
论文地址:From Automation to Autonomy:A Survey on Large Language Models in Scientific Discovery
论文实现:https://github.com/HKUST-KnowComp/Awesome-LLM-Scientific-Discovery
Awesome-LLM-Scientific-Discovery:Agent做科学发现综述
Abstract
大语言模型(LLMs)正在催化科学发现领域的范式转变,它们正从特定任务的自动化工具演变为日益自主的智能体(autonomous agents),并从根本上重新定义了研究过程以及人类与人工智能的协作方式 。
本综述系统地梳理了这一新兴领域,核心聚焦于 LLM 在科学领域中不断变化的角色以及持续提升的能力 。透过科学方法的视角,作者引入了一个基础的三级分类体系(three-level taxonomy)——即工具(Tool)、分析师(Analyst)和科学家(Scientist),以此来描绘 LLM 在研究生命周期中不断升级的自主性和不断演变的职责 。此外,文章还识别了关键的挑战和未来的研究轨迹,例如机器人自动化、自我改进以及伦理治理 。
总体而言,本综述提供了一个概念架构和战略远见,以引导和塑造 AI 驱动的科学发现的未来,旨在同时促进快速创新和负责任的进步 。
1 Introduction
1. 研究背景:能力的融合与范式转变
大语言模型(LLMs)的持续进步解锁了一系列涌现能力(emergent abilities),例如规划、复杂推理和指令遵循 。此外,集成智能体工作流(agentic workflows)使得基于 LLM 的系统能够执行高级功能,包括网页导航、工具使用、代码执行和数据分析 。
在科学发现领域,这种先进的 LLM 能力与智能体功能的融合正在催化一场重大的范式转变(paradigm shift) 。这一转变不仅有望加速研究生命周期,还将从根本上改变人类研究人员与人工智能在追求知识过程中的协作动态 。
2. 现有挑战与研究空白
然而,LLM 应用的快速扩展和科学发现范式的转变带来了显著挑战。LLM 演进速度之快及其在复杂研究中集成的加深,使得系统性评估变得复杂,因此需要概念框架来梳理当前的理解并规划未来方向 。
作者指出,现有的综述虽然提供了各个科学领域中 LLM 的概览,或者罗列了特定的科学 AI 技术,但它们通常局限于:
- 特定学科的应用;
- 或者仅仅是 LLM 能力的静态快照 。
因此,现有综述往往忽视了LLM 自主性不断增强(increasing LLM autonomy)这一关键趋势,也没有探讨它们在整个科学方法论中不断演变的角色,导致对它们迈向更高独立性的全面影响和轨迹探索不足 。
3. 本文的方法论框架
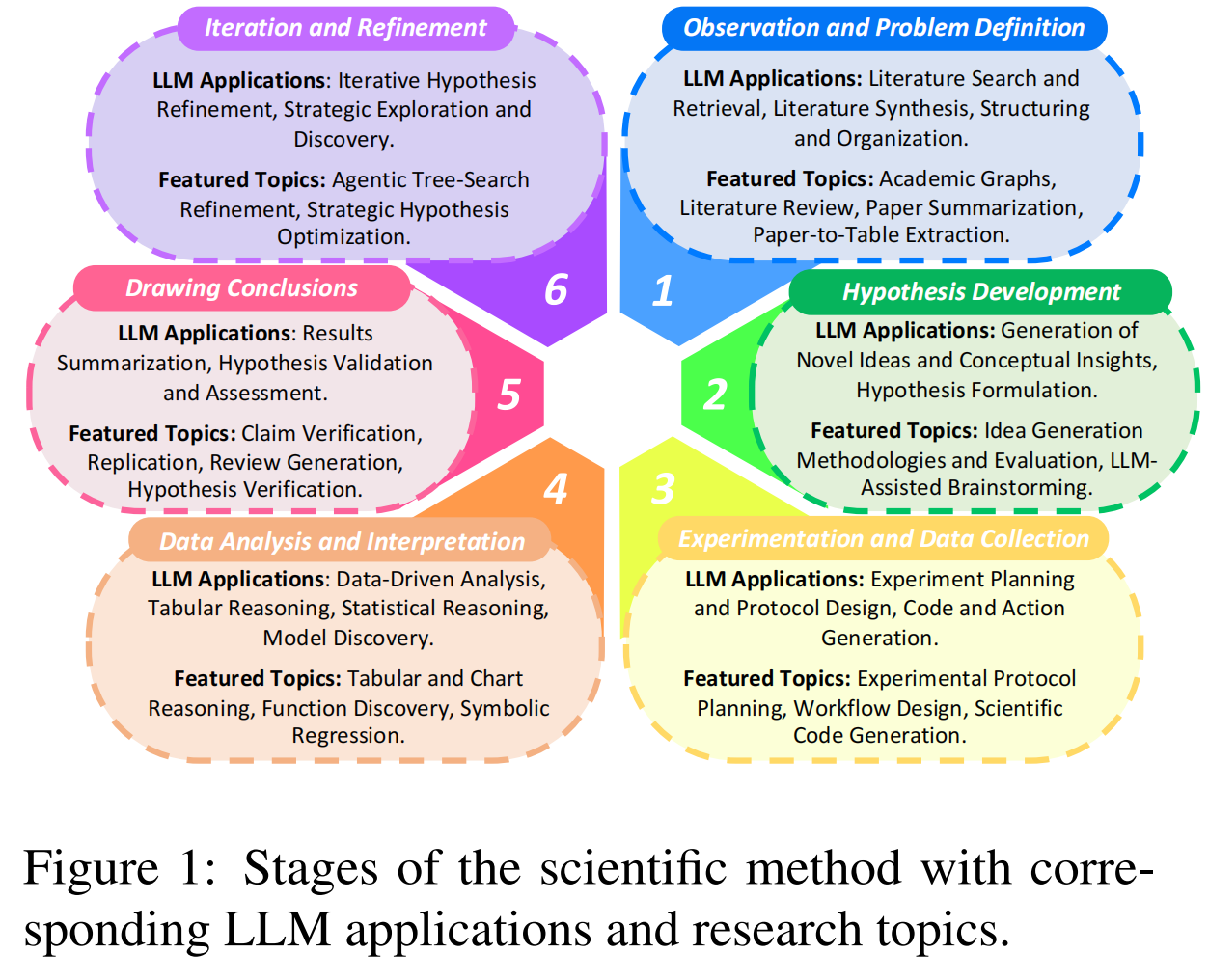
为了系统地描绘这一演变的图景并填补上述空白,作者将分析锚定在既定的科学方法(Scientific Method)的六个阶段上(如图 1 所示):
- 观察与问题定义 (Observation and Problem Definition)
- 假设发展 (Hypothesis Development)
- 实验与数据收集 (Experimentation and Data Collection)
- 数据分析与解释 (Data Analysis and Interpretation)
- 得出结论 (Drawing Conclusions)
- 迭代与优化 (Iteration and Refinement)
