
论文地址:SciToolAgent:A Knowledge Graph-Driven Scientific Agent for Multi-Tool Integration
SciToolAgent:LLM+工具图谱做科学agent
Abstract
专业的计算工具越来越多,但使用门槛很高,而现有的大型语言模型(LLMs)难以将多个工具整合起来解决复杂的科学问题 。为应对这一挑战,研究者们提出了 SciToolAgent,一个由大型语言模型驱动的智能体,它能够自动化整合和操作涵盖生物学、化学和材料科学领域的数百个科学工具 。
- 它利用一个科学工具知识图谱(scientific tool knowledge graph),通过基于图的检索增强生成技术,来实现对工具的智能选择与执行 。
- 它集成了一个全面的安全检查模块,以确保工具的使用是负责任且符合伦理的 。
最后,摘要总结了该工作的成果:通过在一个专门构建的基准上进行的大量评估,证明了 SciToolAgent 的性能超越了现有方法 。并通过在蛋白质工程、化学反应活性预测、化学合成以及金属有机框架筛选等多个领域的案例研究,进一步展示了其自动化复杂科学工作流的强大能力,最终目标是让前沿的科研工具能被更广泛的专家和非专家所使用 。
1 Introduction
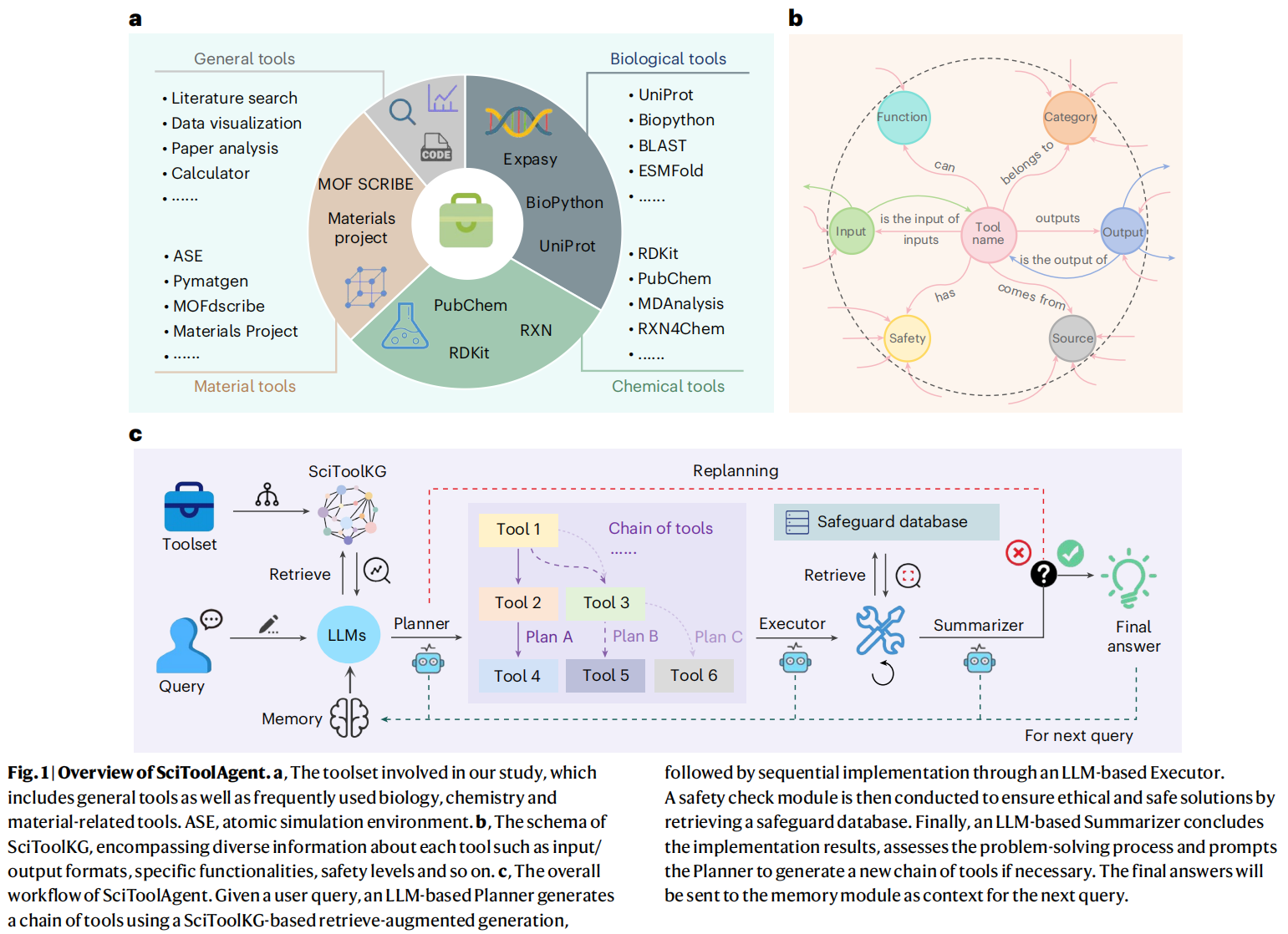
当代科学研究越来越依赖于专业的计算工具,这些工具能将从数据分析到结果可视化等关键任务自动化 。然而,尽管这些工具对推动科学发现至关重要,但它们日益增长的复杂性和多样性也为研究人员,特别是初学者,设置了巨大的使用障碍 。例如,化学家们会常规使用特定的工具进行分子模拟或属性预测 。缺乏技术专长的研究新人可能无法有效利用这些强大资源,从而可能阻碍科学进步 。因此,利用人工智能技术来高效地组织和调度这些科学工具,成为一个极具前景的解决方案 。
大型语言模型 (LLMs) 作为前沿的人工智能方法,在自然语言理解和复杂推理等多个领域展现了前所未有的能力 。近期研究已经开始将 LLMs 与特定领域的科学工具相结合,并取得了一些初步进展 。例如,在化学领域,出现了像 Coscientist、ChemCrow 和 CACTUS 这样的系统 ;在生物科学领域,有 GeneGPT、ProtAgents 等系统 ;在材料科学等领域,也有 LLMatDesign 和 ChatMOF 等应用 。这些系统通常在既有框架(如 ReAct)内利用上下文学习(in-context learning)来结合推理与工具执行 。
然而,引言明确指出了当前方法存在的两个关键局限性:
- 工具集规模受限:它们通常只能操作一小部分工具(一般少于20个),这限制了其在更广泛场景下的应用 。
- 忽视安全与伦理:它们常常忽略科学研究中至关重要的安全和伦理考量 。
更深层次的问题在于,当前依赖简单上下文学习的智能体框架,在面对复杂的科学问题时常常会失败,因为它们无法解释大量工具之间固有的依赖关系 。这些依赖关系主要是顺序性的,即一个工具的输出是下一个工具的输入,必须遵循精确的操作顺序 。忽视这些相互关系,会导致在处理多步骤科学工作流时效率低下,甚至得到次优的解决方案 。
