
ToolACE:针对LLM定制tool数据集
Abstract
函数调用(Function calling)极大地扩展了大型语言模型(LLMs)的应用边界,而高质量且多样化的训练数据对于解锁这一能力至关重要 。然而,收集和标注真实的函数调用数据具有挑战性,同时现有的合成数据流程(pipelines)往往缺乏足够的覆盖范围和准确性 。
为此,该研究提出了一种名为 ToolACE 的自动化智能体流程(automatic agentic pipeline) 。ToolACE 旨在生成准确、复杂且多样化的工具学习(tool-learning)数据,并专门针对 LLM 的能力进行定制 。
ToolACE 的核心特点包括:
- 它利用一种新颖的自进化合成(self-evolution synthesis)过程,构建了一个包含 26,507 个多样化 API 的全面 API 池 。
- 在复杂度评估器(complexity evaluator)的指导下,通过多个智能体(agents)之间的互动来生成对话 。
- 为了确保数据准确性,ToolACE 实现了一个双层验证系统(dual-layer verification system),该系统结合了基于规则(rule-based)和基于模型(model-based)的检查 。
研究结果表明,使用 ToolACE 合成数据训练的模型,即使参数量仅为 8B,也取得了最先进的(state-of-the-art)性能,其表现可与最新的 GPT-4 模型相媲美 。该模型和部分数据已公开发布 。
1 Introduction
为大型语言模型(LLMs)配备外部工具已显著增强了 AI 代理(AI Agents)解决复杂现实世界任务的能力 。函数调用的整合使 LLMs 能够访问最新信息、执行精密计算并利用第三方服务 ,从而在工作流自动化、财务报告和旅行规划等多个领域解锁了广泛的潜在应用 。
论文接着强调,现实世界中的函数调用通常是多样化且复杂的,这是由 API 功能的多样性¹和任务范围的广泛性共同驱动的 。API 经常快速更新以满足多样化的用户需求,这就要求模型具备强大的零样本泛化(zero-shot generalization)能力 。此外,用户的需求可能很复杂或模棱两可,这会导致需要以并行(parallel)或依赖(dependent)方式使用多个工具,或需要多轮交互(multi-turn interactions)的场景 。这凸显了管理复杂指令和适应各种函数调用场景的重要性 。
尽管存在这些挑战,但当前工具增强型 LLMs 主要关注的是多样性和复杂性有限的简单函数调用任务 。它们主要依赖现有的公共 API 来构建任务 ,这限制了它们的零样本能力,也使其仅适用于单轮查询,而忽略了如依赖性或多轮交互等更复杂的场景 。此外,函数调用的执行需要精确的 API 选择和参数配置,这高度依赖于底层数据的质量和准确性 。随着数据变得日益多样化和复杂化,使用现有工作的简单流程来生成准确样本变得极具挑战性 。
