方案转换成伪代码,然后评估另一个LLM在只知道高级描述和可用伪代码函数列表的情况下,重建这些伪代码的能力 。
论文评估了 GPT-3 和 GPT-4 在这项任务上的表现和鲁棒性 。为了证明伪代码表示法的实用性,他们通过检索已有的伪代码成功生成了准确的新实验方案,并在真实的生物实验室中成功执行了一个由模型生成的方案 。
1 Introduction
传统的生物学研究方法耗时、劳动密集且极易出现人为错误 。机器人实验室自动化有潜力提高研究的准确性、可重复性和可扩展性,从而促进更多的科学突破,并加速从研究到实际应用的转化 。
朝着生物研究自动化迈进的一个重要步骤是自动生成实验室方案(即为了达成特定目标而执行一个实验的精确分步指令),这些方案后续可以被转换成机器人代码 。研究者指出,大型语言模型(LLMs)拥有显著的潜在科学知识,因此可能能够制定出准确的科学方案,这一点在化学领域已经得到了验证 。然而,到目前为止,除了人工评估,还没有任何清晰的方法可以用来评估机器生成的科学方案的准确性 。没有成熟的评估指标,科学自动化领域的进展仍然充满挑战 。
研究者认为,评估实验室方案之所以困难,主要有两个原因。
- 首先,方案对微小的细节非常敏感,指令上的轻微变动就可能导致结果大相径庭 。在比较生成方案与标准答案时,那些依赖n-gram重叠度(如BLEU)或上下文嵌入(如BERTScore)的指标,可能无法捕捉到一些细微但关键的差异,例如操作的顺序或物质之间的关系 。
- 其次,同一个方案可以用不同层次的粒度被正确地描述 。例如,同一个技术(如测序文库制备)既可以用一行文字描述,也可以用多个段落来详细说明 。这种粒度上的可变性使得评估LLM生成方案的准确性变得非常困难 。
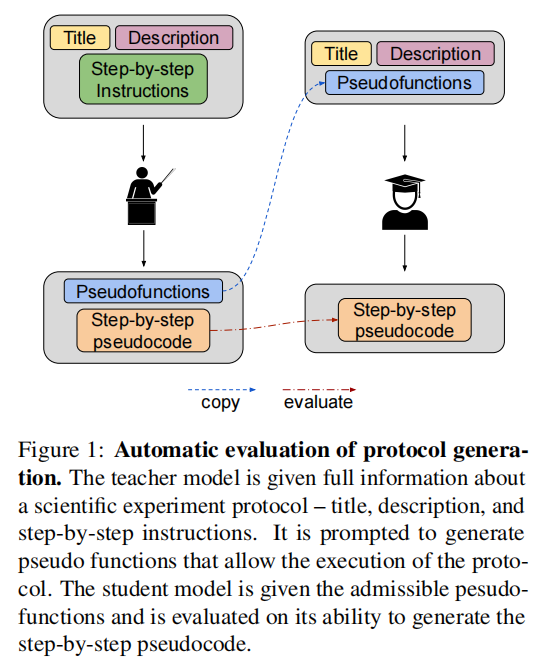
因此,该研究提出了一种自动化方法,用于评估语言模型编写生物学方案的能力 。该方法受到机器人规划的启发,即为控制器代理提供一个封闭的、允许执行的动作集合 。研究者使用GPT-4,让模型首先自动生成一套针对特定方案的伪函数(pseudofunctions),然后利用这些函数将书面方案自动转换成伪代码(见图1) 。
在这里,一个“教师”模型负责生成允许的动作集和正确的分步伪代码答案 。由于掌握了这些特权信息,研究者便可以评估一个“学生”模型的表现,该学生模型需要从零开始解决这个任务 。通过这种方式,他们评估语言模型在仅被给予适当的伪代码函数和方案简短描述时生成方案的能力 。
实际上,这种方法成功地将编写科学方案的过程自动转换成了一系列多项选择题(即从一个给定的集合中挑选一个伪函数),这种形式的评估远比评估自然语言生成要稳健得多 。这个范式使研究者能够以最少的人工干预,快速地衡量GPT-3.5和GPT-4的方案知识,并且可以作为一种通用方法,用于未来在开放式任务中评估和改进模型的长远规划能力 。