Figure 1 展示了这六个阶段以及对应的 LLM 应用和研究主题 。
4. 核心贡献:三级自主性分类体系
作者通过对这六个阶段中 LLM 应用的考察,揭示了一个显著趋势:LLM 正从在单一阶段执行离散的任务导向型功能,发展为部署在复杂的多阶段智能体工作流中 。
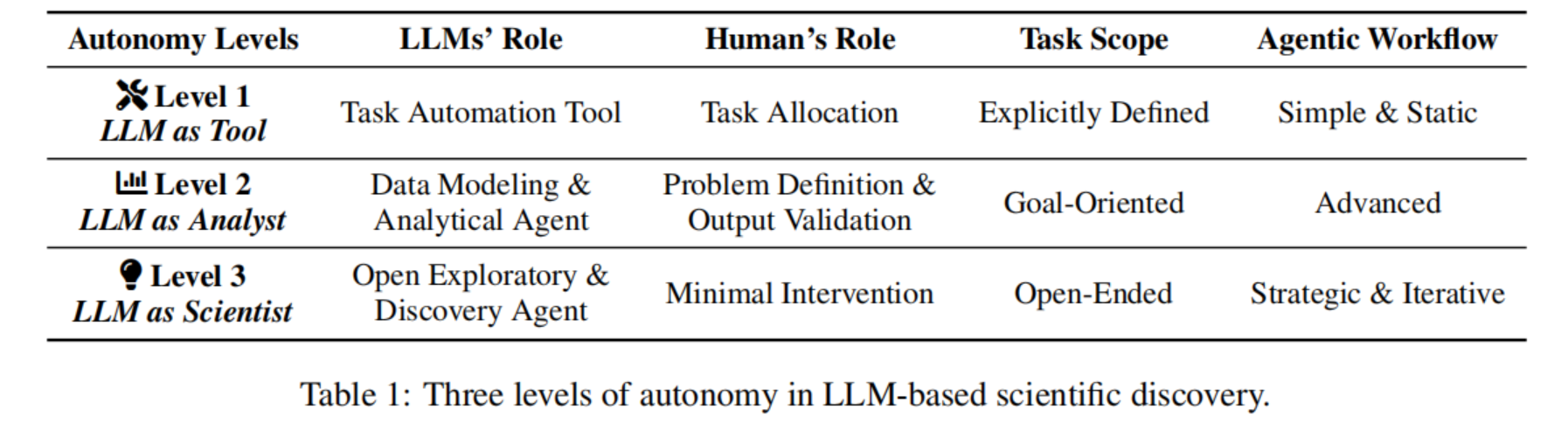
为了有效地捕捉和通过层级划分这种不断增长的能力和独立性,作者提出了一个用于科学发现中 LLM 参与度的基础三级分类体系(Three-level Taxonomy)(如 Table 1 所示):
- Level 1: LLM as Tool(LLM 作为工具): 在此层级,模型作为工具增强人类研究人员的能力,在直接监督下执行特定的、定义明确的任务 。
- Level 2: LLM as Analyst(LLM 作为分析师): 在此层级,模型展现出更高的自主性,能够处理复杂信息、进行分析并提供见解,且减少了人类干预 。
- Level 3: LLM as Scientist(LLM 作为科学家): 代表了一个更高级的阶段,基于 LLM 的系统可以自主地进行主要的研究阶段,从提出假设到解释结果,并建议新的探索途径 。
Table 1 详细对比了这三个自主性等级在角色、人类干预程度、任务范围和工作流类型上的区别 。
5. 关键挑战与未来轨迹
基于这一分类框架,作者进一步识别了当前研究景观中的关键差距,并强调了该领域的关键挑战和未来轨迹 :
- 全自主发现循环(Fully autonomous discovery cycles):无需人类干预即可进行演进式的科学探究。
- 机器人自动化(Robotic automation):在物理世界中进行实验室实验的交互。
- 持续自我改进(Continuous self-improvement):从过往的研究经验中学习和适应。
- 透明度与可解释性(Transparency and interpretability):针对 LLM 进行的研究过程。
- 伦理治理与社会对齐(Ethical governance and societal alignment)。
6. 论文范围界定
作者明确指出,本综述聚焦于科学发现中基于 LLM 的系统,特别是它们不同程度的自主性 。为了保持聚焦,作者有意缩小了范围,排除了关于通用科学 LLM(general-purpose scientific LLMs)或用于特定领域科学知识获取与推理的 LLM 的研究,因为这些内容在现有的综述中已有很好的覆盖。
2 Three Levels of Autonomy
这一部分的核心在于详细讨论基于 LLM 的科学发现中的三个自主性层级。Table 1 展示了这三个层级及其相关特征(如 LLM 的角色、人类的角色、任务范围和智能体工作流的复杂性)。
Level 1: LLM as Tool(LLM 作为工具)
这是 LLM 在科学发现中最基础的应用层级 。
- 角色与功能:在此阶段,LLM 主要作为在人类直接监督下的定制工具(tailored tools)运行 。它们被设计用于执行科学方法中单一阶段内的、具体的、定义明确的任务 。
- 增强人类能力:其作用是通过自动化或加速离散的活动来增强人类能力 。典型的任务包括文献总结、起草手稿初稿、生成用于数据处理的代码片段或重新格式化数据集 。
- 自主性限制:此层级的自主性有限;它们基于明确的人类提示(prompts)和指令运行 。其输出通常需要人类进行验证并整合到更广泛的研究工作流中 。
- 目标:主要目标是提高研究人员的效率并减轻常规任务的负担 。