针对这些问题,本文提出了 ToolACE ,这是一个系统的工具学习流程(tool-learning pipeline),旨在自动合成准确、多样化且复杂的函数调用数据,并能感知(awareness)模型自身的能力 。
ToolACE 包含三个核心特性:
- 进化多样性 (Evolutionary Diversity):让 LLMs 接触广泛的函数调用场景能增强其熟练度和零样本工具使用能力 。ToolACE 没有依赖公共 API,而是引入了一种工具自进化合成(TSS)方法 。TSS 使用“物种形成-适应-进化”(speciation-adaptation-evolution)过程,生成跨越多领域、具有不同数据类型和约束的工具 。该过程从预训练数据开始以确保全面的覆盖范围,通过自进化和持续更新的迭代过程来扩展 API 池的多样性,从而实现更复杂的数据生成 。
- 自引导复杂度 (Self-Guided Complexity):指令跟随(Instruction-following)数据应具备足够的复杂度以培养函数调用技能 。当数据复杂度略微超过 LLM 当前能力时,它们学习得更有效 。为此,ToolACE 提出了一个自引导对话生成(SDG)过程 ,其中 LLM 自身被用作评估器(evaluator)来调节复杂度 。通过多智能体互动,遵循一种自引导的复杂化策略(self-guided complication strategy),生成了四种类型的函数调用数据 。
- 精炼准确性 (Refined Accuracy):数据准确性是工具增强型 LLM 有效性的基础 。ToolACE 采用了一个双层验证(DLV)系统,该系统集成了基于规则(rule-based)和基于模型(model-based)的检查器,以保证合成数据的可执行性(executability)和一致性(consistency) 。
ToolACE 旨在通过具备数据准确性、复杂性和多样性,来增强 LLM 的函数调用能力和强大的泛化能力 。
论文的主要贡献 (contributions) 概括如下:
- 提出了一个新颖的自动化函数调用数据流程 ToolACE,它包含一个工具自进化合成模块、一个自引导对话生成模块和一个双层验证模块 。据作者所知,这是首个强调通过合成多样化 API 来改善函数调用泛化能力的工作 。
- 开发了一种自引导复杂化策略,以生成具有适当复杂度的各种类型的函数调用对话 。待定的 LLM 被用作复杂度评估器来指导生成数据的复杂度水平 。生成的数据质量通过结合了规则检查器和模型检查器的双层验证过程得到保证 。