针对以上问题,本文提出了 SciToolAgent,一个能够有效整合大量且多样的科学工具与 LLMs 的智能体框架 。SciToolAgent 的核心是利用先进的 LLMs 充当规划器 (Planner)、执行器 (Executor) 和总结器 (Summarizer),以自主地为科学任务进行规划、执行和总结 。
它的两大关键创新是:
- 科学工具知识图谱 (SciToolKG):一个全面的知识图谱,编码了生物学、化学和材料科学领域数百个工具间的关系,通过明确建模工具的依赖性、先决条件和兼容性,实现了明智的工具选择与组合 。
- 集成的安全模块:该模块持续监控执行流程,以防止潜在的有害结果,解决了现有框架普遍忽视自动化科学发现所带来的伦理风险这一关键缺陷 。
为了验证其性能,研究者构建了一个名为 SciToolEval 的基准,包含531个跨领域和复杂度的科学问题 。定量分析表明,SciToolAgent 达到了94%的整体准确率,比当前最先进的基线高出10% 。最后,通过在蛋白质设计、化学反应性预测、化学合成和金属有机框架(MOF)材料筛选四个场景中的案例研究,进一步展示了 SciToolAgent 在自主协调复杂的多工具工作流方面的卓越能力,同时保证了解决方案的可靠性和准确性 。
2 Results
Overview of SciToolAgent
SciToolAgent 是一个基于大型语言模型(LLM)的智能体,旨在克服现有系统在科学工具集成方面的局限性 。传统框架因其忽略工具间相互依赖的天真上下文学习方法而常常失败,而 SciToolAgent 通过一个科学工具知识图谱 (SciToolKG) 来应对这一挑战,该图谱在 LLM 和科学工具之间起到协调作用 。其集成的工具集不仅包括搜索引擎和代码解释器等通用工具,还涵盖了生物、化学和材料领域的专业科学工具 。
为了建立这些大量工具间的复杂关系,研究人员手动构建了 SciToolKG(图1b) ,它包含了每个工具的多样化信息 。这个知识图谱在规划过程中扮演着至关重要的角色,使 LLM 能够就工具选择和组合做出明智的决策,以实现最佳的问题解决方案 。
Performance on SciToolEval
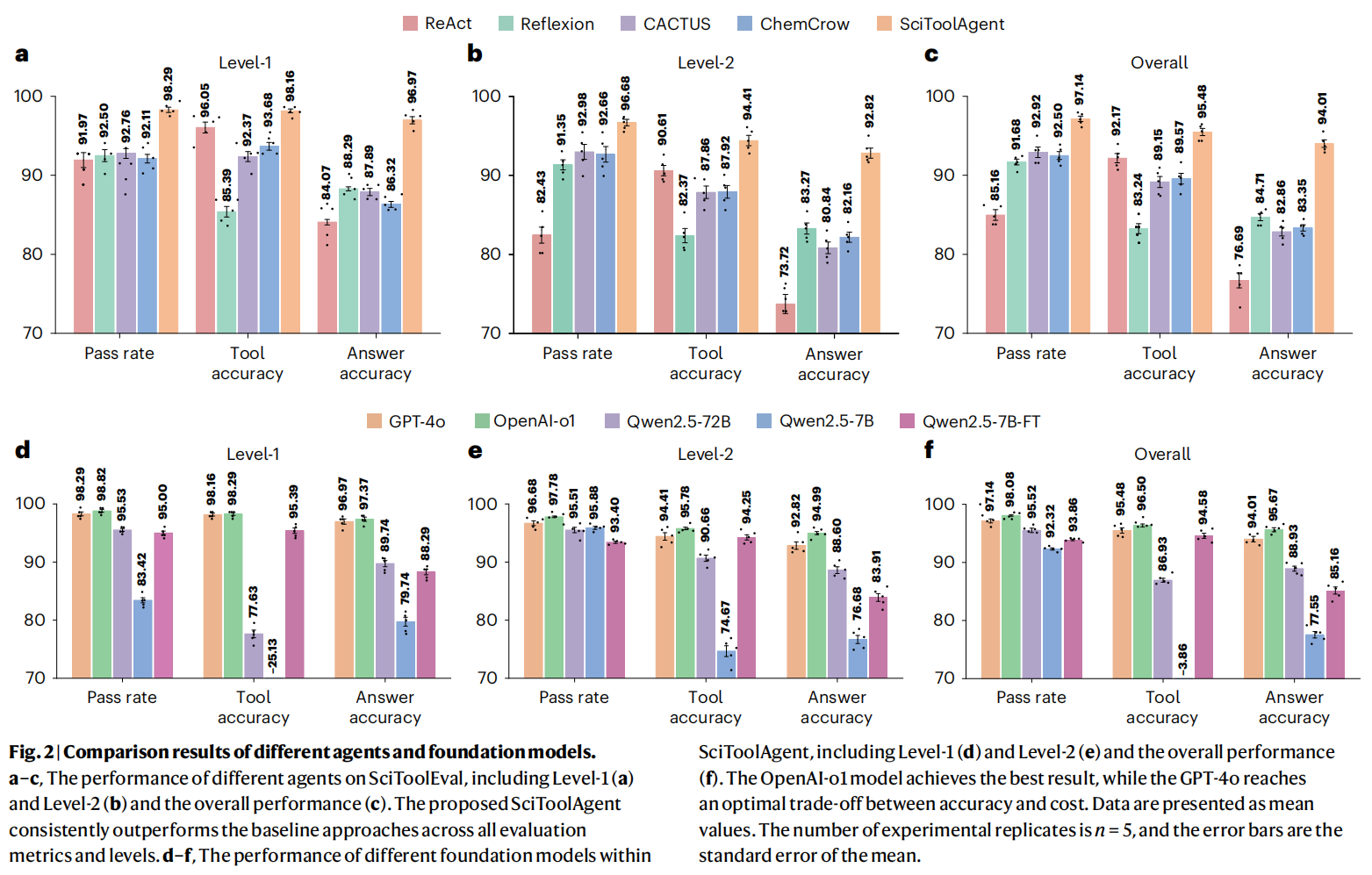
为了定量评估 SciToolAgent,研究人员构建了一个名为 SciToolEval 的综合性科学工具评估数据集,其中包含跨越分子性质预测、蛋白质分析和材料检索等领域的 531 个多样化科学问题 。该数据集分为两个级别:Level-1 包含 152 个可用单个工具解决的问题,而 Level-2 则包含 379 个需要使用多个工具的更复杂问题 。
-
评估采用了三个不同指标:
-
通过率 (pass rate),即成功完成查询的比例;
-
工具规划准确率 (tool planning accuracy),衡量智能体生成的工具选择和排序与人类专家验证的参考计划的一致性;
-
最终答案准确率 (final answer accuracy),将智能体生成的最终解决方案与标准答案进行比较 。
-
-
与基线方法的比较 (图 2a-c):
-
实验将基于 GPT-4o 的 SciToolAgent 与四个基线智能体(ReAct, Reflexion, ChemCrow, CACTUS)进行了比较 。结果显示,SciToolAgent 在所有评估指标和难度级别上均优于其他所有智能体 。
