
ACEBench:评估LLM调用工具
Abstract
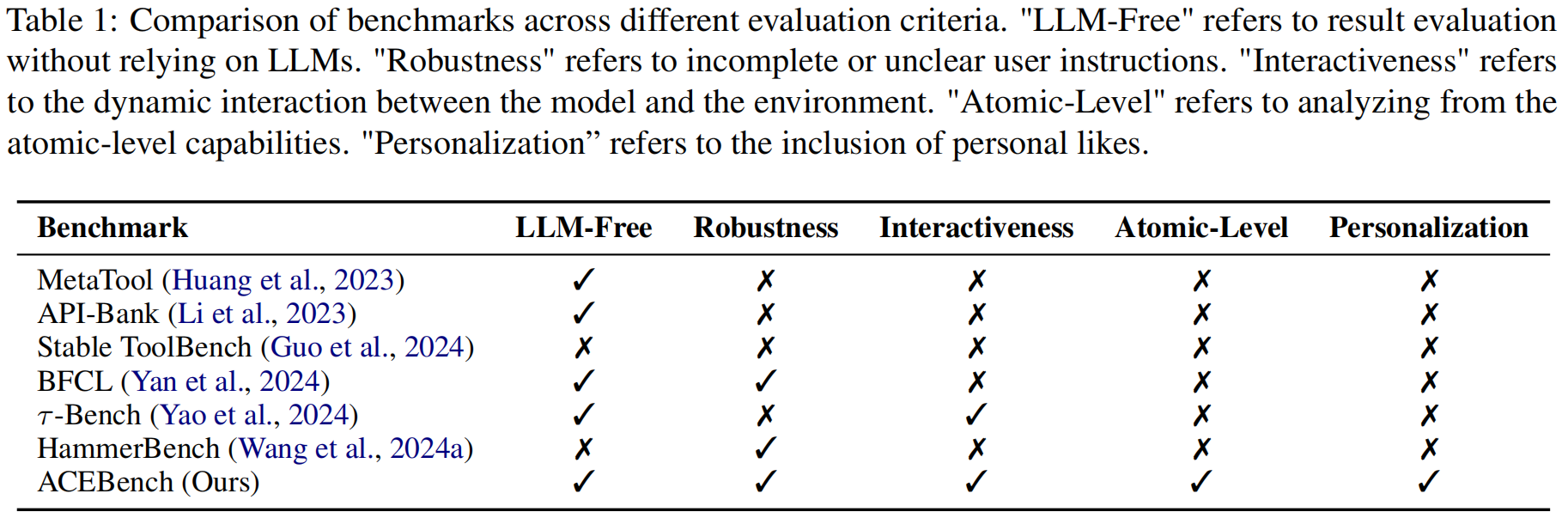
大型语言模型(LLMs)在决策和推理方面展现了巨大潜力,尤其是当它们与各种工具集成以解决复杂问题时 。然而,现有的用于评估LLMs工具使用的基准测试面临几个局限性 :
- 评估场景有限:通常缺乏在真实多轮对话上下文中的评估 。
- 评估维度狭窄:对LLMs如何使用工具的详细评估不足 。
- 评估依赖问题:依赖LLMs或真实的API执行进行评估,这带来了显著的开销 。
为了应对这些挑战,研究人员引入了 ACEBench,这是一个用于评估LLMs工具使用的综合基准测试 。ACEBench根据评估方法将数据分为三种主要类型:Normal(常规)、Special(特殊)和 Agent(代理) 。
- “Normal” 评估在基本场景下的工具使用 。
- “Special” 评估在指令模糊或不完整情况下的工具使用 。
- “Agent” 通过多智能体互动来评估工具使用,以模拟真实的、多轮的对话 。
研究人员使用ACEBench进行了广泛的实验,深入分析了各种LLMs,并对不同数据类型中的错误原因进行了更精细的审查 。
1 Introduction
大型语言模型(LLMs),例如GPT-4,已经在众多自然语言处理任务中展现出卓越的性能 。研究表明,整合工具能显著扩展LLM的能力 ,尤其是在数学 、编程 和推理 等专业领域。一方面,将工具集成到LLMs中可以增强其在多个领域的能力,例如ToolTransformer就通过利用工具提升了LLM解决复杂问题的能力 。另一方面,采用工具使用范式可以提高响应的鲁棒性(robustness)和生成的透明度(transparency),从而增加用户的可解释性(explainability)和信任度,并改善系统的适应性(adaptability) 。随着该领域的不断发展,全面评估工具使用的各个方面变得至关重要,特别是在复杂场景下 。