Level 2: LLM as Analyst(LLM 作为分析师)
在 Level 2 中,LLM 展现出更高程度的自主性,超越了纯粹静态的任务导向型应用 。
- 角色与功能:此时,LLM 作为被动智能体(passive agents)发挥作用 。它们能够进行更复杂的信息处理、数据建模和分析推理,且在中间步骤中减少了人类干预 。
- 任务管理:虽然仍主要在人类研究人员设定的边界内运行,但这些系统可以独立管理任务序列 。例如,分析实验数据集以识别趋势、解释复杂模拟的输出,甚至执行模型的迭代优化 。
- 人类交互:人类研究人员通常负责定义整体分析目标、提供必要的数据,并批判性地评估 LLM 生成的见解或解释 。
Level 3: LLM as Scientist(LLM 作为科学家)
Level 3 的应用标志着自主性的重大飞跃 。
- 角色与功能:基于 LLM 的系统作为主动智能体(active agents)运行,能够编排并引导科学发现过程中的多个阶段,具有相当大的独立性 。
- 主动性与全流程:这些系统能够展现出主动性,包括提出假设、规划和执行实验、分析结果数据、得出初步结论,并潜在地提出后续的研究问题或探索途径 。
- 极少的人类干预:处于此层级的 LLM 系统可以驱动研究周期的主要部分,在极少人类干预的情况下进行科学发现 。
研究全景图 (Figure 2)
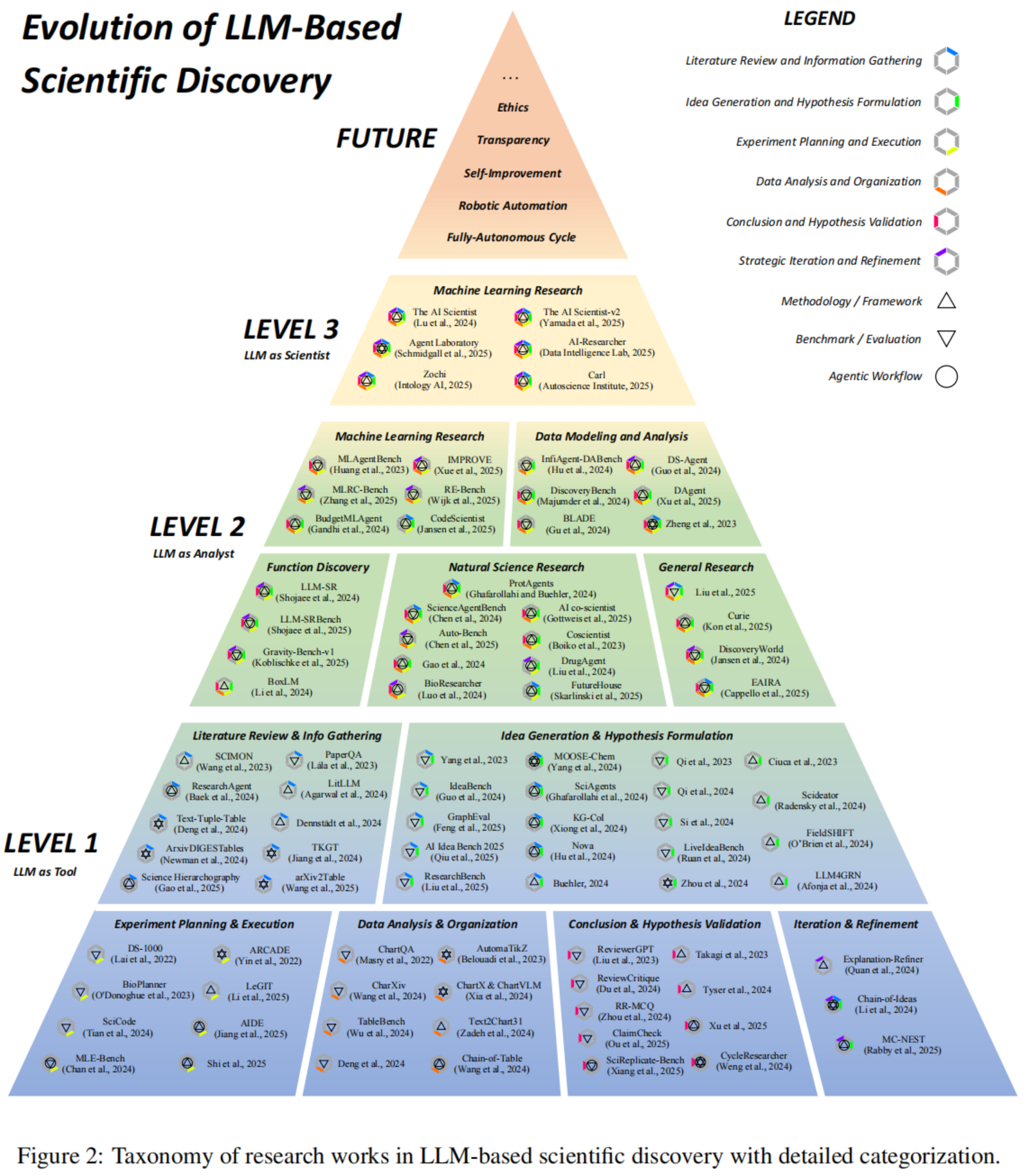
作者在 Figure 2 中展示了完整的分类体系和详细的归类,该图汇总了这三个自主性层级内的具体研究工作,涵盖了从文献回顾、假设生成到实验规划等各个科学发现阶段。
3 Level 1. LLM as Tool (Table A1)
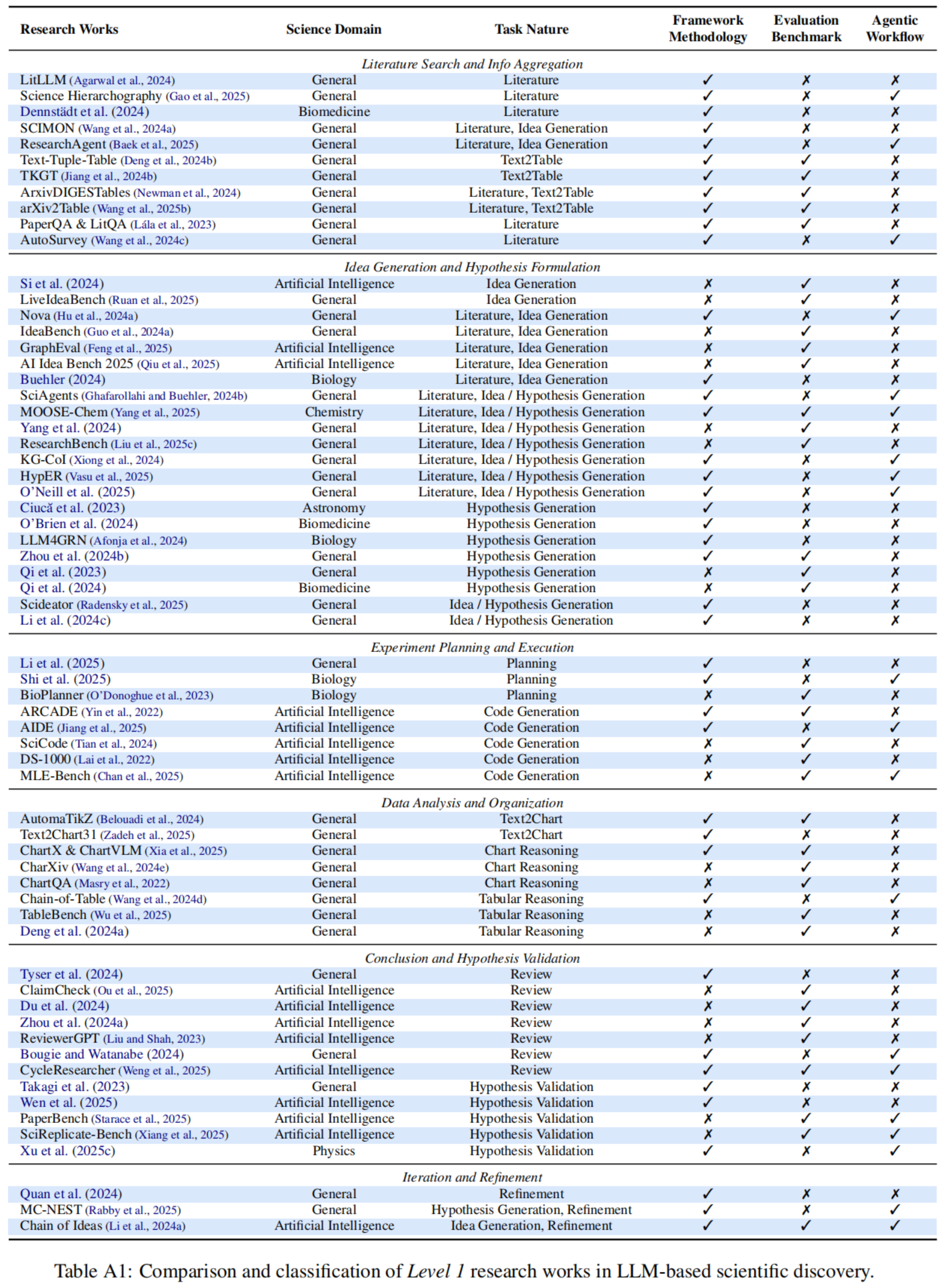
作者在 Table A1(位于原文第 17 页)中对这些 Level 1 的研究工作进行了详细的比较和分类 。
3.1 文献回顾与信息收集 (Literature Review and Information Gathering)
- 文献综述 (Literature Review):
- 自动化的文献搜索和检索对于识别研究空白至关重要。PaperQA (基于 LitQA 基准测试) 引入了基于 RAG(检索增强生成)的智能体 。
- LitLLM 提供了用于 LLM 驱动的文献综述的综合 RAG 工具包 。
- Wang 等人 (2024c) 进一步展示了 LLM 可以自动撰写整个综述论文 (Survey papers) 。
- 在生物医学领域,Dennstädt 等人 (2024) 强调了 LLM 在文献筛选中的潜力 。
- 近期的“深度研究”产品(如 OpenAI, Google, xAI 的产品)通过增强的智能体工作流,显著加速了传统的文献研究过程 。
- 信息聚合 (Information Aggregation):
- 研究聚焦于将论文信息聚合并转化为表格摘要。ArxivDIGESTables 探索了跨文献的表格生成 。
- ArXiv2Table 提供了综合基准测试 。
- Text-Tuple-Table 和 TKGT 等方法通过引入基于元组的结构和图模态,提高了表格生成的质量 。
3.2 想法生成与假设构建 (Idea Generation and Hypothesis Formulation)
- 想法生成 (Idea Generation):
- IdeaBench 和 LiveIdeaBench 等基准测试评估了 LLM 基于文献摘要生成研究想法的能力 。
- Nova、SciAgents 和 KG-Col 等智能体框架旨在通过在学术知识图谱上的推理、迭代规划来增强想法生成 。