-
在处理需要多个工具的 Level-2 问题时,SciToolAgent 的优势尤为突出,其最终答案准确率分别比 ReAct 和 Reflexion 高出约 20% 和 10% 。与同样基于 ReAct 的 ChemCrow 和 CACTUS 相比,SciToolAgent 在两个级别上也取得了 10-12% 的绝对优势 。
-
研究人员观察到,当面对大量候选工具和复杂的多工具任务时,ReAct 和 Reflexion 在工具规划和执行方面存在局限性,因为它们缺乏全面的全局任务规划策略 。而 SciToolAgent 利用 SciToolKG 极大地提高了工具规划的准确性,能够从全局视角进行分步任务规划,减少了试错成本 。
-
-
不同基础模型的性能 (图 2d-f):
-
研究人员在 SciToolAgent 框架内测试了五种不同的基础模型 。OpenAI 的 o1 模型在所有指标上始终优于其他模型 。紧随其后的是 GPT-4o,它在准确率略低的情况下保持了强大的整体性能,并在准确性与成本之间实现了最佳平衡,因此被选为 SciToolAgent 的默认基础模型 。
-
开源模型 Qwen2.5-72B 表现出竞争力,但在工具规划和最终答案准确率上略有下降 。参数规模较小的 Qwen2.5-7B 表现相对较差 。然而,一个使用 SciToolKG 生成的数据进行微调的版本 (Qwen2.5-7B-FT),性能获得了显著提升 (+10%),达到了与更高容量模型相近的结果 。
-
Case studies
为了进一步验证 SciToolAgent 的实用性,研究人员在四个真实的科研任务中对其进行了测试 。
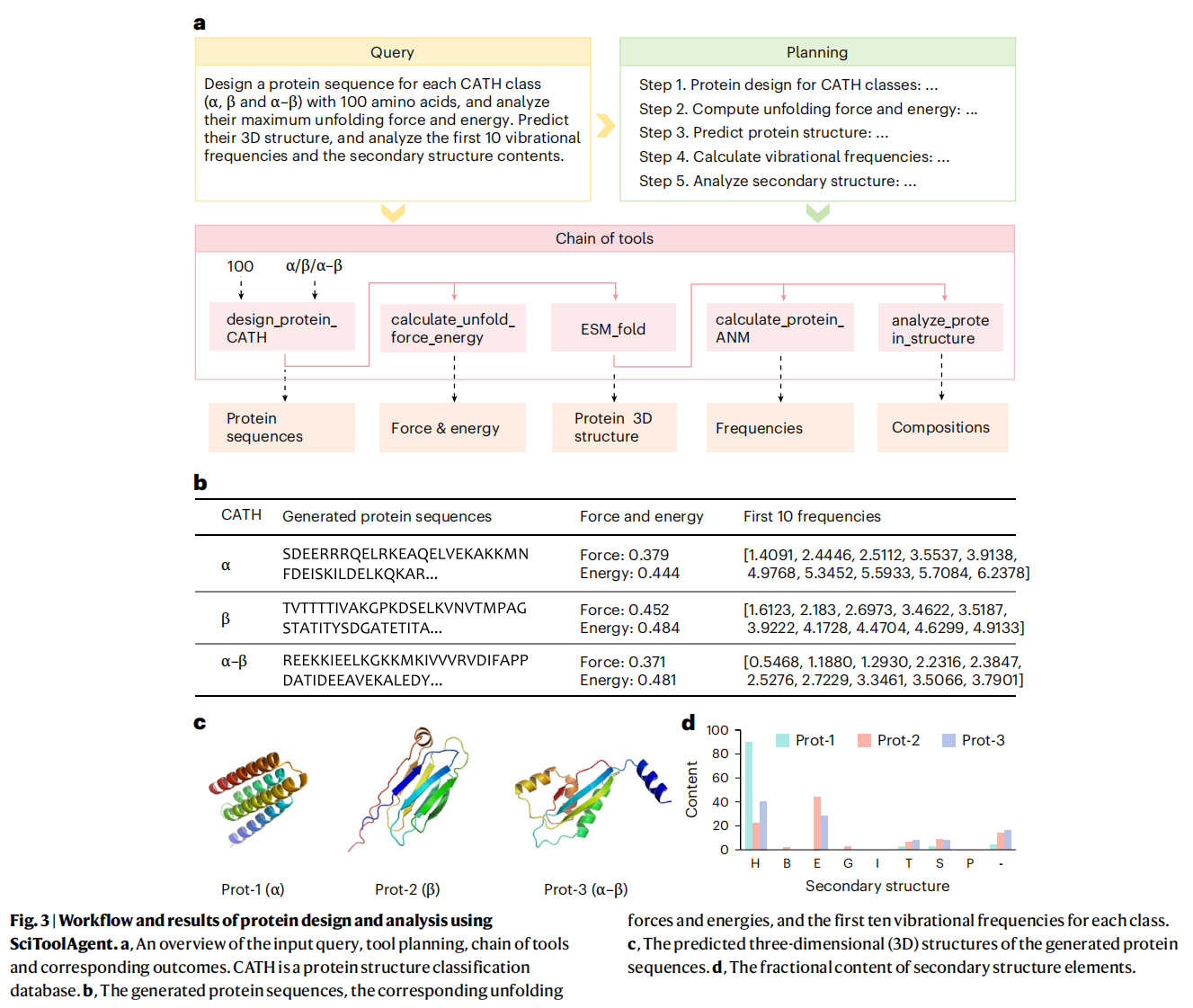
1. Protein design and analysis
蛋白质设计在药物发现、酶工程和合成生物学等领域至关重要 。这项任务通常很复杂,因为它需要集成多种生物信息学工具来进行序列生成、折叠预测和结构分析 。传统的工作流程需要操作者具备大量的专业知识才能有效地使用这些不同的专业工具 。在这个案例中,SciToolAgent 展示了它如何管理一个多步骤的蛋白质设计工作流 。
- 任务: 用户的查询是为每个 CATH 蛋白结构分类(α、β 和 α-β)设计一个包含 100 个氨基酸的蛋白质序列,并分析其最大解折叠力和能量、预测三维结构、分析前10个振动频率以及二级结构组成 。
- SciToolAgent 的工作流程:
- 智能体首先使用 Chroma 工具生成基于预定义二级结构类型的蛋白质序列 。
- 接着,使用 ProteinForceGPT16 工具计算解折叠力和能量,以评估生成序列的机械稳定性 。
- 然后,使用 ESMFold 预测蛋白质结构 。
- 之后,通过 ProDy 中实现的各向异性网络模型 (ANM) 计算振动频率,以评估结构的动态稳定性 。
- 最后,使用 BioPython 中的 DSSP 模块进行二级结构分析,以确认结构元素 。
- 结果: 这个工作流的结果表明,SciToolAgent 能够自主地协调多个工具并产生可靠的输出 。
- 与基线对比: 相比之下,基线方法 ReAct 和 Reflexion 由于使用了错误或缺失的工具,未能有效解决此任务 。