尽管已有几项研究关注工具使用的评估 ,但现有的工具使用基准测试仍存在一些缺点 。首先,现有基准测试缺乏真实世界场景下的多轮对话评估 。例如,BFCL 和 HammerBench 中的多轮对话是由预定义的固定内容组合而成 。其次,当前的工具使用基准测试缺乏细粒度的评估和个性化数据评估 。此外,现有基准测试忽视了特殊情况的评估 ,或者评估方法过于简单 。现实生活中的用户指令并不总是完美的 ,而模型识别和处理这些问题的能力对于评估也至关重要 。最后,评估成本高昂 ,因为许多研究依赖先进的大型模型(advanced large models)进行评估 。
为解决这些缺点,作者团队提出了 ACEBench ,一个综合性的工具使用基准测试,包含以下几类 :
- Normal (常规):由固定的问答对组成,涵盖了包括单轮对话、多轮对话和个性化场景数据在内的多种场景 。它还包括对原子级(atomic-level)能力的评估 。
- Special (特殊):包括不完美的指令,例如包含不完整参数、格式不正确参数的指令,或与候选函数能力无关的问题 。
- Agent (代理):涵盖真实世界场景,通过抽象构建多轮、多步骤的工具调用场景 。根据用户是否参与对话过程,分为多轮(multi-turn)和多步(multi-step)案例 。
作者指出,这三类数据覆盖了LLM工具使用的大多数场景 。
论文的主要贡献如下:
- 全面的基准测试评估 (Comprehensive Benchmark Evaluation):提出了一个评估LLMs工具使用的综合基准测试,覆盖了各种场景,包括更细粒度的评估视角、不完美指令下的评估,并提供了更稳定的评估指标 。
- 沙盒环境与自动化评估系统 (Sandbox Environment and Automated Evaluation System):构建了一个端到端的自动化评估系统 ,并为基于真实世界场景抽象的多轮、多步工具调用开发了沙盒环境构建方案 。
- 广泛的实验验证 (Extensive Experimental Validation):通过广泛的实验证明,该基准测试提供了更全面且更具区分度的分析,为LLMs的工具使用提供了更清晰的评估 。
3 ACEBench
3.1 Dataset
研究人员构建了数据集的两种语言并行版本(中文和英文),确保了数据类型在两者间的平等分布。最终的数据集包含2,000个标注条目。
3.1.1 Data Construction
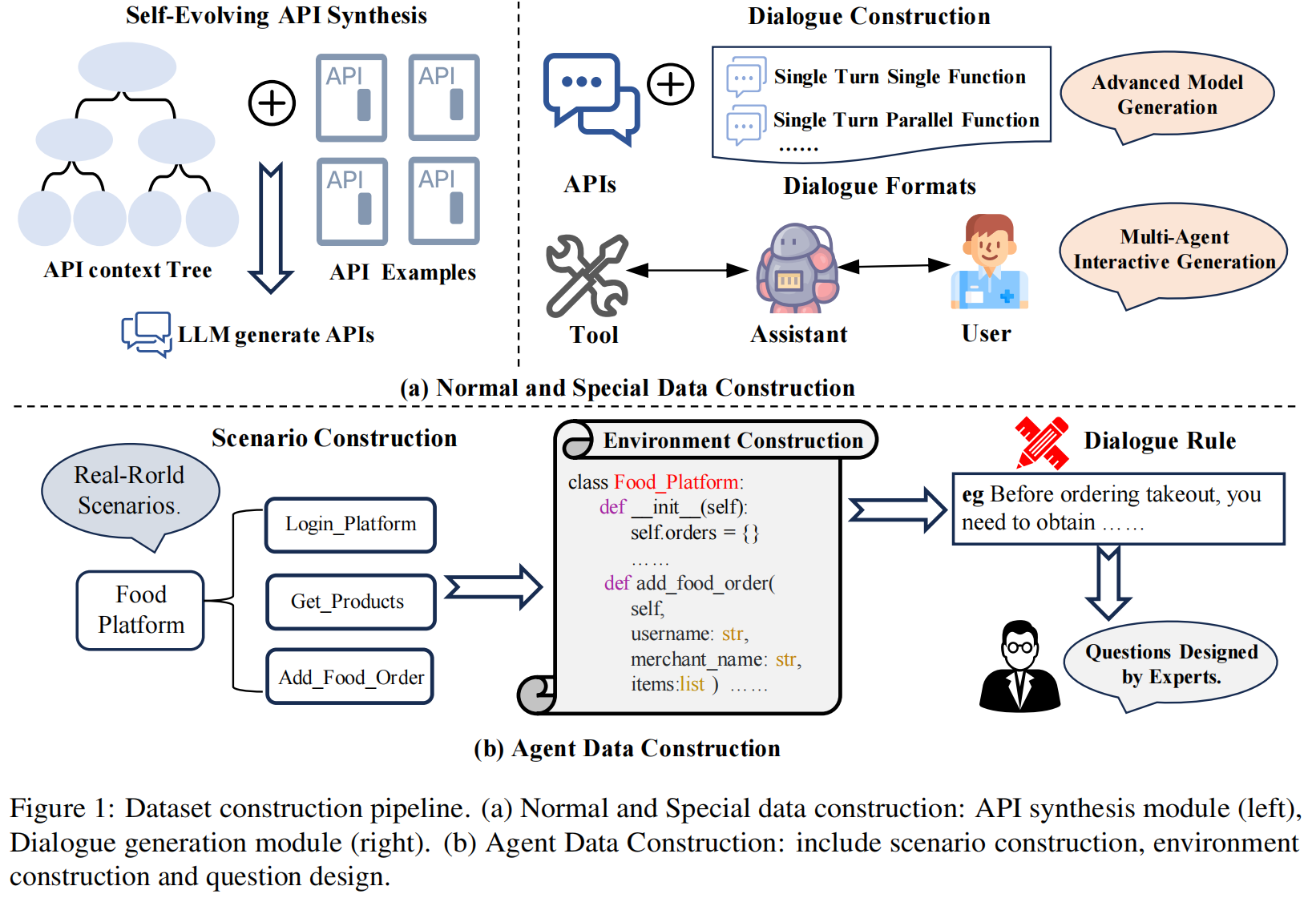