- 在特定领域,例如天文学(对抗性提示)和生物学(知识提取与图表示),也进行了针对性的探索 。
- 假设构建 (Hypothesis Formulation):
- 重点在于设计可测试的科学假设。Qi 等人 (2023) 和 Yang 等人 (2024) 证明了 LLM 在开放式约束下提出新颖且有效假设的能力 。
- Scideator 旨在促进人类与 LLM 协作以生成有依据的想法 。
- HypER 专注于生成有明确出处(provenance)、基于文献的假设 。
- 在化学领域,MOOSE-Chem 提供了专门用于假设发现的评估基准和框架 。
3.3 实验规划与执行 (Experiment Planning and Execution)
- 规划 (Planning):
- Li 等人 (2025) 讨论了 LLM 在因果发现实验设计中的有效性 。
- BioPlanner 引入了一个自动化评估框架,用于评估 LLM 在生物学协议规划(protocol planning)中的表现 。
- Shi 等人 (2025) 提出了分层封装表示法以辅助生物协议设计 。
- 执行 (Execution):
- 主要集中在代码生成,特别是针对 AI 研究。
- 早期基准测试如 ARCADE 和 DS-1000 关注数据科学任务 。
- 后续工作如 MLE-Bench 和 SciCode 引入了更具挑战性的现实场景(如机器学习工程和自然科学研究)。
- AIDE 提出采用树搜索(tree-search)方法进行代码优化,以增强复杂代码生成能力 。
3.4 数据分析与组织 (Data Analysis and Organization)
在此阶段,LLM 协助自动化数据组织、展示和分析。
- 表格数据 (Tabular Data):
- Chain-of-Table 提出将演变的表格纳入推理链,以增强表格理解 。
- TableBench 引入了工业场景下基于表格的问答基准测试 。
- 图表数据 (Chart Data):
- ChartQA 考察了视觉 Transformer 在图表问答中的能力 。
- CharXiv 和 ChartX 利用 arXiv 预印本中的真实图表数据扩展了理解场景 。
- 在图表生成方面,AutomaTikZ 将过程公式化为从文本生成 TikZ 代码 。Text2Chart31 利用强化学习和自动反馈来优化 Matplotlib 图表的生成 。
3.5 结论与假设验证 (Conclusion and Hypothesis Validation)
LLM 可用于提供反馈、验证实验得出的主张和结论。
- 论文评审 (Paper Review):
- ReviewerGPT 初步探索了 LLM 识别论文中故意插入错误的能力 。
- Du 等人 (2024) 的综合分析揭示了 LLM 在识别缺陷方面的弱点 。
- ClaimCheck 进一步调查了 LLM 批判研究主张的能力,发现这即便对高级模型(如 OpenAI o1)也是挑战 。
- XtraGPT 等系统实现了人机协作进行可控的论文修改 。
- 假设验证 (Hypothesis Validation):
- Takagi 等人 (2023) 展示了 LLM 自动生成代码以验证机器学习假设的能力 。
- SciReplicate-Bench 和 PaperBench 将这一概念扩展到了对真实研究论文的复现评估 。
- 还有研究探索利用语言模型直接预测实证 AI 研究的结果 。
3.6 迭代与优化 (Iteration and Refinement)