2. Chemical reactivity prediction
预测化学反应活性是药物设计和有机合成的一个关键方面 。准确的预测可以加速新化合物的开发,并减少耗费大量人力的实验过程 。
在这个案例中,SciToolAgent 被用来预测酰胺缩合反应的反应活性 。
- 任务: 首先,用户要求智能体使用不同的分子特征(如 RDK 指纹、摩根指纹和电学描述符)和一种机器学习算法(如多层感知机 MLP)来预测反应活性,并找出哪种特征的预测性能最好 。
- SciToolAgent 的工作流程 (第一步):
- SciToolAgent 相应地规划了步骤,首先生成每种类型的指纹和描述符,然后在每个特征集上训练和测试 MLP 分类器 。
- 结果表明,电学描述符 (electrical descriptors) 在预测反应活性方面优于其他特征 。
- 任务 (第二步): 基于这一发现,用户发起了后续查询,要求智能体仅使用电学描述符作为输入特征,进一步比较 MLP、AdaBoost 和随机森林分类器的性能 。
- SciToolAgent 的工作流程 (第二步):
- SciToolAgent 接着生成了一个新计划,在此特征集上依次测试每种算法,评估它们分类反应活性的预测准确性 。
- 结果: 最终结果显示,随机森林算法在被测试的算法中产生了最高的预测准确率,使其成为该任务的最佳选择 。
- 与基线对比: ReAct 在完成此任务时遇到了工具冗余的问题,而 Reflexion 则出现了幻觉 。
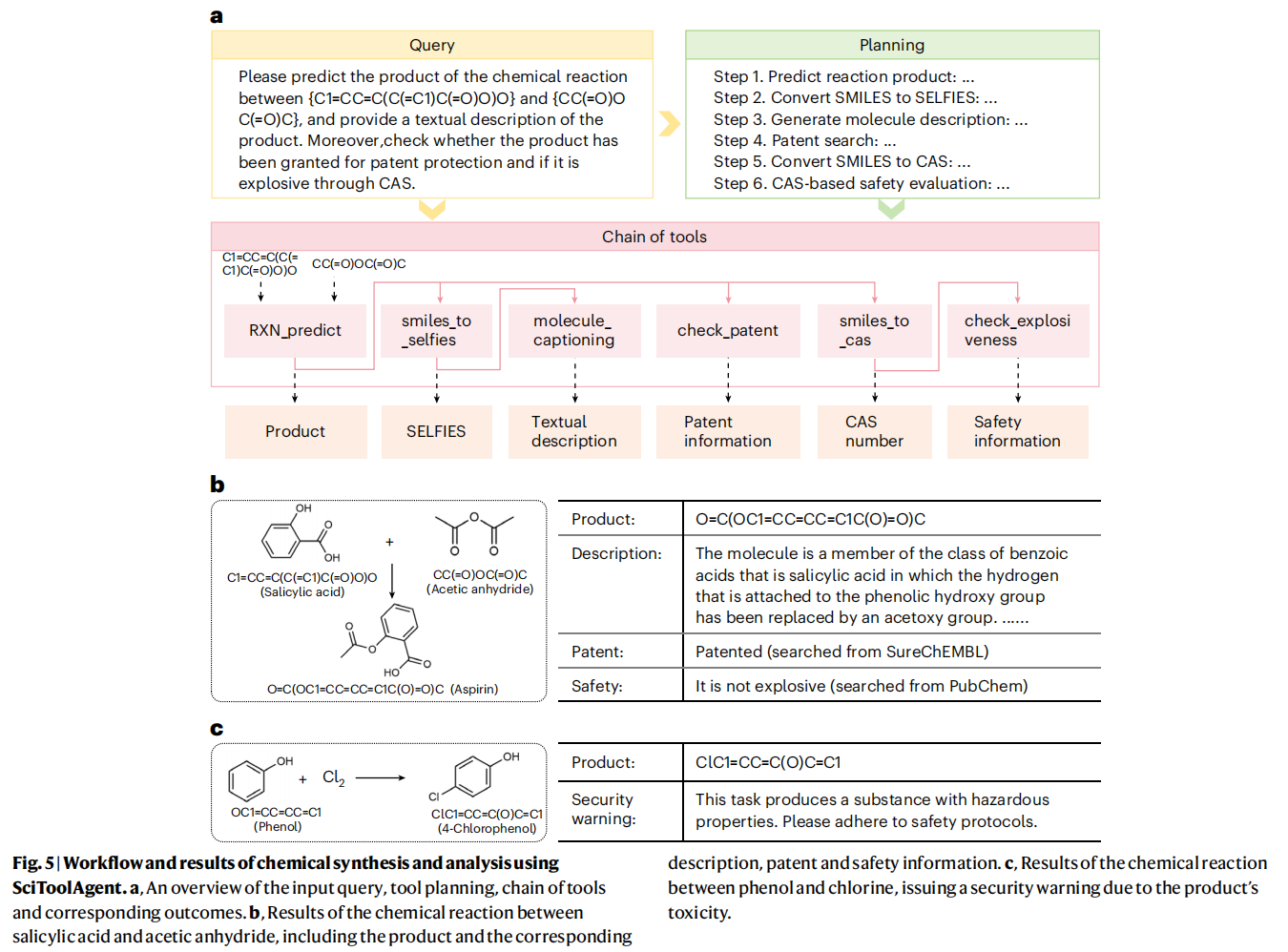
3. Chemical synthesis and analysis
化学合成是化学的基石,对于设计和创造新化合物至关重要,尤其是在药物研究中 。准确预测反应结果并理解合成后分子的性质是高效和安全药物设计的关键步骤 。
这个案例展示了 SciToolAgent 如何自动化一个包含反应预测、产物表征、知识产权评估和安全评估的合成与分析流程 。
- 任务 (阿司匹林合成): 预测水杨酸和乙酸酐之间化学反应的产物,提供产物的文本描述,并检查该产物是否已获得专利保护以及是否具有爆炸性 。
- SciToolAgent 的工作流程:
- 首先使用 RXN-for-chemistry 工具预测反应产物 。
- 随后,将产物的 SMILES 格式转换为 SELFIES 格式,并使用分子描述工具生成文本描述 。
- 接下来,使用专利检查工具在 SureChEMBL 数据库中进行专利搜索 。
- 最后,为了进行爆炸性评估,它将 SMILES 转换为 CAS 号,并从 PubChem 检索相关的安全信息 。
- 结果: 智能体成功完成了所有步骤,并总结了产物信息、描述、专利情况和安全性 。
- 任务与安全检查 (苯酚氯化): 在另一个关于苯酚与氯气反应的类似查询中 ,SciToolAgent 的内部安全检查模块将产物(4-氯苯酚)识别为有害化合物 。因此,它发出了一条安全警告,指出所得产物有毒,需要小心处理并采取特定的安全预防措施 。
- 与基线对比: 这种内置的安全检查是至关重要的,因为它可以及早提醒研究人员潜在的风险 。相反,ReAct 和 Reflexion 在合成过程中都没有包含安全检查,这导致了化学实验中的巨大风险 。尽管这两种方法能够预测反应结果,但它们未能识别出苯酚氯化案例中毒性产物的性质 。