Normal(常规)和 Special(特殊)数据由LLMs自动生成,而 Agent(代理)数据则由专家构建 。Normal 和 Special 数据的构建 研究人员采用了一个专为Normal和Special数据设计的全自动、基于LLM的生成流程,如图1(a)所示 。
- (1) API 合成 (API Synthesis):在构建过程中使用来自不同真实世界场景的真实API作为参考,以增强真实性 。为确保数据稳定性,研究人员使用合成的API(synthetic APIs)来构建评估数据集,并以真实API为指导 。他们采用一种自进化(self-evolution)方法,通过构建层次化的API上下文树(API context tree)来确保生成的API覆盖广泛的领域和功能 。该过程首先从技术文档中提取相关信息以指导API生成 ,随着过程推进,上下文树逐渐扩展,最终确保生成API的深度和广度 。
- (2) 对话构建 (Dialogue Construction):研究人员使用两种不同的对话生成流程 。在构建的API池中,为每个评估实例选择三到六个候选API 。大多数情况下,API是随机选择的 ;但对于需要特定功能的实例(如相似API或多轮场景),则使用包括基于图的采样(graph-based sampling)在内的先进方法 。简单案例或具有预定义功能的案例使用基于模板的生成 。对于更复杂的场景,则采用多智能体对话流程(multi-agent dialogue pipeline),由三个智能体(用户、助手和工具)模拟真实世界的互动 。
Agent 数据的构建 研究人员为Agent数据的生成实现了一个精心策划的、由人类专家构建的框架,如图1(b)所示 。
- (1) 场景构建 (Scenario Construction):通过对真实世界交互场景(如送餐服务和电信运营)进行系统性抽象 ,研究人员设计了具有明确业务语义的功能模块,并规定了每个场景的核心状态变量(如订单状态、账户余额)和固有属性集 。
- (2) 沙盒环境构建 (Sandbox Environment Construction):研究人员构建了一个隔离的沙盒环境,包含三个核心组件:具有明确输入/输出规范和前提条件的标准化功能接口、用于实时状态转换监控的动态属性管理系统,以及记录调用过程的执行监控模块 。