- 在两个广泛采用的基准测试 BFCL 和 APIBank 上进行了实验 。仅有 8B 参数的模型在 ToolACE 数据上训练后,显著优于现有的开源 LLM,并能与最新的 GPT-4 模型相媲美 。
2 Data Generation Pipeline
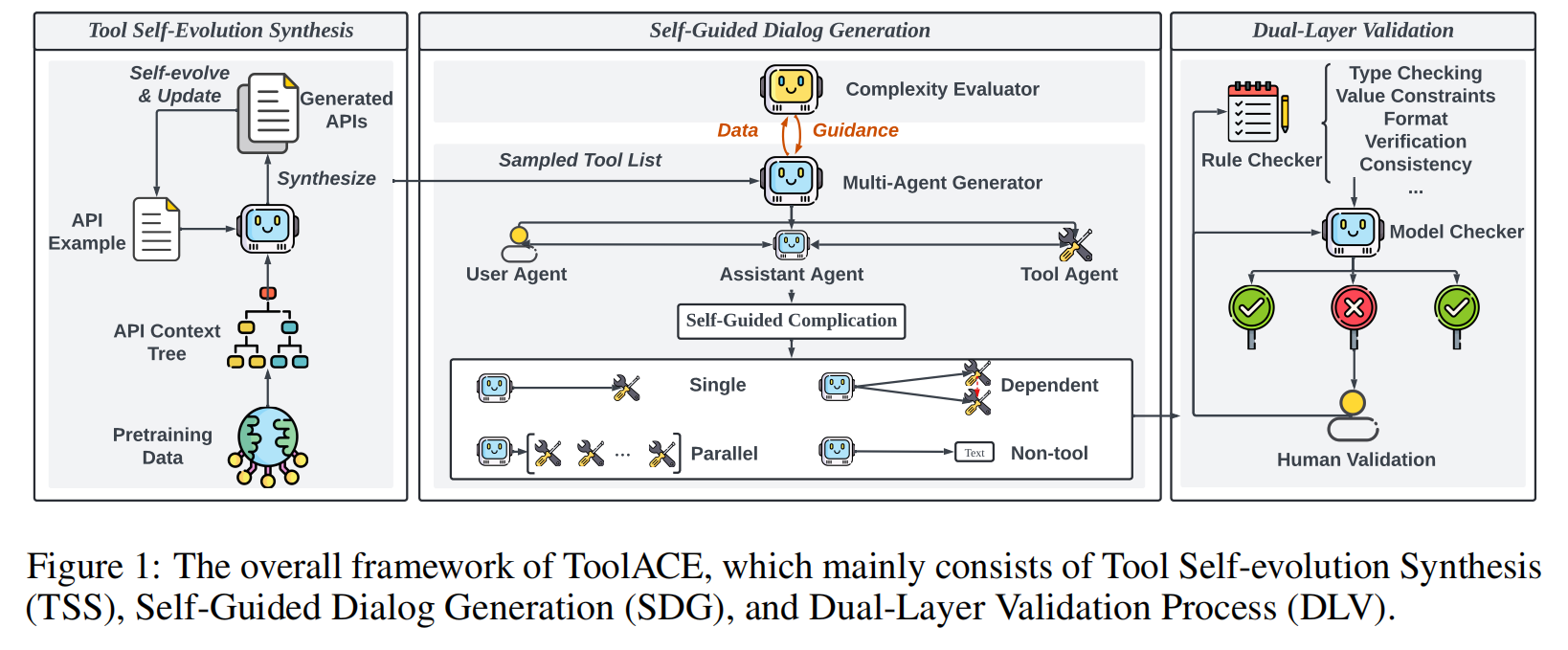
2.1 Tool Self-evolution Synthesis
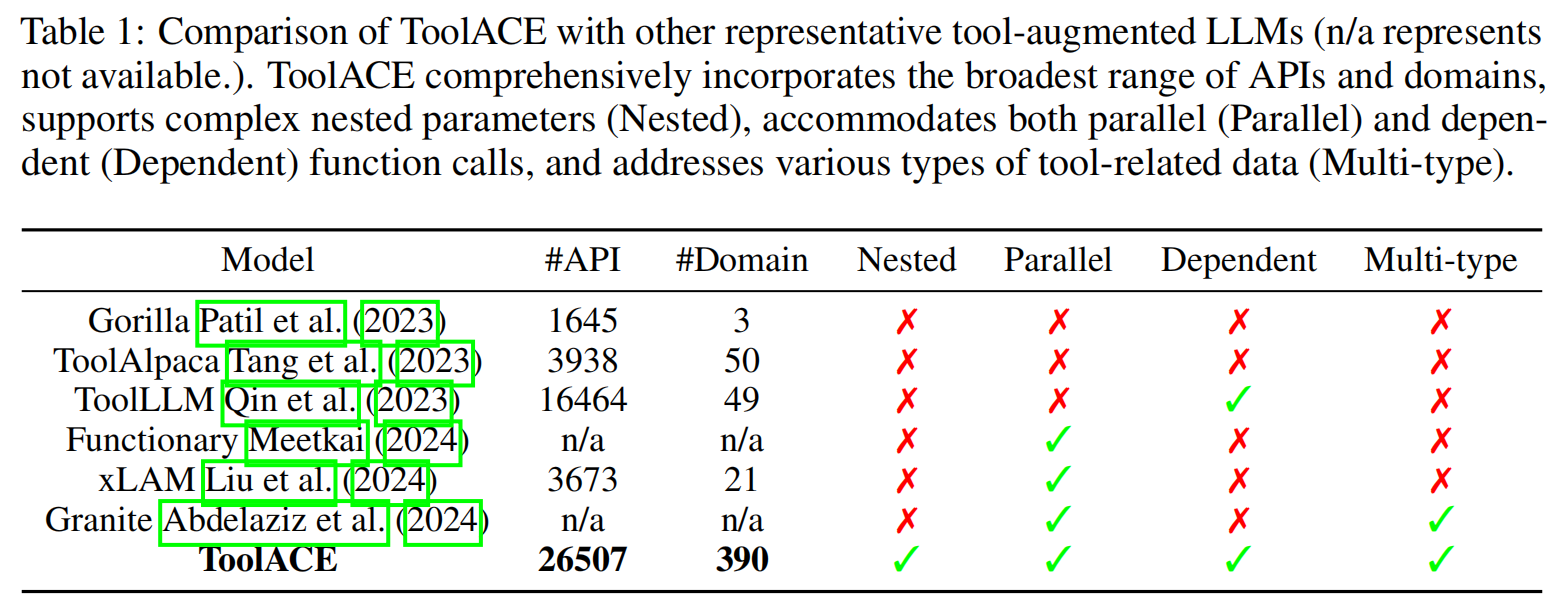
API 的多样性极大地支撑了函数调用数据的多样性 。如表 1 所示,ToolACE 建立了一个全面的 API 池,无论是在数量还是领域覆盖范围上都超过了其他代表性的工具增强型 LLM,其中既包含了真实的 API,也包含了合成的 API 。
除了收集真实的 API 数据外,开发了一个工具自进化合成(TSS)模块,用于合成具有各种数据类型和约束的 API 定义 。该模块包含三个主要步骤:1) 物种形成 (Speciation),2) 适应 (Adaptation),和 3) 进化 (Evolution) 。
-
物种形成 (Speciation):
-
具有广泛领域覆盖范围的 API 能让工具增强型 LLM 学习到来自不同应用和行业的更广泛用例,从而显著增强其泛化能力 。在物种形成步骤中,提议创建一个层级式的 API 上下文树(hierarchical API context tree),以可能的 API 领域和功能来指导合成过程 。
-
LLM 的预训练数据包含了最多样化的人类语料库来源之一,这为提取各种 API 领域和用例提供了坚实的基础 。从预训练数据中与 API 相关的原始文档(例如,技术手册、API 文档、产品规格、用户指南和教程)开始,提示一个由前沿 LLM 驱动的智能体从每个文档中提取一个 API 领域以及所有可能的 API 功能或用例 。上下文树的子节点在每一步都会被递归地生成,每个节点代表一个可能的 API 功能(例如,获取天气预报、获取股票价格、发送电子邮件) 。
fig9
-
附录 A 中的图 9 展示了娱乐(entertainment)领域下的一个子树示例 。
-
-
适应 (Adaptation):
- 在适应步骤中,为每个 API 指定领域和多样性级别 。从 API 上下文树中为每个独立的 API 采样一个子树并获取独特的功能,以便不同的 API 拥有不同的功能 。例如,某些 API 可能覆盖更多节点,从而获得更特定领域和更详细的能力 。而另一些 API 可能只包含上下文树中的一个节点,专注于一个简单、直接的目的 。
-
进化 (Evolution):