为此,他们还引入了一个新的数据集 BIOPROT,其中包含了公开的生物学实验室方案及其对应的协议特定伪代码 。该数据集经过领域专家的审查,可用于评估模型在多种不同任务(如下一步预测或完整方案生成)上的表现 。研究者进一步通过自动设计并成功执行一个实验室实验,展示了该数据集的实用性,实验中使用了GPT-4和BIOPROT中定义的动作空间 。
总而言之,该研究做出了以下贡献:
- 提议在伪代码而不是自由文本指令上评估方案生成 。
- 引入了 BIOPROT 数据集,这是一个经过人工审核的、包含开放获取生物学方案的数据集 。
- 评估了 GPT-4 将自然语言方案准确转换为伪代码的能力 。
- 为评估方案生成定义了一套任务和指标 。
- 在定义的任务上评估了数个LLMs,为这些模型生成生物实验的能力提供了客观的衡量标准 。
- 自动生成了一个生物学实验,并在实验室中成功地执行了它 。
3 The BIOPROT dataset

3.1 A Dataset of Protocols for Biology
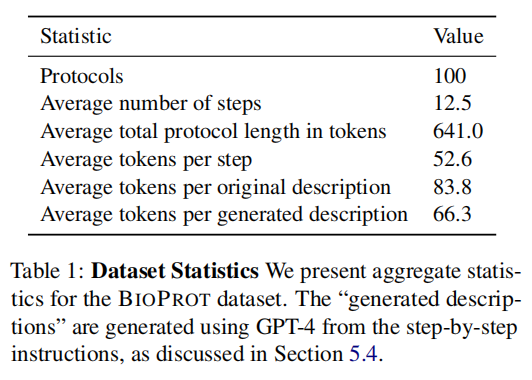
研究者从 Protocols.io 平台收集了公开的实验方案,这是一个用于开发和分享可复现方法的平台 。该数据库包含超过9000个涉及不同科学领域和复杂性的公开协议 。每个协议都包含 (i) 标题, (ii) 描述, 和 (iii) 分步说明 。为了得到一套与生物学相关、可复现且具有足够挑战性的协议,研究者对这些协议进行了自动和手动的双重筛选 。最终的数据集包含 100个协议,平均每个协议有12.5个步骤 。
3.2 Translating Protocols to Pseudocode

由于在自然语言文本中评估规划问题非常困难,以往的研究多采用人工评估 。为了解决这个问题,研究者利用 GPT-4 将自由文本的方案“翻译”成伪代码 。
他们给GPT-4分配了两项任务:
- 定义一套足以执行该协议的伪函数(pseudofunctions)
- 仅使用这些定义的伪函数,将协议步骤转换为伪代码 。
在这个过程中,他们使用了一个包含单一样例的提示(one-shot example prompt)和一个自动反馈循环 。这个反馈循环会在几种情况下提供错误信号,例如:生成的代码不是有效的Python伪代码、没有定义伪函数、函数或伪代码缺少参数,或者伪代码中的数值参数没有单位 。最后,GPT-4还会被提示检查自身在伪函数和伪代码中可能存在的错误或遗漏 。
3.3 Manual Verification

生成的伪函数和伪代码都经过了人工审查以确保其准确性 。一位有能力的实验室科学家逐行评估了原始的自然语言方案和生成的伪代码 。这位科学家确认了:
- 原始的自然语言方案是否合理
- 标题和描述是否足以让一位有能力的科学家在没有详细步骤的情况下尝试完成协议