- (3) 问题设计 (Question Design):基于为不同场景定制的预定义多轮对话规范,领域专家通过迭代标注过程系统地精心设计了对话问题 。
3.1.2 Multi-Stage Data Verification
为解决答案不匹配或标准模糊等问题,研究人员实施了多阶段验证流程 。
- 自动化质量检查 (Automated Quality Inspection):
- 数据首先通过基于规则的质量检查模块,该模块评估四个维度:API定义的清晰度、函数调用的可执行性、对话的准确性以及数据样本的一致性 。
- 接着,数据进入基于模型的质量验证模块,该模块使用LLMs检测语义错误,并采用投票机制确保评估的一致性 。
- 人工质量检查 (Human Quality Inspection):在初步评估中,自动化检查后剩余的数据集由三个LLMs进行评估,以协助人类专家筛选数据 。有效数据被保留,而潜在有问题的数据被放入错误候选池 。这些被标记的条目会经过一个两步的专家审查流程:
- 两名专家独立评估并提出修改建议,第三名专家整合反馈并修订问题陈述、API定义和答案 。
- 修订后的数据被重新评估和手动验证,并执行了三轮优化以确保数据集的高质量 。
3.1.3 Data Analysis
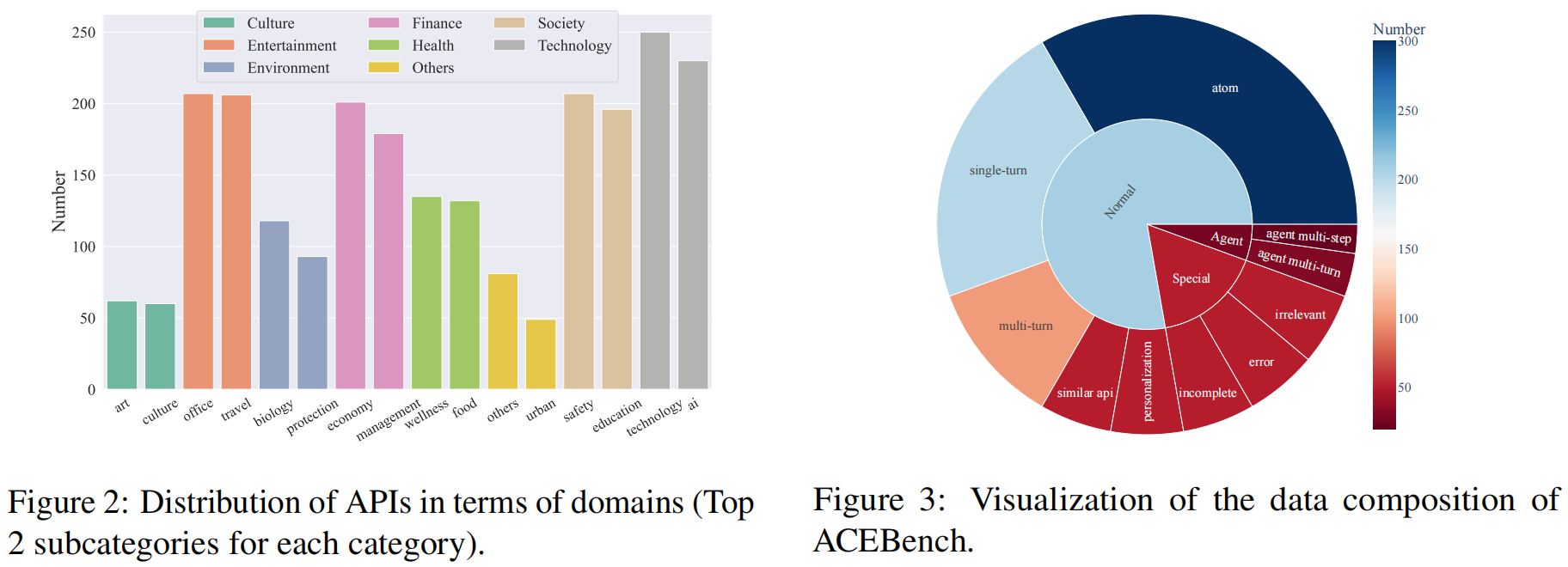
为展示ACEBench的广度和全面性,研究人员提供了其测试用例分布的详细分析 。
- API 的领域 (Domain of APIs):ACEBench API 覆盖了8个主要领域和68个子领域,涵盖日常生活的各个方面,包括技术、金融、娱乐、社会、健康、文化、环境等 。它提供了中英文共4,538个API的丰富集合 。这些API的分布如图2所示 。
- 数据组成 (Data Composition):ACEBench由三类测试样本组成:Normal、Agent 和 Special,每个类别又分为几个子类别 。数据构成如图3所示 ,展示了对工具使用能力的全面覆盖,从简单的单轮工具调用到涉及用户和环境的复杂多轮互动 。它们包括需要多步骤和与环境互动的场景,以及工具调用不可行的情况 。
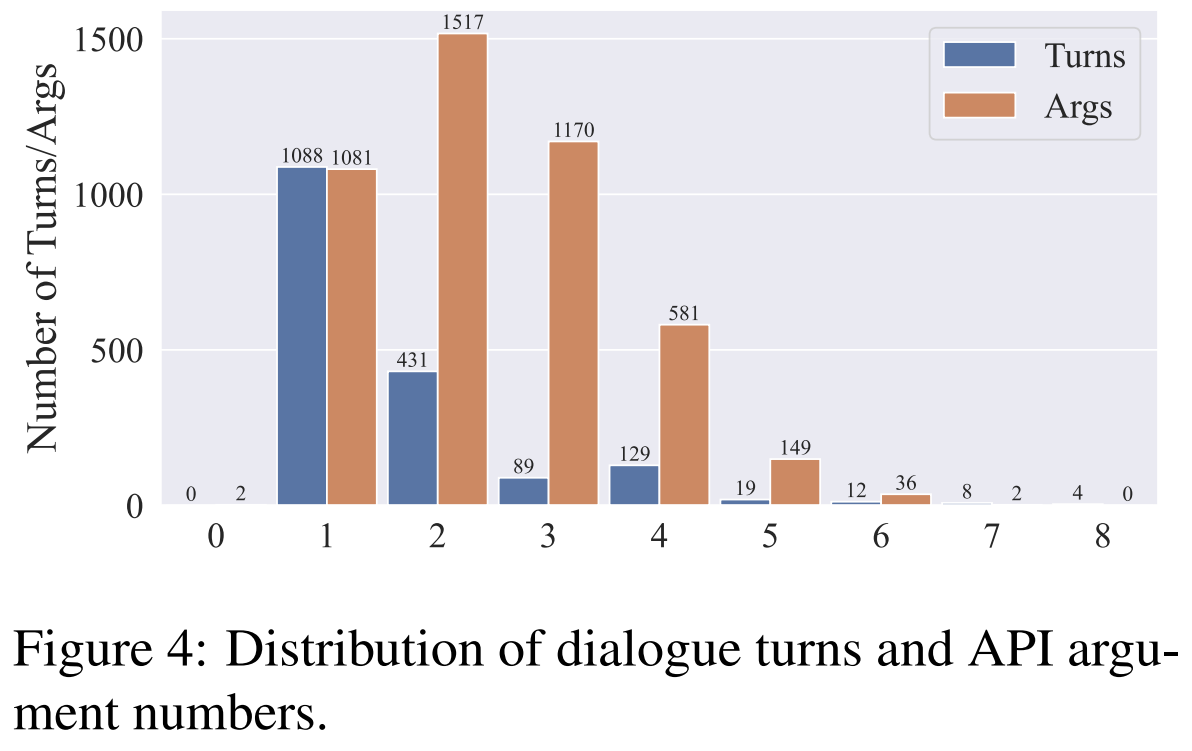