- 进化步骤涉及基于(先前)结果和新需求对 API 进行持续改进和调整 。指令一个 LLM 根据采样的 API 上下文树子树和一个 API 示例来合成新的 API 。新生成的 API 定义被要求清晰而详尽 。
- 然后应用一组多样性指标(diversity indicators),例如,添加新功能或参数、包含额外约束、变异参数类型以及更新返回结果,以使生成的 API 多样化 。
- 维护一个包含各种 API 示例的 API 示例缓冲区(API example buffer) 。迭代地从缓冲区中采样一个示例,使其适应当前的功能子树,并生成下一代的 API 。
所提出的 TSS 模块促进了多样化 API 文档的高效生成,包括了如列表的列表(lists of lists)或列表的字典(lists of dictionaries)等嵌套类型 。
2.2 Self-Guided Dialog Generation
函数调用数据的有效性与 LLM 的能力密切相关 。对于不同的 LLM,它们在预训练阶段学到的知识和能力是不同的,因此它们所需的函数调用数据也应有所不同 。例如,一个 0.5B 参数的 LLM 可能难以理解具有长依赖关系的极其复杂的数据 。相反,一个训练有素的 70B LLM 可以轻松处理意图清晰、API 简单的直接查询 。在这两种情况下,数据对于给定的 LLM 来说都是“无效”的(unproductive),这凸显了根据模型能力定制数据生成的重要性 。
因此,为确保生成的对话确实能填补给定 LLM 的能力空白,提出了一个自引导对话生成(SDG)模块来合成函数调用对话,如图 1 中间部分所示 。SDG 由一个复杂度评估器(complexity evaluator)和一个多智能体生成器(multi-agent generator)组成 。各种类型的函数调用对话通过多个智能体的交互来生成 。待调优的 LLM(the LLM to be tuned)被用作评估器,评估所生成数据的复杂度 。在评估器的指导下,被认为过于简单或过于复杂的数据会被动态调整 。
2.2.1 Multi-Agent Dialog Generation
提出了一个多智能体框架来生成四种类型的函数调用对话:单函数调用(single function calls)、并行函数调用(parallel function calls)、依赖函数调用(dependent function calls)和非工具使用对话(non-tool-use dialogs) 。
数据生成器包含三个智能体——用户(user)、助手(assistant)和工具(tool)——每个都由一个 LLM 模拟 。 首先,从构建的 API 池中采样一个或多个候选 API,并呈现给这些智能体 。然后,通过这三个智能体之间的角色扮演来生成对话,每个智能体都会被赋予必要的角色分配和详细的任务描述以继续对话 。