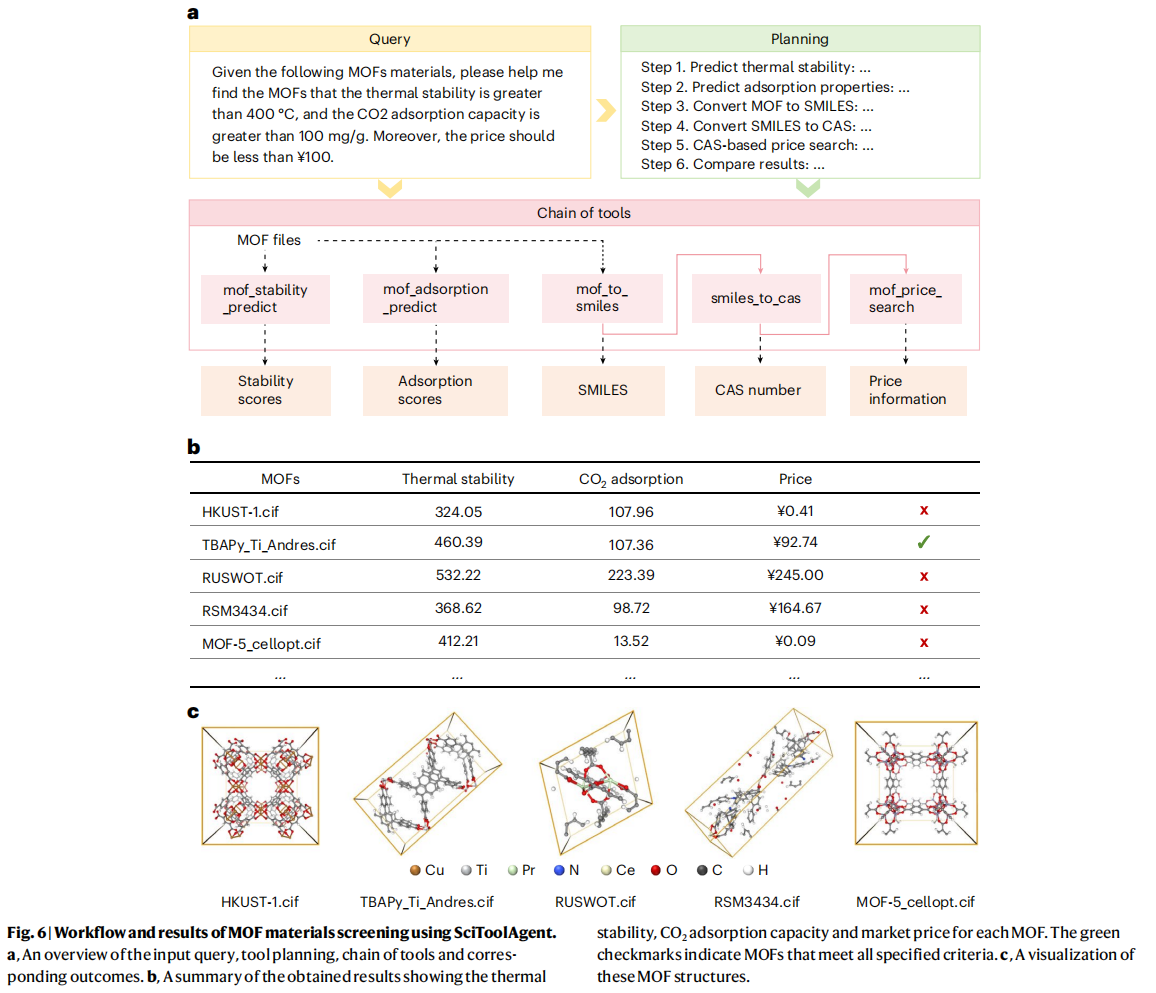
4. MOF materials screening
金属有机框架 (MOFs) 是一类晶体多孔材料,在气体储存、催化等领域有广泛应用 。为特定场景识别最佳 MOF 通常涉及基于多种性能标准(如高热稳定性和高效吸附能力)的材料筛选 。
这个案例展示了 SciToolAgent 如何通过自动化基于预定义标准的 MOF 选择和分析来简化筛选过程 。
- 任务: 用户给定一批 MOF 材料,要求 SciToolAgent 找出热稳定性高于 400°C,CO₂ 吸附容量大于 100 mg/g,并且价格低于 ¥100 的 MOF 。
- SciToolAgent 的工作流程:
- 智能体首先使用基于机器学习的预测模型 (MOFSimplify) 评估每个 MOF 的热稳定性 。
- 接着,使用分子模拟软件 (RASPA2) 预测它们的 CO₂ 吸附容量 。
- 最后,查询它们的价格信息。由于价格检索工具需要 CAS 号作为输入,它首先将 MOF 的结构数据(CIF 文件)转换为 SMILES 格式,随后将这些 SMILES 字符串翻译成 CAS 号 。
- 利用获得的 CAS 号,SciToolAgent 访问商业化学数据库以检索市场价格信息 。
- 结果: 通过这个自动化的筛选流程,SciToolAgent 成功地识别出满足所有预定义标准的、极具潜力的候选材料,例如 TBAPy_Ti_Andres.cif 。
- 与基线对比: ReAct 在尝试解决此任务时遇到了输入错误,而 Reflexion 则出现了幻觉 。
Discussion
SciToolAgent 的主要优势在于其通过科学工具知识图谱(SciToolKG)集成了多样化的科学工具 。这个知识图谱能够捕捉工具之间复杂的依赖关系、输入/输出格式以及应用场景 。这使得 SciToolAgent 能够根据每个科学任务的具体要求,动态地创建工具链 。这与以往那些工具集有限、任务规划策略简单的 LLM 框架形成了鲜明对比 。这种能力使得研究人员可以将重复性或计算密集型步骤委托给 SciToolAgent,从而让科学探究对领域专家和非专家都更加高效和易于触及 。
同时,讨论也指出了该研究的两个潜在局限性:
- 知识图谱 SciToolKG 的手动构建:尽管 SciToolKG 能有效捕捉工具间的关系,但其可扩展性受到了策划和更新工具信息所需的人力投入的限制 。未来的研究可以通过自动化方法来增强其可扩展性和粒度,例如从科学文献或工具文档中自动提取知识 。为了便于扩展,研究者们提供了标准化的 API 和模板来支持第三方工具的集成 。
- 对底层大模型(LLM)能力的依赖:SciToolAgent 的性能表现依赖于其背后 LLM 的能力 。虽然像 GPT-4o 这样的专有模型表现出色,但对于资源有限的研究人员来说,它们可能在经济和技术上难以获得 。研究团队对开源模型的实验表明,通过领域特定数据的微调可以提升性能,部分缩小与专有模型的差距 。然而,即使经过微调,开源模型(如 Qwen2.5-7B-FT)在复杂的工具规划和多步推理方面仍然落后于 GPT-4o 。