- 轮数和参数数量 (Number of turns and arguments):ACEBench中的测试数据覆盖了广泛的复杂度 。研究人员统计了对话轮数和所调用API中的参数数量,并将其可视化于图4 。结果显示对话轮数范围从1到8,涵盖了大多数真实世界场景 。
3.2 Eval
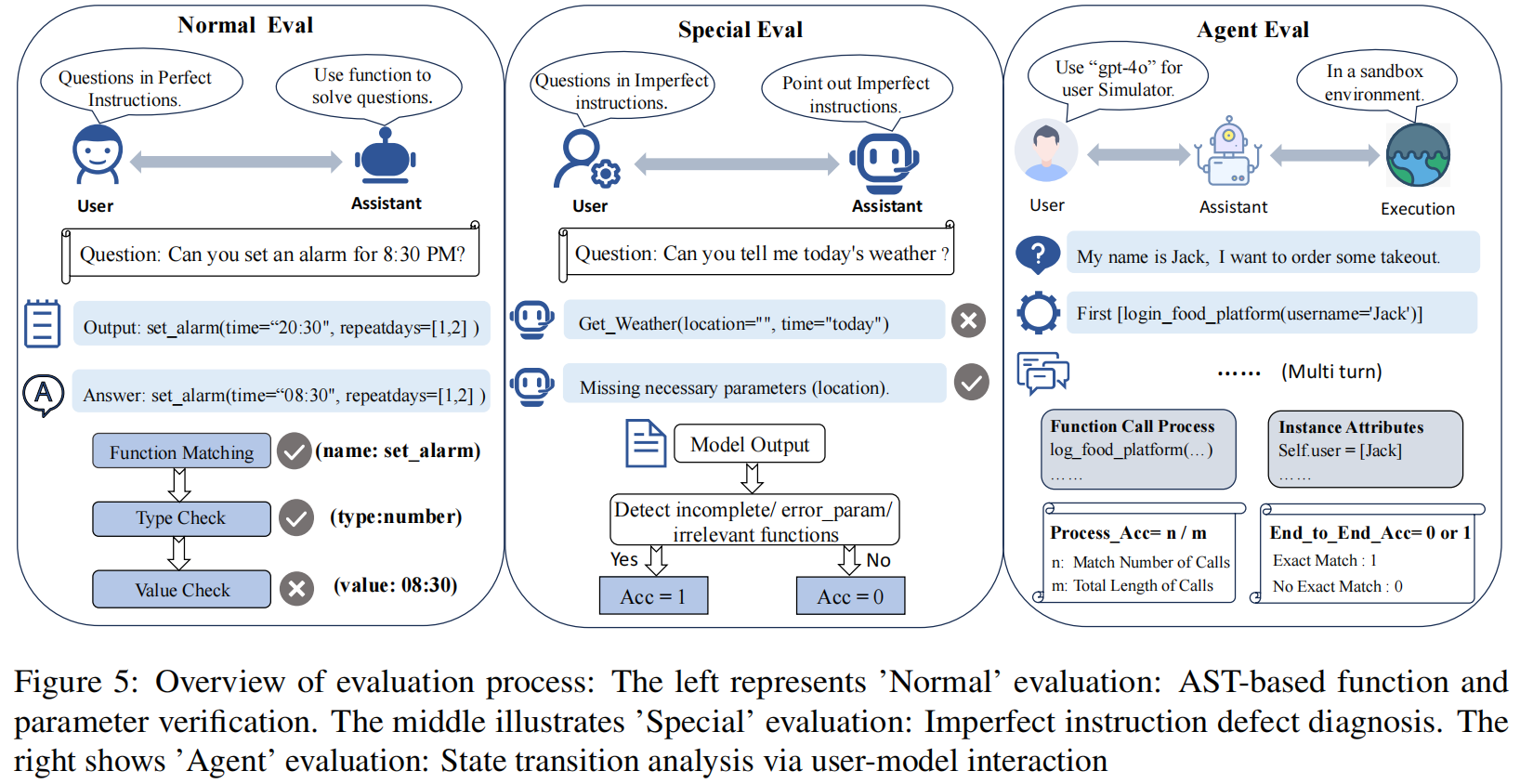
3.2.1 Normal Evaluation
如图5左侧所示,研究人员通过使用AST解析(AST parsing)比较模型的函数调用输出与标准答案(ground truth)来评估Normal数据 。对于有多个有效答案的情况,他们采用了一个候选答案池,匹配池中任何一个候选答案即视为正确 。评估使用准确率(Accuracy)指标($1=$ 完全匹配, $0=$ 不匹配) 。
3.2.2 Special Evaluation
如图5中部所示,Special数据的评估主要评估模型在问题识别(problem identification)方面的能力 。具体而言,模型必须:(1) 检测并警示缺失的参数,(2) 准确定位错误的参数,以及 (3) 识别任务与功能不匹配的情况 。对于每个案例,如果正确识别,准确率(Accuracy)计为1,否则为0 。
3.2.3 Agent Evaluation
如图5右侧所示,研究人员通过评估模型在人机交互中使用工具的熟练程度(proficiency)来评估Agent的能力 46,评估中使用了 gpt-4o 作为用户模拟器(user simulator)进行测试。评估指标有两个:
- 端到端准确率 (End-to-End Accuracy):通过比较相应类的实例属性(instance attributes)与目标(target)来评估 48。如果所有属性完全匹配,准确率为1;否则为0。
- 过程准确率 (Process Accuracy):由实际函数调用过程与理想过程(ideal process)之间的一致性决定 50。表示为 $\frac{n}{m}$,其中 $m$ 代表理想的函数调用过程, $n$ 代表实际与理想过程之间的匹配程度。
3.2.4 Overall Accuracy