- 伪代码是否准确
根据审查结果,研究者对生成的伪代码进行了必要的编辑 。统计结果显示,在100个协议中,有59个生成的协议完全准确,无需任何编辑 。许多需要编辑的协议也只涉及微小的修改 。最常见的错误是数字缺少单位 。更严重一些的错误通常是:
- 缺少成功完成某一步骤所需的关键细节
- 没有解释协议中使用的某种材料(如缓冲液)的成分
这些经过修正的协议最终构成了 BIOPROT 数据集 。研究者认为,即使没有人工编辑,带有错误检查循环的LLMs也能够创建一个在很大程度上准确的生物学协议伪代码数据集,从而实现自我评估 。
3.4 Machine-generated Descriptions
对于一些下游任务,高质量的协议描述是必不可少的,因为它能让人了解协议步骤应包含哪些内容 。然而,Protocols.io中的原始描述并不总是能满足这一要求 。为此,研究者还利用GPT-4,基于协议的详细步骤生成了新的、能提供高级别概述的协议描述 。最终,数据集中同时包含了这些机器生成的描述和原始描述 。
4 Metrics and evaluation
Next Step Prediction
在这个任务中,给定一个方案的标题、描述、一组允许使用的伪函数以及部分已完成的伪代码,模型需要正确识别出协议下一步对应的伪函数 。评估会同时考量预测的函数本身和函数参数的正确性 。
-
函数层面的准确性:研究者报告了正确函数分配的百分比,即准确率 (accuracy) 。
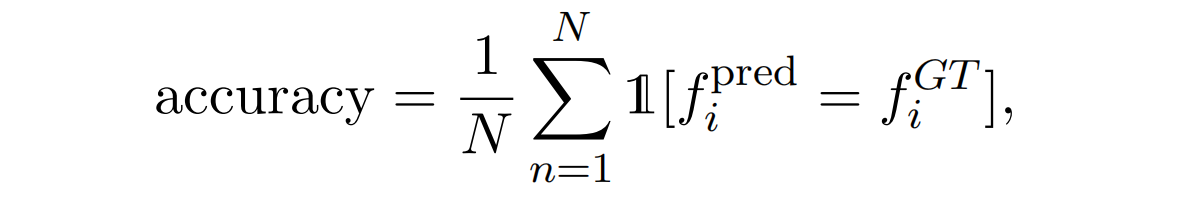
-
参数层面的准确性:
-
首先,通过计算精确率 (precision) 和 召回率 (recall) 来评估函数参数名称的正确性 。
-
对于名称正确的参数,使用 BLEU 指标来评估其值的准确性 。
-
此外,研究者还引入了 SciBERTScore 。该指标首先使用SciBERT句子编码器对预测和真实的参数值进行编码,然后计算它们之间平均余弦相似度 。这个指标受到BERTScore的启发,但使用了更适合科学领域的SciBERT编码器 。
-
值得注意的是,参数层面的指标只对函数被正确预测的情况进行计算,以避免对模型的错误进行双重惩罚 。
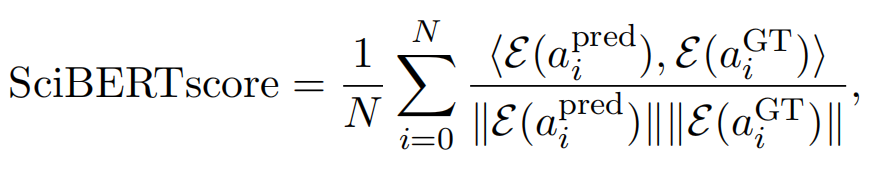
-
Protocol Generation
在这个任务中,给定一个方案的标题、描述和一组允许使用的伪函数,模型需要生成相应的完整伪代码 。这比上一个任务更困难,因为它要求模型规划协议的整个执行流程 。评估同样针对预测的函数及其参数 。
- 函数层面的评估:需要衡量两个方面:(i) 是否调用了正确的函数,以及 (ii) 是否以正确的顺序使用了它们 。
- 对于前者,研究者报告了函数调用的精确率 (precision) 和 召回率 (recall)(会考虑同一函数的重复调用)。