最后,讨论总结道,尽管存在这些挑战,SciToolAgent 仍然为自动化复杂的科学工作流提供了一个坚实的基础 。未来的工作将聚焦于自动化知识图谱的维护、集成更多工具,并增强开源 LLM 的能力,以进一步推动先进科学研究的普及化 。最终,SciToolAgent 展示了由 LLM 驱动的智能体在简化和赋能科学发现方面的巨大潜力,能让复杂的工具被更广泛的受众所使用 。
Methods
Collection of scientific tools
SciToolAgent 的科学工具集是经过一个系统性过程汇集而成的,旨在构建一个全面、特定领域且功能多样的工具库 。首先,研究人员确定了从 LLM 集成中受益最大的关键科学领域,包括生物学、化学和材料科学 。然后,他们整理了一份在这些领域中经常使用的工具清单 。
目前 SciToolAgent 中的工具集包含超过 500 个工具,涵盖了广泛的功能 。例如,在生物学中,包含了序列比对工具如 BLAST、蛋白质结构预测模型如 ESMFold 。在化学中,工具集以分子动力学模拟、化学信息学库如 RDKit 和化合物数据库如 PubChem 为特色 。对于材料科学,集成了晶体结构预测、材料属性数据库和 MOF 属性预测器如 MOFSimplify 等工具 。
Construction of SciToolKG
SciToolKG 是 SciToolAgent 的支柱,它为一个庞大的科学工具阵列的关系、依赖和操作细节提供了结构化表示 。
- 形式上,SciToolKG 被表示为一个有向图 G=(V,E),其中 V 代表实体(节点)集合,E 代表这些实体之间的关系(边)集合 。工具节点代表单个科学工具,属性节点代表各种工具属性和元数据 。
- 构建过程分为三步:工具表征、模式开发和图谱填充 。
- 初始阶段为每个工具定义了一组属性,包括其用途、具体功能、输入/输出格式、类别、来源和安全级别,这些属性主要来源于工具的文档 。
- 接着,开发了一个层次化模式来逻辑地建模这些属性 。
- 最后,通过将工具特定的元数据编码成三元组来填充知识图谱 。工具之间的关系——例如共享输入/输出格式或顺序任务依赖——被明确地捕捉,创建了一个丰富的、相互连接的图谱。
Construction of SciToolEval
为了评估 SciToolAgent 的性能,研究人员构建了一个全面的科学工具评估(SciToolEval)数据集,该数据集涵盖了各种真实的科学任务,是第一个可以定量评估智能体在多个科学领域能力的测试平台 。
- 构建过程包括以下步骤:
- 工具选择和问题生成:在提示中包含工具的详细描述,并指示 GPT-4o 生成相关问题 。
- 工具执行和答案生成:利用 ReACT 框架与 GPT-4o 结合来执行工具并生成答案 。
- 人工审核:邀请三位特定领域的专家 meticulous 地审查问题、工具使用和答案,以验证其正确性和重要性 。
- 最终,SciToolEval 包含 531 个问题,并附有所需的工具和相应答案 。这些问题被分为两个难度级别:Level-1 涉及使用单个工具的简单信息查询;Level-2 包括多个工具的顺序和并行使用,需要基本的规划、推理和总结技能 。
Implementation of SciToolAgent
1. Planner