总体准确率(Overall Accuracy)计算为Normal、Special 和 Agent 数据类型准确率的加权总和,权重由它们各自样本量的平方根决定 。
4 Experiments
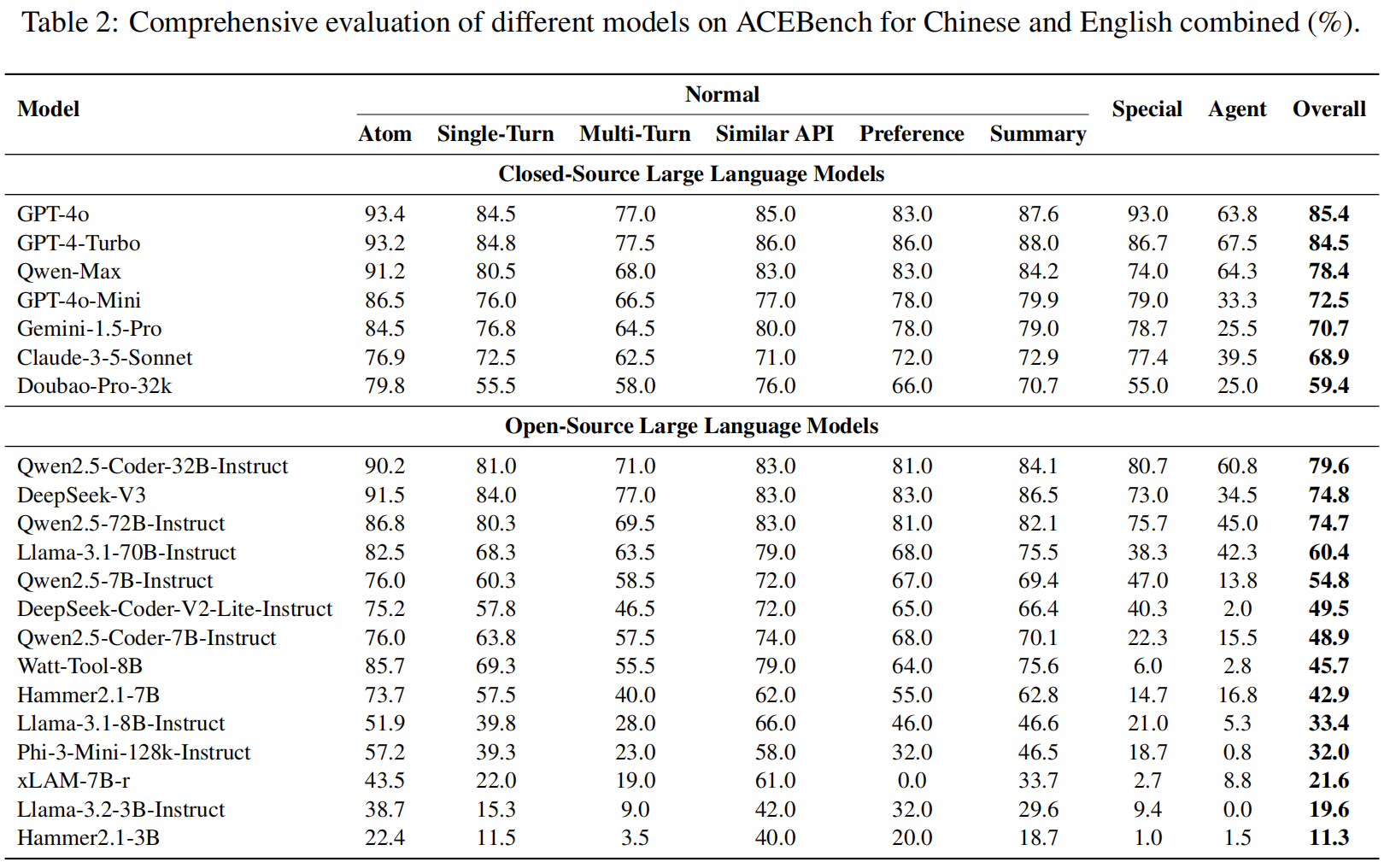
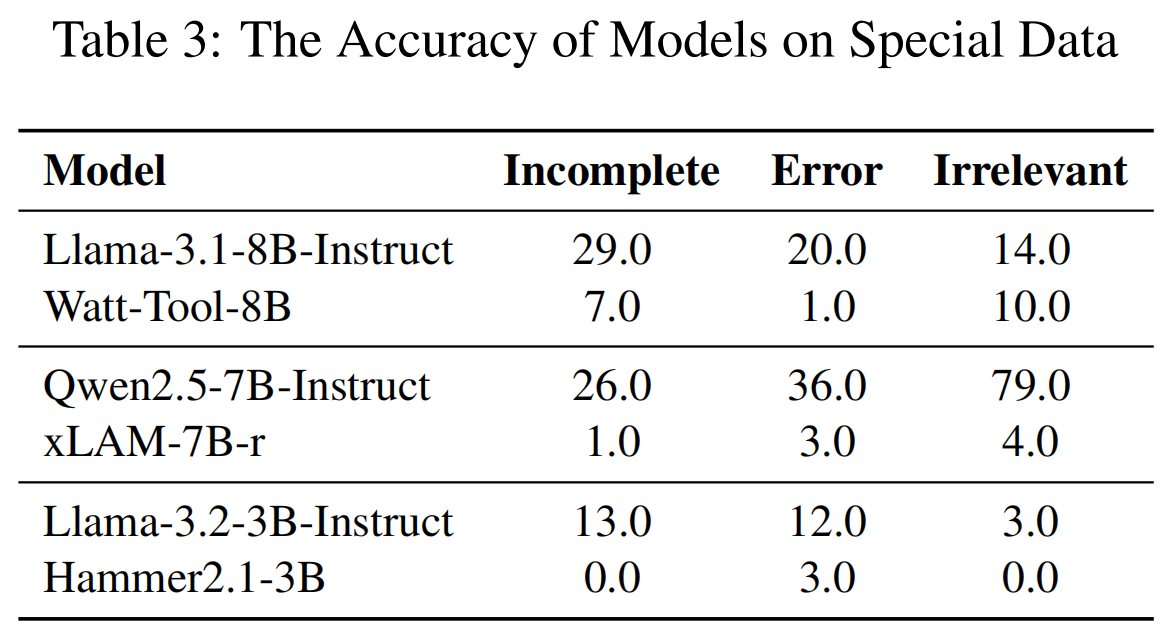
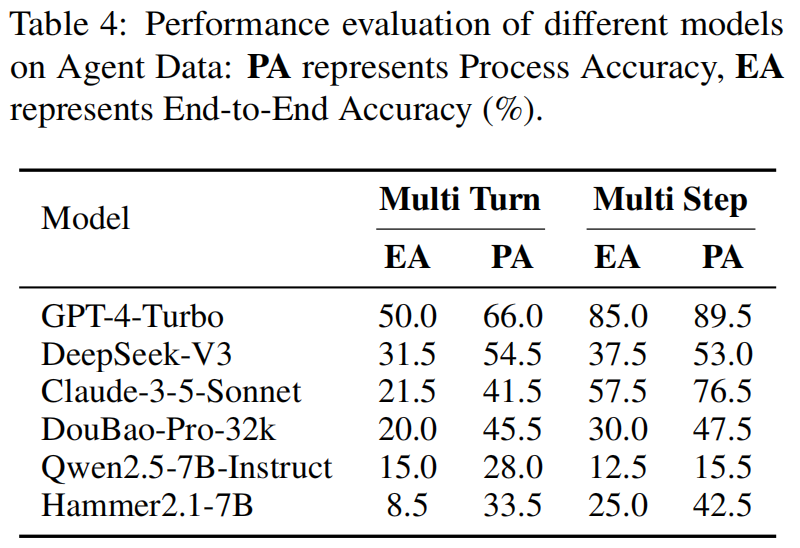
实验设置 (Experimental Setup) 在评估中,研究人员检验了七个闭源LLMs(closed-source LLMs),包括GPT-4系列、Qwen-Max、Gemini-1.5-Pro、Claude-3.5-Sonnet 和 Doubao-Pro-32K 。此外,还评估了多种开源语言模型(open-source language models),如Qwen2.5系列、Llama3系列、Phi-3-Mini、Deepseek-V3 和 DeepSeek-Coder-V2 。研究人员还评估了四种经过工具学习增强的模型(tool-learning-enhanced models):Hammer2.1-3B、Hammer2.1-7B、xLAM-7B-r 和 Watt-Tool-8B 。
4.1 Main results and analysis
中文和英文数据集的综合实验结果呈现在表2中 。研究人员可以得出以下重要结论:
- 模型性能的总体结论 (General Conclusion on Model Performance):
- 整体最佳性能仍然由闭源模型主导,例如GPT-4系列 。
- 然而,某些开源模型(如Qwen2.5-Coder-32B-Instruct、Qwen2.5-72B-Instruct 和 DeepSeek-V3)与闭源模型之间的性能差距正在逐渐缩小 。这一趋势表明,在模型架构和训练方法进步的推动下,开源模型正在稳步追赶闭源模型 。
- 微调模型的泛化能力丧失 (Loss of Generalization in Fine-Tuned Models):
- 如图3所示,针对特定数据集微调的模型,如Watt-Tool-8B、XLAM-7B 和 Hammer2.1-7B,在Special(特殊)数据集上的表现出现显著下降 。