这一领域目前的关注相对较少 。
- Explanation-Refiner 利用定理证明器来验证并改进 LLM 生成的假设 。
- Chain-of-Idea 引入了一个基于 LLM 的智能体框架,通过在现有研究线索上构建或扩展来组织文献并发展研究想法 。
- MC-NEST 采用蒙特卡洛树搜索(Monte-Carlo Tree Search)来迭代地验证和优化跨多个研究领域的科学假设 。
4 Level 2: LLM as Analyst (Table A2)
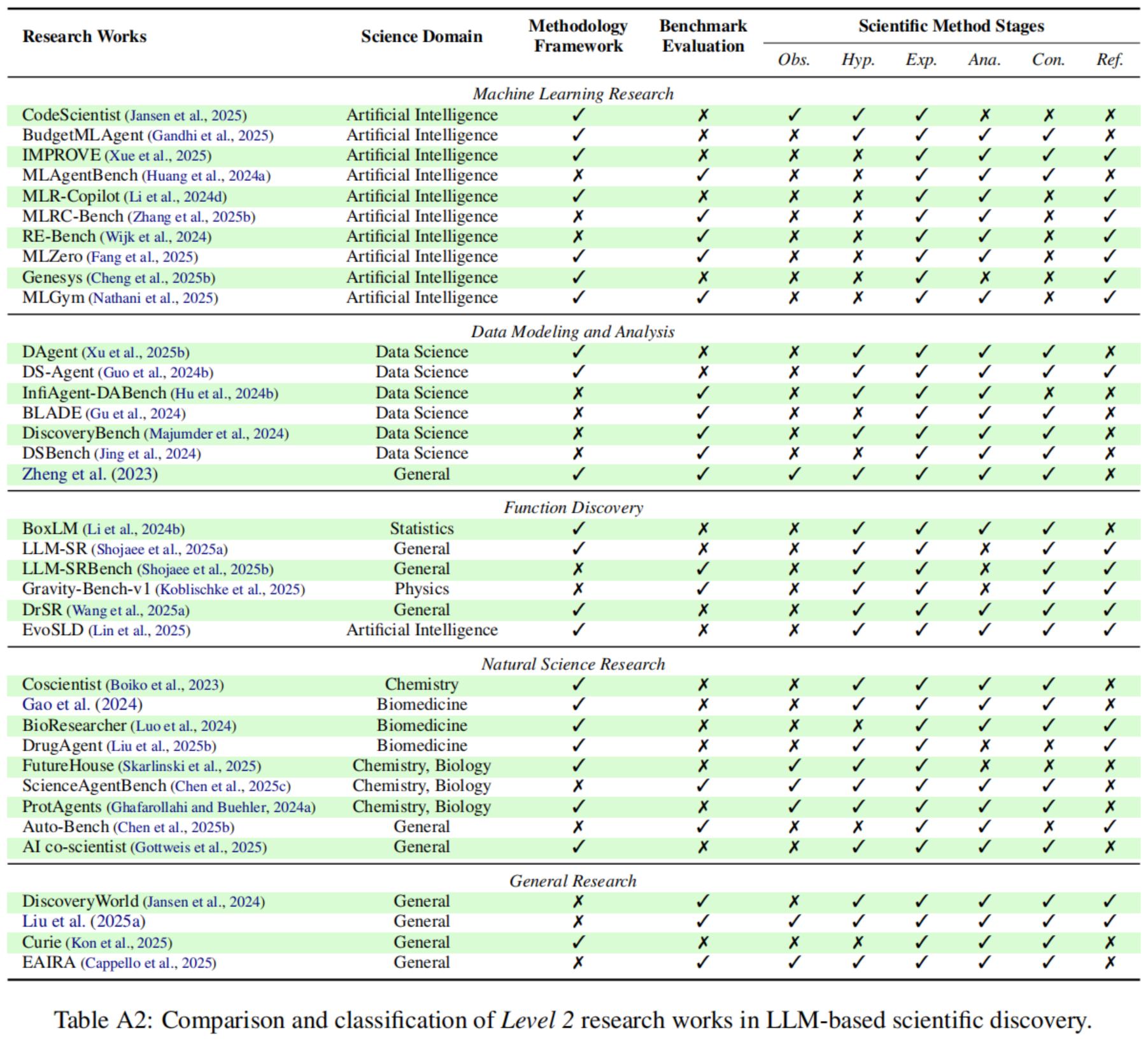
作者在 Table A2(位于原文第 18 页)中对这些 Level 2 的研究工作进行了详细的比较和分类 。
4.1 机器学习研究 (Machine Learning Research)
自动化机器学习(AutoML)致力于以数据驱动的方式生成高性能的模型配置 。随着基于 LLM 的智能体的出现,多项研究探索了其在 ML 任务自动化建模中的应用:
- 基准测试 (Benchmarks):
- MLAgentBench 评估了 LLM 设计和执行 ML 实验的能力,发现其表现通常取决于对任务的熟悉程度 。
- MLRC-Bench 和 RE-Bench 进一步探索了智能体的极限,评估其解决新颖 ML 研究挑战的能力,并将研发能力与人类专家进行对比 。
- MLGym 为推进这些 AI 研究智能体提供了宝贵的资源和基准 。
- 智能体框架 (Agentic Frameworks):
- IMPROVE 框架强调了迭代优化机制的重要性 。
- CodeScientist 将 ML 建模智能体与机器生成的想法相结合 。
- BudgetMLAgent 利用精心策划的专家协作框架,以低成本模型实现了卓越的结果 。
- 端到端系统与架构设计:
- 更近期的系统如 MLR-Copilot 和多智能体框架 MLZero 旨在实现全自主的机器学习研究和自动化 。
- 一些工作甚至探索了使用语言模型直接提出语言模型(LM)架构(如 Genesys / Cheng et al.),超越了单纯的编排,转向直接的模型创造 。
4.2 数据建模与分析 (Data Modeling and Analysis)
自动化的数据驱动分析(包括统计数据建模和假设验证)是 LLM 辅助科学发现的一个基础应用领域 。
- 基准测试:
- InfiAgent-DABench 对 LLM 在使用 CSV 文件进行数据分析时的静态代码生成和执行能力进行了基准测试 。
- 后续的基准测试,如 BLADE、DiscoveryBench 和 DSBench,通过纳入现实世界的研究论文和专家策划的分析,提高了评估的鲁棒性,以评估智能体与人类专家表现之间的差距 。
- 这些研究表明,大多数 LLM 即使在智能体框架内运行,在处理复杂数据分析任务时仍面临困难 。
- 解决方案:
- DS-Agent 提出通过结合基于案例的推理方法(case-based reasoning)来改进领域知识获取,从而提升 LLM 的性能 。
- DAgent 将应用领域扩展到查询关系数据库,并支持使用分解子问题得出的结果生成报告 。
4.3 函数发现 (Function Discovery)
函数发现旨在从变量的观测数据中识别潜在方程,AI 驱动的符号回归(SR)的进步对此产生了显著影响 。
- 方法论:
- LLM-SR 利用 LLM 的先验领域知识,并结合来自聚类记忆存储的反馈来增强这一过程 。
- DrSR 提出了一种双重推理框架(dual reasoning framework),利用数据和经验进行科学方程发现 。