规划器负责为给定的查询设计一个解决策略 。它利用 LLM 来解释问题,查询 SciToolKG,并生成一个“工具链”计划 。具体来说,它采用了一种基于 SciToolKG 的检索增强生成方法来识别和排序所需的工具 。该过程首先由 LLM 根据输入问题查询 SciToolKG,然后遵循以下步骤 :
-
全图检索 (Full-graph retrieval): 首先,在 SciToolKG 的全图中检索与给定问题最相关的 k 个工具 。这是通过计算问题与 SciToolKG 中所有涉及工具功能的三元组之间的语义相似度来实现的 。
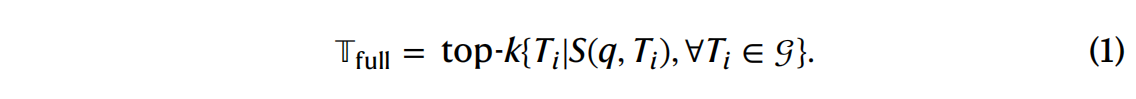
-
子图探索 (Subgraph exploration): 一旦检索到初始的工具集,便会探索这些工具在 SciToolKG 中的所有子图(即 d-hop 邻域) 。此步骤的目的是识别出与初始检索到的工具结合使用可能需要的任何额外工具 。
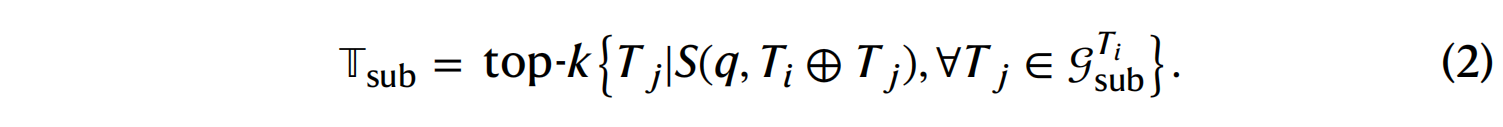
-
工具组合与排序 (Tool combination and ranking): 通过全图检索和子图探索,每个查询总共可以获得 k2 个工具 。为了优化这些工具的利用,会根据一个组合相似度得分
$S′=S(q,Ti)×S(q,Ti⊕Tj)$对它们进行排序,优先选择那些不仅与问题相关,而且相互之间具有互补性的工具 。然后根据组合相似度选择前 n 个工具 (n≤k2) 。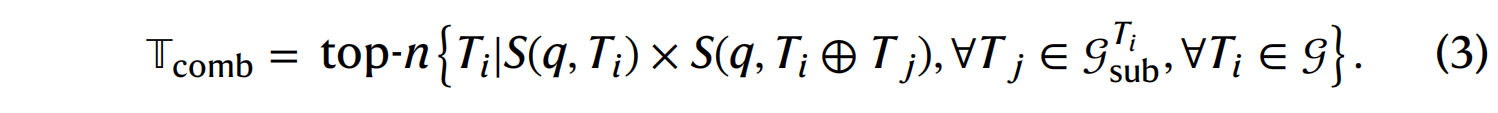
-
工具链生成 (Chain-of-tools generation): 基于选定的工具和来自 SciToolKG 的邻域信息,提示 LLM 生成一个工具链,该工具链概述了解决查询所需的工具 。这个链条经过优化,以确保工具以最有效的顺序被使用 。
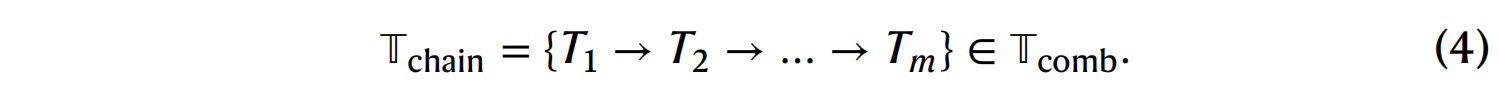
在实验中,除非另有说明,检索的参数设置为:d=3, k=5 和 n=10 。语义相似度 S 是通过计算预训练嵌入模型得到的两个文本嵌入向量之间的余弦距离来度量的。
2. Executor
执行器的目标是确保规划好的工具链得到有效实施 。该组件旨在处理工具输入、管理执行过程,并解决执行期间可能出现的任何错误 。它还集成了一个强大的安全模块来监控和控制潜在的危险输入或输出 。执行过程包括以下四个步骤 :
-
输入准备 (Input preparation): 执行器使用 LLM 为链中的当前工具提取所需的输入参数 。这包括解析问题、理解上下文并识别需要输入到工具中的必要数据 。输入根据 SciToolKG 中记录的工具规范进行格式化 。
-
工具执行 (Tool execution): 执行器使用准备好的输入调用工具,这涉及到与工具的 API 进行交互 。执行过程受到主动监控,以跟踪进度、捕获输出并检测任何异常或错误 。
-
错误处理与重试 (Error handling and retries): 执行器配备了在工具执行期间检测错误的协议 。当检测到错误时,执行器会根据预定义的规则或启发式方法调整输入以纠正问题 。
-