- 用户智能体(User Agent):主要负责提出请求或向助手提供额外信息 ,并通过一个自引导复杂化(self-guided complication)过程来调整对话复杂度 。
- 助手智能体(Assistant Agent):利用给定的 API 来解决用户的查询 。其动作空间包括:调用 API、请求更多信息、总结工具反馈以及提供非工具使用的答案 。为确保数据质量,每个助手动作都会被生成多次,只有在多个实例中决策一致的响应才会被采用 。此外,还应用了一种专为函数调用设计的、结构化的思维过程,以增强助手的工具调用决策 。
- 工具智能体(Tool Agent):充当 API 执行者 ,处理助手提供的工具描述和输入参数,并输出潜在的执行结果 。
对于每个函数调用对话,用户智能体首先发起一个与给定 API 相关的请求 。助手智能体审查该请求,并决定是调用 API 还是请求额外信息 。如果需要工具调用,工具智能体将提供模拟结果,然后助手智能体将总结这些结果并呈现给用户 。生成过程会继续,用户智能体再次查询或回应助手的问题,直到达到目标对话轮次长度 。
2.2.2 Data Complexity Evaluation
不同的 LLM 表现出不同的知识和能力,这需要使用不同的数据来优化工具使用性能 。然而,现有的许多研究忽视了模型能力与训练数据之间的相关性,导致数据效率不佳 。
在这项工作中,使用待调优的 LLM(表示为 $M$)作为评估器。使用 $M$ 在一个数据样本 $(x, y)$ 上的损失(loss)来评估数据复杂度,表示为 $H_{\mathcal{M}}(x,y)$ 。数据复杂度的衡量标准为:
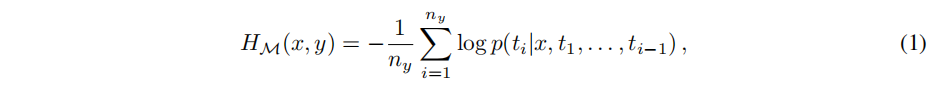
其中 $x$ 是输入查询, $y=[t_{1},...,t_{n_{y}}]$ 是包含 $n_{y}$ 个 token 的响应。 $t_{i}$ 表示第 i-th 个 token, $p$ 代表预测下一个 token 的概率。更高的损失意味着模型 $M$ 认为该数据样本 $(x,y)$ 更难学习。

研究结果(如图 2 所示)表明,数据样本的损失通常与以下因素呈正相关:(1) 可供选择的候选 API 数量,(2) 实际利用的 API 数量,以及 (3) 用户查询与 API 描述之间的不相似性。直观地说,随着候选 API 数量的增加,选择正确的 API 变得更加困难。同样,使用更多数量的 API 反映了更高的查询复杂度,而用户查询和 API 描述之间的较大差异则需要更复杂的推理才能识别正确的函数。这些发现验证了使用损失作为函数调用中数据复杂度度量的有效性。
为了给定的 LLM 建立一个合适的复杂度范围,创建了一个小型的、涵盖不同复杂度水平的先验数据集(prior data set)。