- 基准测试:
- LLM-SRBench 引入了一个评估 LLM 作为函数发现智能体的基准,其中包含函数变换以减轻数据污染问题 。
- 特定领域应用:
- 研究还探索了 LLM 在特定领域发现复杂模型的能力,例如物理学(Gravity-Bench-v1 / Koblischke et al.)、统计学(Li et al.)以及自动化神经缩放定律发现(EvoSLD / Lin et al.) 。
4.4 自然科学研究 (Natural Science Research)
研究主要集中在将 LLM 应用于自然科学发现的自主研究工作流中 。
- 综合评估:
- Auto-Bench 基于因果图发现评估了 LLM 在化学和社会科学任务上的表现,揭示了 LLM 仅在任务复杂度非常有限时才有效 。
- ScienceAgentBench 为在智能体框架(如 CodeAct 和 self-debug)内运行的 LLM 提供了多学科基准测试,强调了此类探索性任务需要量身定制的智能体工作流 。
- 生物医学与化学:
- BioResearcher 提出了一个涉及干湿实验(dry lab experiments)的生物医学研究端到端框架 。
- DrugAgent 采用多智能体协作来自动化药物发现 。
- 在化学领域,Coscientist 结合 LLM 的工具使用,支持半自主的化学实验设计和执行 。
- ProtAgents 通过构建用于自动化蛋白质设计的多智能体框架,促进了生物化学发现 。
- 前沿进展:
- 近期的工作如 FutureHouse 和 AI Co-scientist,致力于使用由预定义研究目标指导的多智能体系统,以此制定经证实新颖的研究假设和提案 。
4.5 通用研究 (General Research)
除了特定领域的应用,一些基准测试广泛评估了科学发现不同阶段的多样化任务 。
- Discovery World 创建了一个虚拟环境,供 LLM 智能体进行简化的科学探索 。
- Liu 等人 (2025a) 全面讨论了 AI 智能体在研究中的各种应用场景,并提供了初步评估数据集 。
- CURIE 提出了一个用于严格和自动化科学实验的基准和智能体框架 。
- EAIRA 专注于评估 LLM 使用各种任务格式扮演现实世界研究助手角色的能力 。
5 Level 3. LLM as Scientist (Table A3)
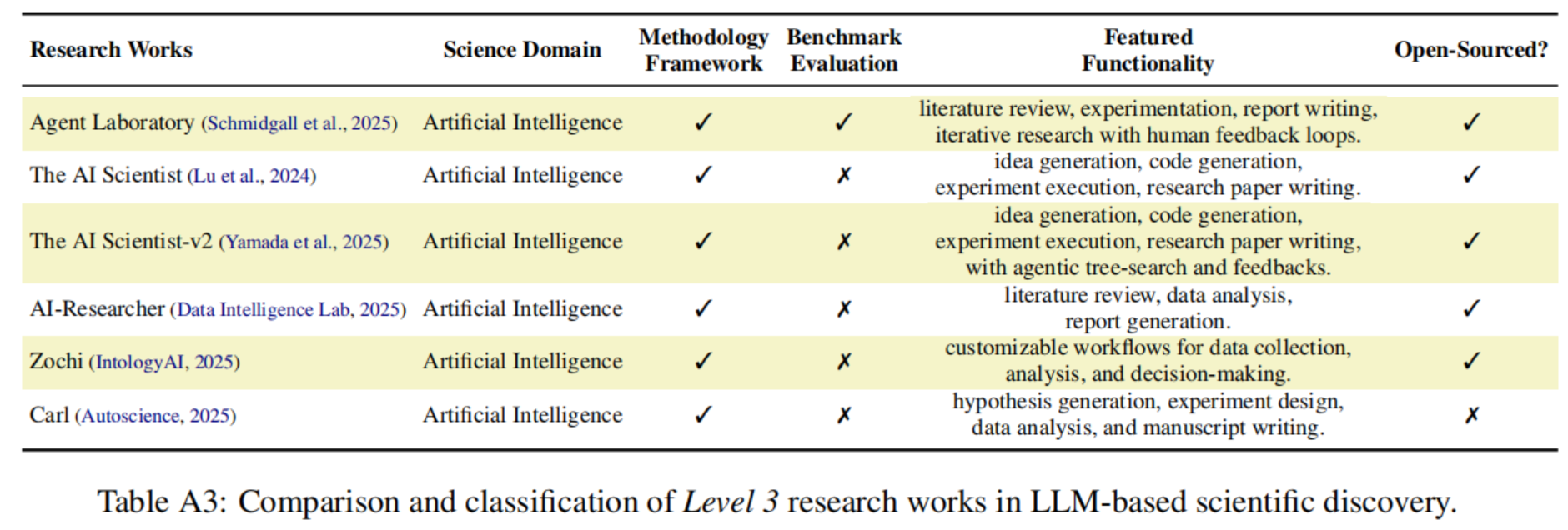
作者在 Table A3(位于原文第 18 页)中对这些 Level 3 的研究工作进行了详细的比较和分类。
概览
近期,若干研究工作和商业产品展示了在人工智能领域内进行全自主研究(fully autonomous research)的原型 。
- 全流程覆盖:这些系统通常包含一个全面的工作流,从最初的文献综述到迭代的优化循环,逐步改进假设或设计,直至最终产出研究论文草稿 。
- 智能体框架:一个共同特征是使用基于智能体(agent-based)的框架来自主生产研究成果。
本部分重点比较了这些方法在想法发展(Idea Development)和迭代优化(Iterative Refinement)方面的策略,因为这两个方面是将它们与 Level 2 智能体区分开来的关键。
5.1 想法发展 (Idea Development)
Level 3 系统中研究的起源涉及将初始概念转化为经过验证的假设,不同系统在获取和审查这些想法的方式上存在显著差异 。
- 基于人类目标的文献综述:
- Agent Laboratory (Schmidgall et al., 2025) 主要基于人类定义的具体研究目标来进行文献综述 。
- 更高的自主性与差距识别:
- 一些系统正朝着更高的自主性发展,从更宽泛的人类输入开始。例如 AI-Researcher (Data Intelligence Lab, 2025) 和 Carl (Autoscience, 2025) 从参考论文出发,或者 Zochi (IntologyAI, 2025) 从一般研究领域出发,随后的过程是自主探索文献以识别研究空白并构建新颖假设 。
- 生成式方法:
- The AI Scientist (v1 和 v2 ) 展示了一种更具生成式的方法:v1 从模板和过往工作中头脑风暴想法,而 v2 能够从抽象的主题提示中生成多样化的研究提案
- 想法验证:
- 至关重要的是,这些系统在全面实施之前采用了多种方法来评估其想法。
- AI Scientis-v1 使用自我评估分数(有趣性、新颖性、可行性),并辅以 Semantic Scholar 的外部检查 。
- AI Scientist-v2 在想法构建阶段的早期就集成了文献综述工具以评估新颖性 。
趋势:虽然通常仍由人类发起想法,但先进系统能够自主探索、生成并在开发前验证研究目标的科学价值和原创性 。
5.2 迭代与优化 (Iterative Refinement)
Level 3 系统中的迭代优化涉及复杂的反馈循环(feedback loops),这不仅能实现增量改进,还能对研究轨迹进行根本性的重新评估 。关键的区别在于这种高层反馈的主要来源和性质。
- 全自动内部评审:
- The AI Scientist (v1 和 v2) 整合了高度自动化的内部评审和优化流程。它利用 AI 审稿人、针对实验选择的 LLM 评估器以及用于批评图表的视觉语言模型(VLMs),构建了一个丰富的内部反馈循环以进行迭代开发 。
- 人机协同的宏观指导:
- 相比之下,Zochi (Intology AI, 2025) 集成了人类专家的宏观指导。这种反馈可以触发对假设或设计的全面重新评估 。这使得系统能够针对挑战核心研究前提的批评采取行动,如果结果不令人满意,甚至可以退回到假设生成阶段 。
总结:虽然自动自我纠正是一个共同目标,但目前的格局显示了一种务实的融合:一些系统专注于增强自主的深度反思(autonomous deep reflection),而另一些系统则整合人类监督(human oversight)以实现稳健的高层迭代优化和战略重定向 。
Table A3: Level 3 研究工作对比 (Table A3)
Table A3 详细列出并对比了主要的 Level 3 研究工作,包括:
- Agent Laboratory
- The AI Scientist (v1 & v2)
- AI-Researcher
- Zochi
- Carl (Autoscience)
表格从以下维度进行了分类:
- 科学领域:目前主要集中在人工智能(Artificial Intelligence)领域。
- 特色功能:例如文献综述、代码生成、实验执行、研究论文写作、带有反馈的智能体树搜索(agentic tree-search)等。
- 开源情况:部分项目如 The AI Scientist 和 AI-Researcher 是开源的,而 Zochi 和 Carl 目前并未标记为开源。
6 Challenges and Future Directions
在系统性地回顾了 LLM 从基础助手(Level 1)进化为自主研究者(Level 3)的历程后,作者在这一章节超越了对现有技术的总结,指出了阻碍进一步发展的五大关键挑战,并描绘了未来的研究蓝图。