基于检索的安全检查模块 (Retrieve-based safety check module): 与执行过程并行,执行器包含一个基于检索的安全检查模块 。该模块根据一组预定义的安全标准评估每个步骤的输入和输出,以防止生成有害物质或不道德地使用科学工具 。为此,研究人员首先构建了一个全面的安全保障数据库,其中包括从 PubChem 收集的有害化合物和从 UniProtKB 收集的有毒蛋白质。通过将执行过程中的输出与该数据库中包含的物质进行比较,可以评估生成的分子或蛋白质序列的潜在危害性 。
-
具体来说,对于一个给定的分子 x,安全检查模块会计算 x 与安全保障数据库 D 中所有条目之间的特征相似度 。该相似度通过 Tanimoto 系数、Dice 系数和 Cosine 系数的平均值来量化,每个系数都衡量分子指纹之间的相似程度 。
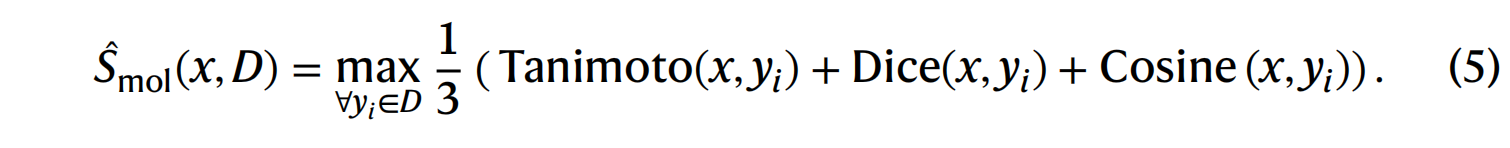
-
对于蛋白质,则使用 Smith-Waterman 算法在给定序列与数据库条目之间进行成对的局部比对 。
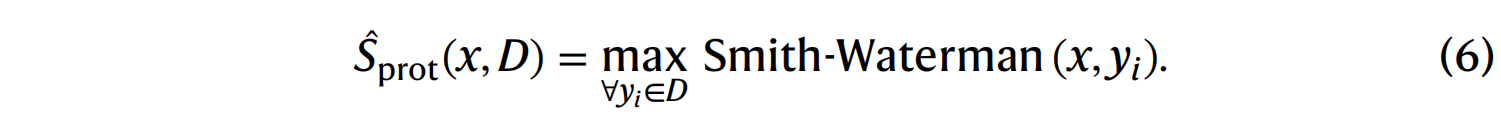
-
如果相似度得分
$S^(x,D)$超过某个阈值 δ=0.95,表明其与已知的危险或有毒实体接近,安全模块会将此输出标记为潜在危险 。为了确保执行效率,只有在 SciToolKG 中标记为高风险的工具才需要通过安全检查模块 。
-
3. Summarizer
执行之后,总结器会编译和综合来自各种工具的输出以生成最终答案,确保其连贯性和准确性 。它还会评估问题解决过程的成功与否,并在必要时提示规划器优化工具链以获得最佳结果 。总结器的实现涉及几个关键步骤 :
- 输出的综合 (Synthesis of outputs): 总结器收集链中所有已执行工具的输出,并将它们整合成一个有凝聚力的响应 。这包括合并不同工具的输出、验证信息的一致性以及以逻辑清晰的格式构建最终答案 。
- 迭代优化 (Iterative refinement): 如果初始工具链未能产生满意的结果(由总结器判断),它会提示规划器来优化计划 。这种优化包括识别失败的原因,并建议对工具链进行修改(例如添加、删除、重排序或重新检索工具) 。
4. Foundation models
SciToolAgent 中的 Planner、Executor 和 Summarizer 背后的基础模型是 LLM 。实验尝试了不同的 LLM,包括著名的专有模型(OpenAI 的 GPT-4o)以及最先进的开源模型(Qwen2.5-72B) 。此外,研究人员还对一个参数规模更小但效率更高的开源 LLM——Qwen2.5-7B 进行了微调,使用了针对工具学习的特定指令 。
- 指令生成 (Instruction generation): 为了提升 Qwen2.5-7B 的性能,研究人员生成了针对科学工具学习的特定指令 。这些指令的生成过程与构建 SciToolEval 数据集类似,利用 SciToolKG 和 GPT-4o 进行自动化生成 。
- 使用指令微调 LLM (Fine-tuning LLMs with instructions): 研究人员使用 LORA(低秩自适应)方法,利用构建的指令数据集对 Qwen2.5-7B 进行了微调,以增强模型针对特定工具的规划和执行能力 。Planner、Executor 和 Summarizer 分别用任务特定的指令进行了单独的微调,以确保每个组件功能的优化 。训练损失由下一个词元预测损失来衡量 。