- 复杂度下限:如果一个数据样本能被 $M$ 正确生成,则表明模型已经掌握了相应的工具使用案例,因此该样本对于进一步微调是不必要的。其相关联的损失可作为数据复杂度的参考下限。
- 复杂度上限:相反,如果一个数据样本在微调后损失仍然很高,这可能表明该样本对于模型来说过于复杂难以学习。这个损失则作为参考上限。
的评估器将这个合适的复杂度范围,连同给定数据样本的损失,作为指导信息提供给多智能体生成器,用于生成训练数据。
2.2.3 Self-Guided Complication
从评估器获取当前数据的复杂度后,用户智能体的指令将被动态调整 。
- 如果数据样本对 LLM 来说过于简单,用户智能体将被指示生成一个更复杂的查询——例如需要更多 API,或进一步偏离 API 描述以增加复杂度 。
- 相反,如果数据样本超出了 LLM 的能力,用户智能体将被提示生成一个更简单的查询 。
通过这种方式,数据生成过程不断被调整,以更好地匹配模型的性能水平 。
2.3 Dual-Layer Data Verification
影响 LLM 函数调用能力的一个关键因素是训练数据的准确性(accuracy)和可靠性(reliability) 。不一致或不准确的数据会阻碍模型解释和执行函数的能力 。与通用问答数据(其正确性可能难以验证)不同,函数调用数据更易于验证(verifiable)。这是因为一个成功的函数调用必须严格匹配 API 定义中指定的格式 。
基于这一见解,提出了一个自动化的双层验证系统(DLV)来核实合成的数据,如图 1 右侧所示。该系统由一个规则验证层(rule verification layer)和一个模型验证层(model verification layer)组成,并且所有这些结果都受到人类专家的监督 。
规则验证层 (Rule Verification Layer) 规则验证层部署了一个规则检查器(rule checker) 。它依据一组精心策划的规则(如附录 B 所列),确保数据严格遵守预定义的 API 句法和结构要求 。这涵盖了四个关键方面:API 定义清晰度(API definition clarity)、函数调用可执行性(function calling executability)、对话正确性(dialog correctness)和数据样本一致性(data sample consistency) 。
例如,为了验证函数调用的可执行性,执行以下程序:
- 确认 API 名称与给定工具列表中的名称相匹配 。
- 验证所有必需(required)的参数都已准确提供 。
- 使用正则表达式确保参数格式和模式遵循 API 文档中的规定 。
这些程序使能够在不需要实际执行的情况下验证函数调用的正确性和可执行性,从而提高了效率并减少了部署开销 。