1. 全自主研究循环 (Fully-Autonomous Research Cycle)
- 当前局限:目前的 Level 3 系统(LLM as Scientist)虽然能够针对特定的询问导航科学方法的多个阶段,但它们通常在一个单一的研究实例或预定义的主题内运作 。
- 科学的本质:科学方法本质上是循环的(cyclical),其特征在于持续的迭代、改进以及对不断演变的研究问题的追求 。
- 未来方向:未来的发展方向是开发能够参与真正自主研究循环的 LLM 系统。
- 这不仅意味着从头到尾执行一个给定的研究任务;
- 更意味着系统需要具备远见(foresight),能够洞察其发现的广泛影响,主动识别有前景的后续调查途径,并战略性地指导其努力方向,以在通过前人工作的基础上实现实际的进步 。
2. 机器人自动化 (Robotic Automation)
- 物理障碍:实现自然科学领域全自主科学发现的一个关键障碍是 LLM 智能体无法进行物理实验室实验。它们虽然擅长计算研究,但在需要物理交互的领域(如湿实验)应用受限 。
- 解决方案:将 LLM 与机器人系统(robotic systems)集成,使其能够将规划能力转化为直接的实验行动 。
- 潜力领域:早期的 LLM 与机器人集成工作(如化学实验)已经突显了这一潜力。这种自动化有望显著拓宽基于 LLM 的研究范围,在化学和材料科学等学科中实现端到端的发现 。
3. 透明度与可解释性 (Transparency and Interpretability)
- 黑盒问题:LLM 的“黑盒”性质(或不透明性)破坏了科学验证、信任以及对 AI 驱动的见解的吸收 。
- 超越 XAI:解决这一问题需要的不仅仅是肤浅的可解释 AI(Explainable AI, XAI)技术。它需要一种范式转变,即系统的内部操作在设计上本质上就是为了进行可验证的推理(verifiable reasoning)和可辩护的结论(justifiable conclusions) 。
- 核心挑战:挑战不仅在于解释输出,更在于确保 AI 的内部逻辑符合科学原则,并能可靠地区分“断言的主张(asserted claims)”与“可验证的真理(verifiable truths)”。这种深刻的可解释性对于可靠和可复现的 LLM 科学发现至关重要 。
4. 持续自我改进 (Continuous Self-Improvement)
- 适应性需求:科学探究的迭代和演变性质要求系统能够从持续的参与中学习,吸收实验结果,并调整研究策略 。
- 技术路径:目前结合持续学习(continual learning)与智能体系统的研究已经显示了适应新任务而不发生“灾难性遗忘”的潜力。
- 未来展望:一个有前景的方向是整合在线强化学习框架(online reinforcement learning frameworks)。这将使科学智能体能够在整个生命周期中通过连续的发现不断增强自身能力,从而推动可持续的自主探索 。
5. 伦理与社会对齐 (Ethics and Societal Alignment)
- 风险升级:随着 LLM 系统获得独立的推理和行动能力,潜在的风险——从放大的社会偏见到蓄意的滥用(如生成有害物质或挑战人类控制)——变得日益显著和复杂 。
- 持续对齐:由于 AI 能力和社会规范处于不断变化之中,对齐(Alignment)必须是一个持续的过程,需要适应性的治理和不断演变的价值体系 。
- 治理要求:这要求将伦理约束直接嵌入到科学 AI 的设计框架中,并配合警惕的监督,以确保技术进步服务于人类福祉和公共利益 。