- 这一下降主要归因于:微调虽然增强了模型在特定任务上的性能,但也可能导致泛化能力的丧失,使模型在新的或更广泛的指令遵循任务上效果不佳 。
- 大型模型在复杂任务中的性能局限 (Performance Limitations of Large Models in Complex Tasks):
- 如表4所示,大多数模型在Agent(代理)数据任务上的端到端准确率(end accuracy)低于50% 。
- 这归因于在模拟真实世界多轮互动的动态环境中完成此类任务,不仅需要执行单个工具操作 。模型还必须在工具使用过程中整合上下文信息,并考虑工具调用之间的相互依赖关系,这显著增加了任务复杂度 。
- 此外,这些任务需要高级的推理和适应能力,即使是大型模型也可能因为在长期交互中保持一致性以及响应任务演变性质的挑战而难以应对 。
4.2 Error Analysis
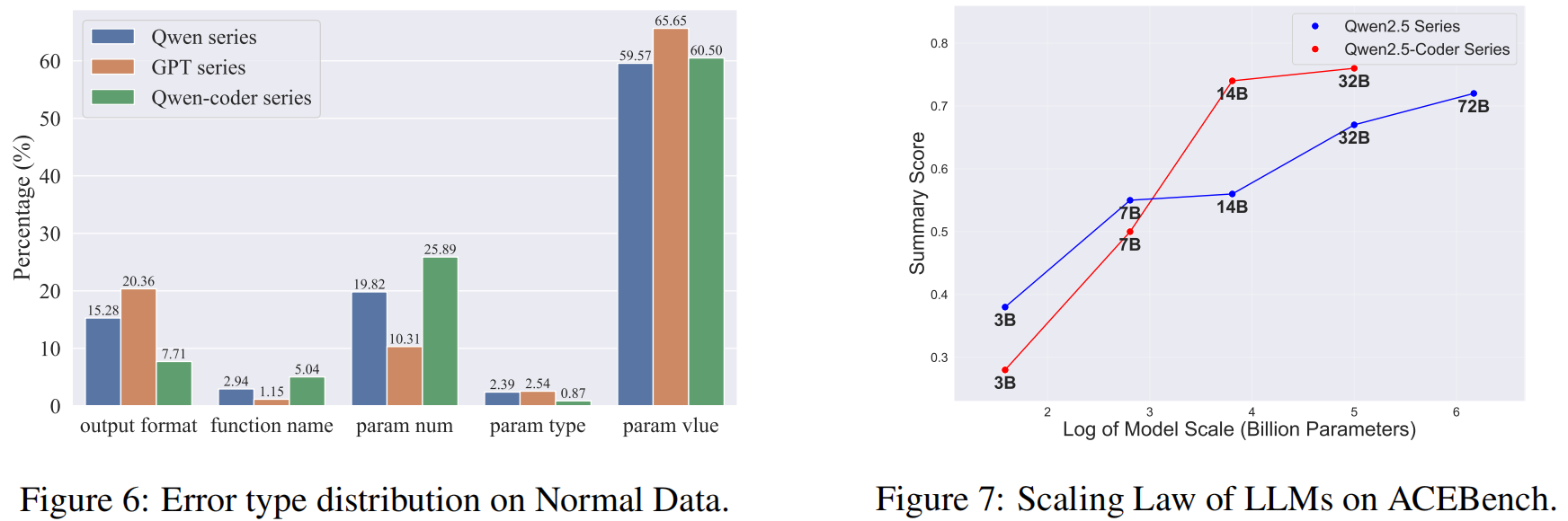
Normal 数据的错误分析:
- 如图6所示,从Normal数据上的错误类型分布来看,param value error (参数值错误) 在所有模型中占主导地位 。这凸显了模型在生成特定值方面的困难,可能是由于上下文理解有限和数值分布的复杂性 。
- Output format error (输出格式错误) 是第二大常见错误,表明在生成遵循预定义格式和句法规则的代码方面还有改进空间 。
- 相比之下,function name (函数名) 和 param type (参数类型) 错误较少,表明模型在匹配函数调用和处理数据类型方面表现出色 。
Special 数据的错误分析:
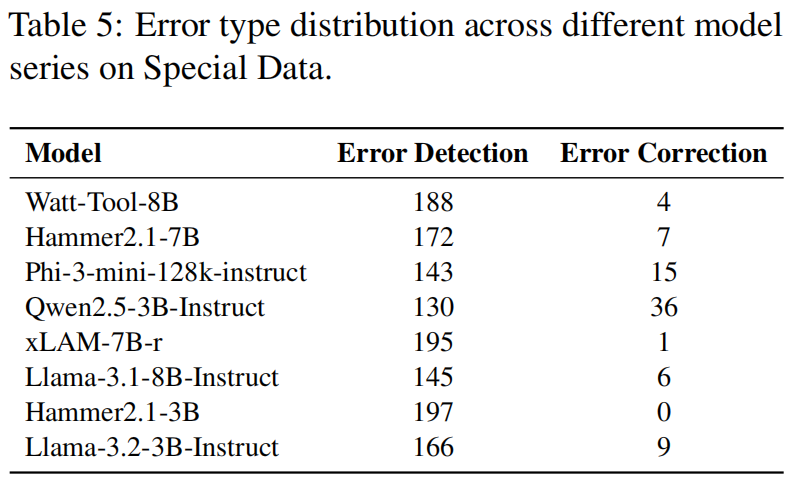
- 如表5所示,研究人员确定了两种主要的模型错误类型 :
- 第一种是 “Error Detection” (错误检测),指模型完全未能检测到用户指令中的问题,或者无法按照提示的格式要求识别问题 。
- 第二种是 “Error Correction” (错误纠正),即模型检测到了问题,但提供了不清晰的反馈 。例如,模型可能指出存在问题,但未具体说明哪个参数值不正确或缺少什么关键信息 。
- 结果显示,特殊类型场景中的大多数错误是由“错误检测”引起的 。