模型验证层 (Model Verification Layer) 模型验证层进一步利用 LLMs 来过滤掉规则检查器无法检测到的错误数据,主要关注内容质量(content quality) 。
然而,发现将整个数据样本直接交给 LLM 来评估正确性过于复杂,往往导致结果不尽人意 。为了解决这个问题,将模型验证任务分解为几个子查询(sub-queries),主要涵盖三个关键方面 :
- 幻觉检测 (Hallucination Detection):识别函数调用中输入参数的值是否是捏造的(fabricated)——即在用户查询或系统提示中均未提及 。
- 一致性验证 (Consistency Validation):核实响应(responses)是否能有效完成用户的任务,并确保对话内容遵守用户查询和系统提示中的约束及指令 。
- 工具响应检查 (Tool Response Check):确保模拟的工具响应与 API 定义保持一致 。
每个方面都由一个独立的、由 LLM 驱动的专家智能体(expert agent)进行评估 。还引入了其他验证提示(verification prompts),以消除数据中重复的响应和无意义的 token 。
3 Experiment
3.1 Experiment Setup
为了验证方法的有效性,研究人员通过使用生成的数据训练 LLM 进行了广泛的实验 。
- 基础模型与训练:在大多数实验中,以监督微调(SFT)的方式训练了开源 LLM LLaMA3.1-8B-Instruct 。该模型被称为 ToolACE-8B 。还使用其他骨干 LLM(如 Qwen 系列)验证了数据 。由于资源有限,采用了参数高效的 LoRA 训练策略 。
- 超参数:LoRA 设置采用了最常见的配置之一,所有模块的 rank 设为 16,alpha 设为 32 。
- 对比模型:研究人员将 ToolACE-8B 的整体性能与最先进的(state-of-the-art)API-based 模型(如 GPT 系列)以及开源模型(包括经过微调的函数调用模型,如 Gorilla-OpenFunctions-v2 和 xLAM-series)进行了比较 。
- 基准测试 (Benchmarks):实验在两个代表性的基准上进行:BFCL (Yan et al. 2024) 和 API-Bank (Li et al. 2023) 。这两个基准是专为评估 LLM 调用函数能力而设计的、全面且可执行的函数调用评估 。
- 消融研究:随后进行了深入的消融研究,以揭示数据准确性、多样性和复杂度的有效性 。
更多实验设置细节(包括基准详情、评估指标和训练设置)显示在附录 C 中 。
3.2 Overall Performance Analysis