- 对于后者,研究者使用莱文斯坦距离 (Levenshtein distance, Ld) 来衡量预测的函数序列与真实函数序列之间的差异 。莱文斯坦距离是一种字符串编辑距离,它计算将一个词转换成另一个词所需的插入、删除或替换次数 。在这里,每个函数调用被视为一个独立的符号 。研究者报告的是归一化的莱文斯坦距离 (Ldn) 。
- 参数层面的评估:使用的指标与“下一步预测”任务中所描述的完全相同 。
Function Retrieval
该方法有潜力通过组合数据集中现有协议的步骤来组装新的协议,前提是模型能够正确识别出任何给定协议需要哪些步骤 。因此,在这个任务中,给定一个方案的标题和描述,以及一大堆伪函数,模型需要正确识别出执行该协议所需的函数子集 。
- 任务设置:提供给模型的伪函数集合中,不仅包含当前协议的真实伪函数,还混入了来自其他几个 (i) 随机协议或 (ii) 最近邻协议的伪函数作为干扰项 。从最近邻协议中挑选干扰项会使任务更困难,因为它们的函数可能与正确函数更相似 。
- 评估指标:使用精确率 (precision) 和 召回率 (recall) 来衡量检索到的函数的表现 。
5 Experiments
5.1 Implementation details
研究者主要探索了来自OpenAI API的 GPT-3.5 和 GPT-4 的性能 。在寻找最近邻协议时,他们使用了 text-embedding-ada-002 模型对所有协议描述生成的嵌入向量 。
研究者在第四章列出的各项任务中,对模型进行了几种不同设置下的评估 :
- Shuffled (打乱顺序):提供给模型的伪函数可以是按照它们在原始协议中生成的顺序,也可以是随机打乱的顺序 。函数定义的原始顺序往往与它们在协议中出现的顺序一致,这会给模型提供一个信号 。通过随机打乱输入函数,可以增加任务的难度 。
- Feedback (反馈):模型可以访问一个错误循环,该循环能检测未定义的函数和Python语法错误 。已有研究发现这种反馈循环在规划和推理任务中是有益的 。
5.2 Results
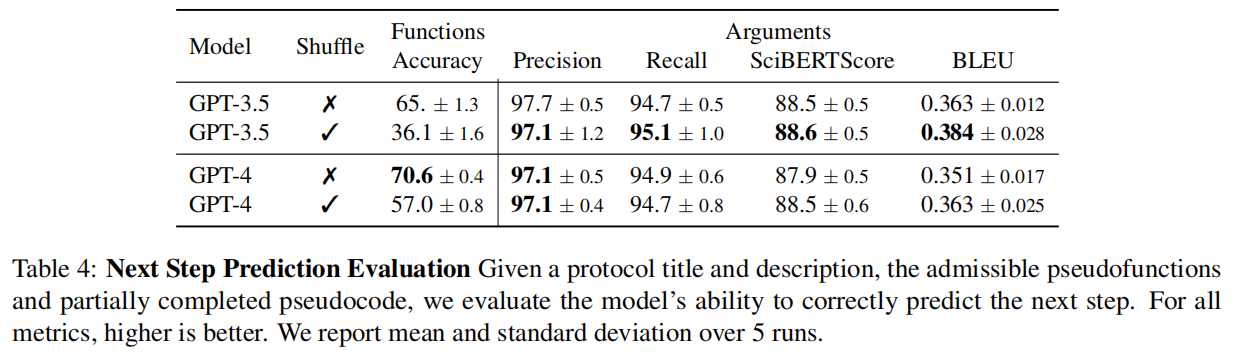
- 下一步预测:实验结果(见表4)显示,在预测正确的下一步骤方面,GPT-4 持续优于 GPT-3.5,而 GPT-3.5 在预测函数参数方面表现更好 。研究者注意到,当输入的函数被打乱顺序时,模型性能会下降,这很可能是因为未打乱的函数顺序本身就是一种提示 。
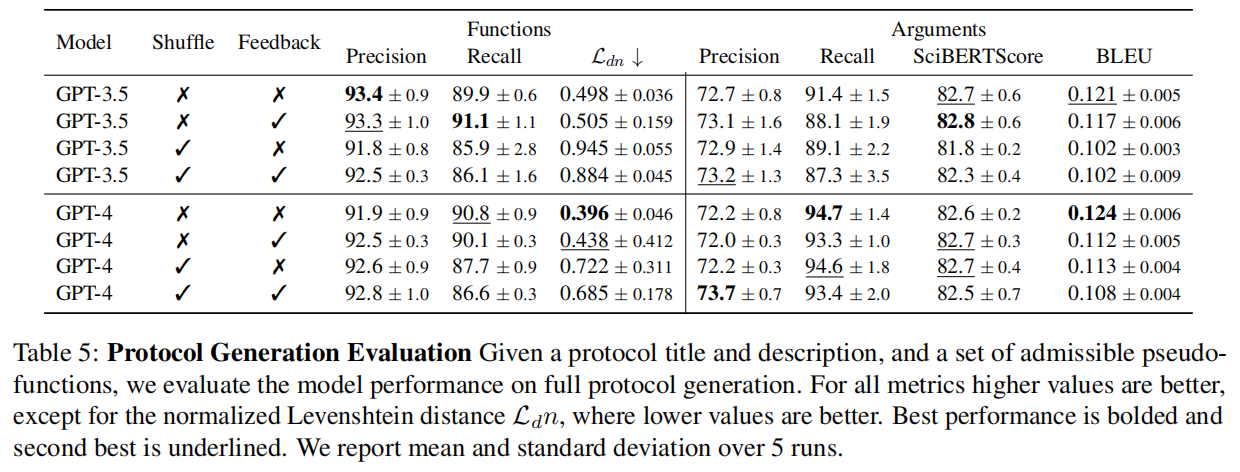
- 方案生成:在完整方案生成任务中(见表5),最大的性能差距体现在莱文斯坦距离上,GPT-4 在此指标上显著优于 GPT-3.5 。这表明,尽管两个模型选择正确函数的能力相似(精确率和召回率相近),但 GPT-4 在安排函数顺序方面表现更佳 。同样,打乱输入函数的顺序会导致性能持续下降 。