Agent 数据的错分析:
- 分析确定了三个主要的Agent错误原因 。
- 首先,函数调用错误 (function call errors):发生在模型未能选择适当的函数或未能提供符合规范的参数时 。
- 其次,违反规则 (rule violations):发生在模型无视预定义的场景规则,跳过必要步骤或破坏关键任务逻辑时 。
- 最后,信息管理不当 (information mismanagement):源于模型在多轮交互中无法正确记录或处理上下文信息,导致输出偏离预期 。
4.3 Further Analysis
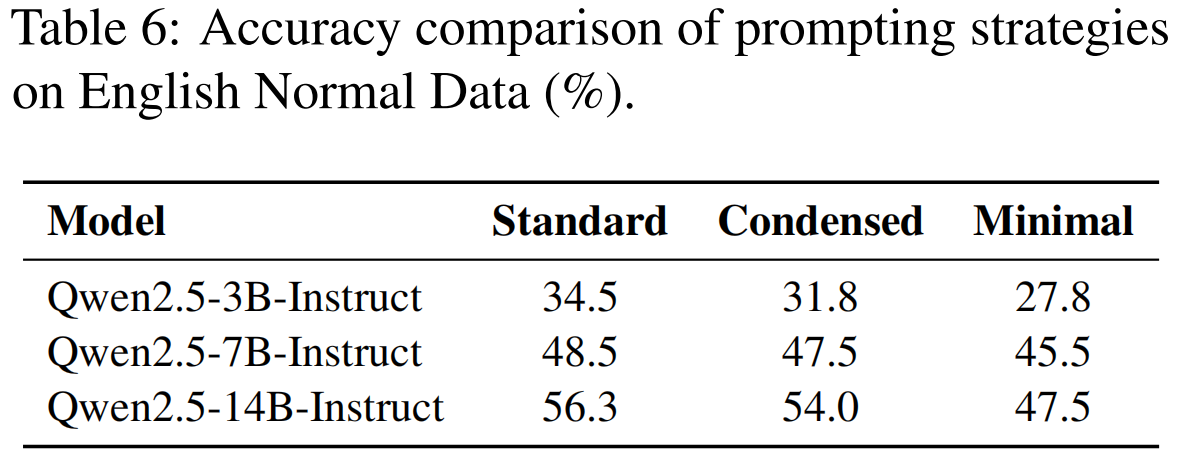
扩展法则 (Scaling Law):
- 研究人员评估了Qwen2.5-Coder(3B, 7B, 14B, 32B)和Qwen2.5-Instruct(3B, 7B, 14B, 32B, 72B)在ACEBench数据集上的性能 。
- 如图7所示,实验结果表明,随着模型规模(model size)的增加,性能在各种任务上都有显著提升,在复杂任务上观察到的结果尤其强劲 。
- 然而,值得注意的是,随着模型规模持续增大,性能提升的速率开始减慢,尤其是在32B和72B模型之间 。这表明,虽然增加模型参数最初会带来实质性的性能增益,但进一步扩展的边际效益会下降 。
提示策略的影响 (Impact of Prompting Strategies):
-
提示(Prompt)设计对语言模型性能有显著影响 。研究人员测试了三种策略 :
-
Standard Prompt (标准提示):一个旨在消除信息不足干扰的综合模板 。

-
Condensed Prompt (精简提示):保留核心指令的紧凑版本,测试在减少但足够指导下的性能 。

-
Minimal Prompt (最小提示):一种高度缩写的形式(例如关键词),评估模型从超简洁输入中推断任务的能力 。

-
-
表6中的实验结果表明,使用标准提示模板的模型获得了最高的总体准确率 。这归功于标准提示中严格的格式规范,有效减轻了无关变量的干扰 。
-
这些实证研究结果为未来的提示工程提供了关键见解:通过明确的格式要求来增强函数调用提示的标准化,可以显著提高执行准确性 。