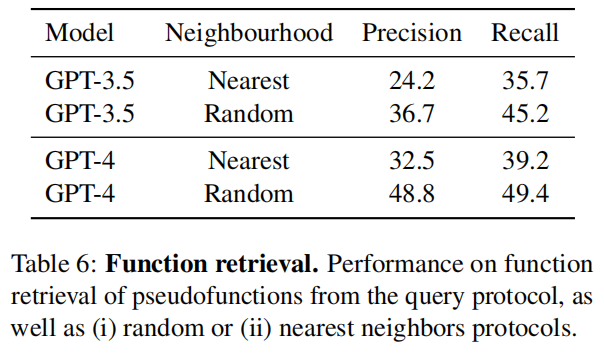
- 函数检索:结果(见表6)显示,GPT-4 在此任务上优于 GPT-3.5 。然而,这项任务的总体结果显得较差 。一个可能的原因是正确答案有时可能存在歧义 。例如,
Mix和MixSubstance这两个函数在语义上相同,但语法不同,模型若选择了非查询协议中的函数就会被判错 。这种效应也解释了为什么当干扰项来自“最近邻”协议时,性能反而比来自“随机”协议时更差 。
5.3 Using GPT-4 as an evaluator
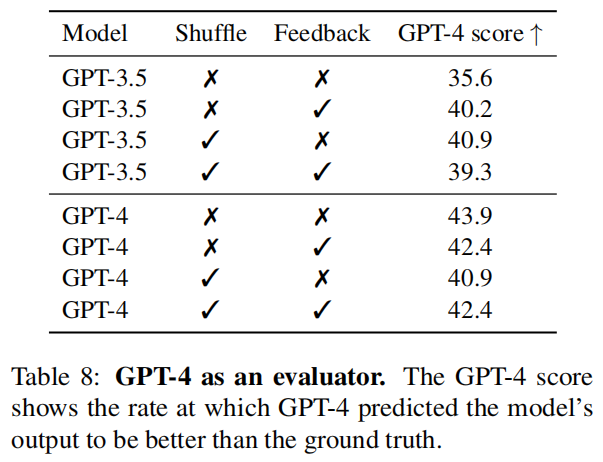
研究者尝试使用GPT-4作为评估者 。他们向GPT-4提供协议描述、允许的伪函数、真实的伪代码以及模型预测的伪代码,并让它判断哪个版本的伪代码与描述更匹配 。结果(见表8)显示,GPT-4在识别真实协议方面的表现仅略高于随机猜测 。目前尚不清楚这是因为机器生成的协议本身已经基本正确,还是因为GPT-4无法区分正确与错误的协议 。需要注意的是,先前有研究发现GPT评估者倾向于偏爱更长、更连贯的文本,而不一定是更正确的文本 。
5.4 Using GPT-4-Generated Descriptions
研究者观察到,某些协议的原始描述所包含的细节不足以支持协议的重建 。为此,他们使用GPT-4根据自然语言的协议步骤生成了简短的伪描述 。结果显示,在下一步预测和完整方案生成任务中,使用GPT-4生成的描述会带来轻微的性能提升 。
5.5 Real-World Validation
为了验证BIOPROT数据集可以用于生成准确的新协议,研究者设计了一个端到端的协议创建流程 。他们构建了一个类似Toolformer的LLM智能体(agent),该智能体使用GPT-4并具备CoT(Chain-of-Thought)能力,可以访问一个用于在BIOPROT数据库中搜索协议的工具 。智能体被提示为新的目标协议检索相关协议,然后从检索到的协议中提取伪函数,并仅使用这些函数来生成新协议 。研究者利用此设置创建了两个实验:(1) 过夜培养大肠杆菌菌落并制作甘油菌种;(2) 培养共生藻(Symbiodinum)、提取其DNA并在琼脂糖凝胶上进行电泳 。
5.6 Real-World Validation Results

模型利用数据库中的伪函数成功生成了两个新协议 。这两份协议经过一位科学家审查,被认定为准确且足以让一位合格的实验室科学家遵循执行 。
研究者选择在实验室中执行第一个关于大肠杆菌的协议 。他们完全按照模型提供的指令和参数值实施了该协议,实验取得了成功 。实验结果证明,经过-80°C储存后,细胞仍然存活,这一点通过它们随后在营养琼脂上成功培养得到了证实(如图3所示)。这一结果表明,LLM生成的协议是正确的 。