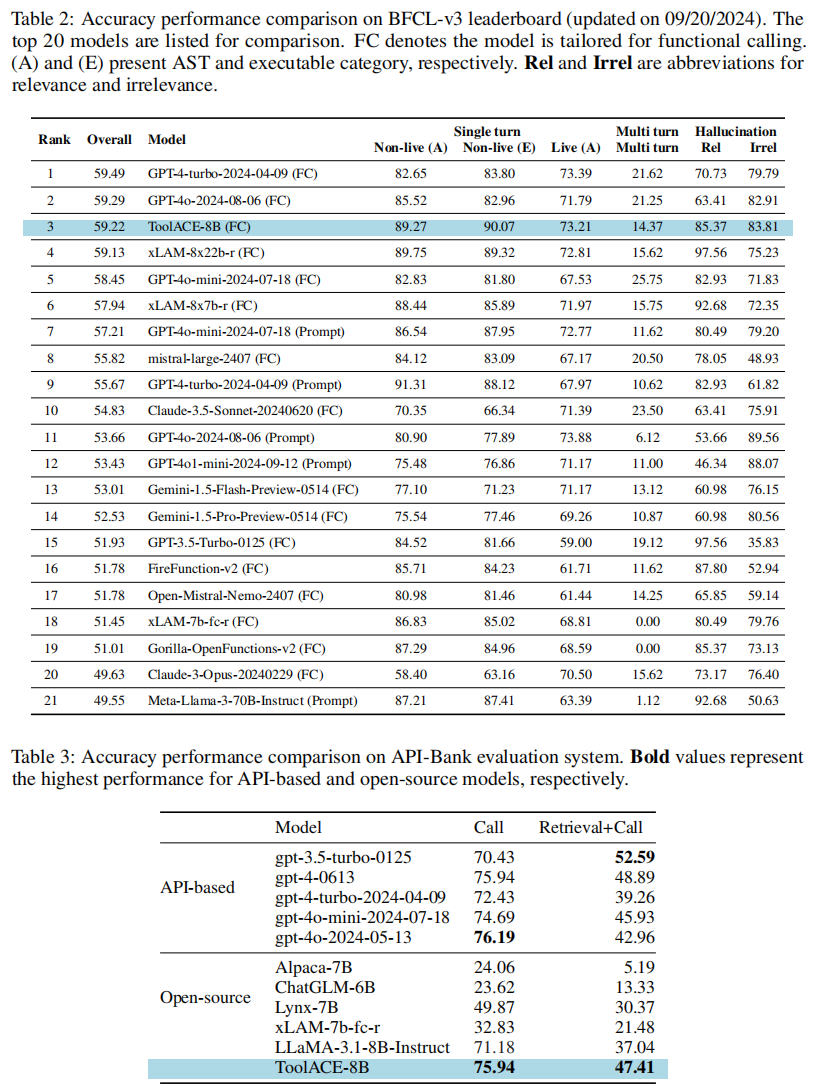
为了评估 ToolACE-8B 模型的函数调用能力,研究人员将其与各种代表性模型进行了比较 。结果分别总结在表 2 和表 3 中 。
- BFCL 表现:
- 在 BFCL 上的发现表明,API-based 模型(如 Claude 系列和 GPT-4 系列)相比开源模型具有显著优势 。
- 为函数调用而微调的开源模型(如 Functionary 和 xLAM)表现出竞争力,但仍落后于领先模型 。
- ToolACE-8B 在 BFCL 的 AST(抽象语法树)和 Exec(可执行)类别中,优于大多数 API-based 模型和开源模型 。
- ToolACE-8B 在缓解幻觉(hallucination)方面表现出色,在相关性(Relevance)和无关性(Irrelevance)类别上分别取得了 85.37% 和 83.81% 的高分 。这突显了它在两个类别之间保持了出色的平衡 。
- 与同样是微调函数调用且大小相似的 xLAM-7b-fc-r 相比,ToolACE-8B 在所有类别中都持续且显著地优于前者 。
- API-Bank 表现:
- ToolACE-8B 在 API-Bank 上继续展现出相对于所有开源模型的显著优势 ,并且表现出与 GPT-4 系列模型相当的性能 。
论文将 ToolACE 的优异表现主要归功于其合成数据的准确、多样和复杂,这增强了 LLM 的零样本函数调用能力 。
3.3 Ablation Study
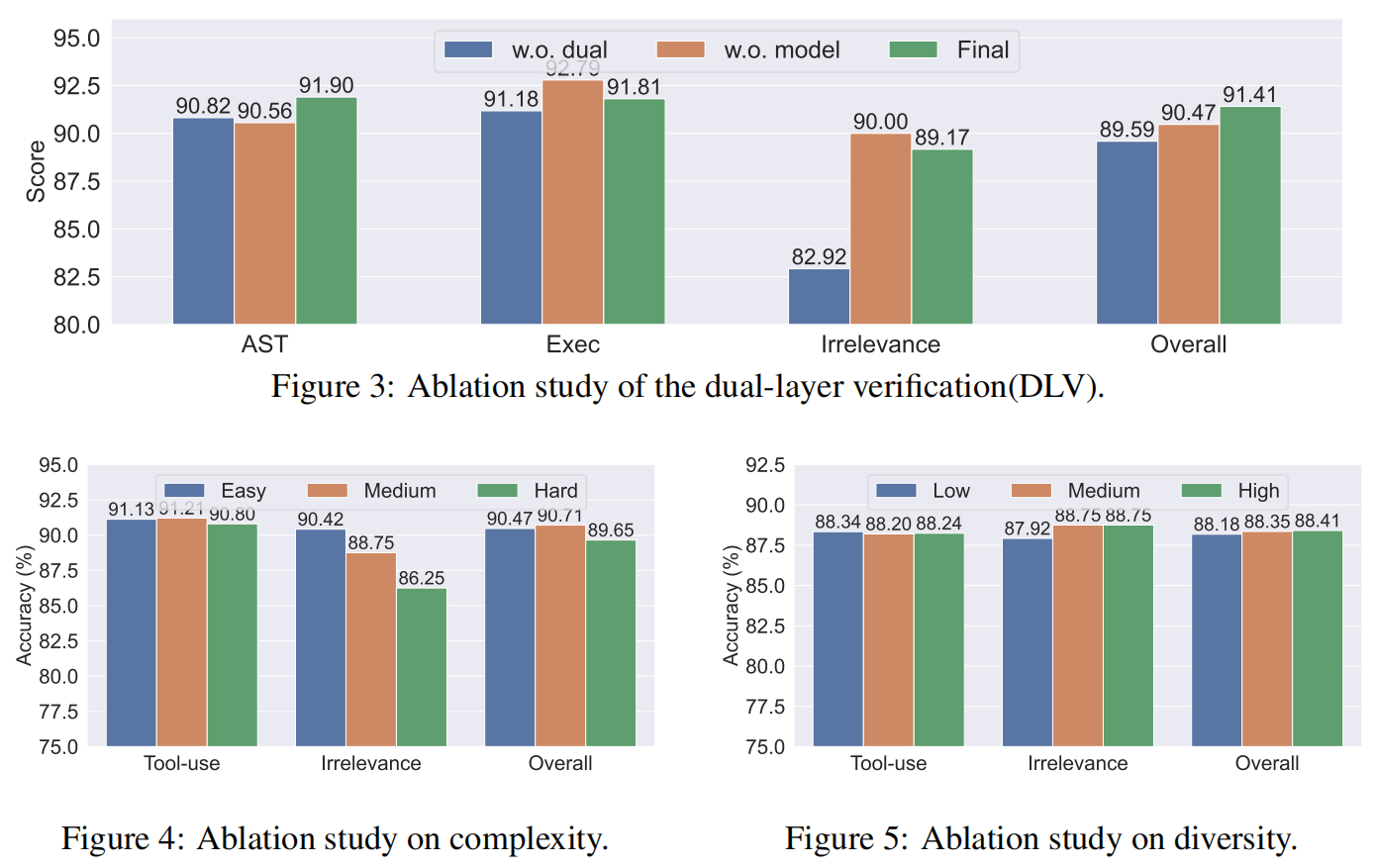
3.3.1 Ablation on Accuracy
验证系统的效果:为评估验证系统(包含规则检查器和模型检查器)中每一层的功效 ,研究人员使用三个不同数据集训练了 LLaMA3.1-8B-Instruct :(1) 未经任何验证的数据 (w.o. dual),(2) 未经模型检查的数据 (w.o. model),(3) 经过双层验证的数据 (Final) 。
结果 (图 3):
- 使用 “w.o. model”(仅规则检查)训练的模型,在可执行和总体准确性上优于 “w.o. dual”(无验证) ,这验证了规则检查器的有效性 。
- 使用 “Final”(双层验证)数据训练的模型,在 AST 和总体准确性上显著优于其他两个消融模型 ,这突显了模型检查器不可或缺的作用 。
3.3.2 Ablation on Complexity
数据采样:为了评估数据集复杂度的影响,使用公式 (1) 计算并排序了每个数据样本的复杂度。选取了底部、中部和顶部的 60,000 个实例,分别作为 $ToolACE_{easy}$、$ToolACE_{medium}$ 和 $ToolACE_{hard}$ 三个子集。
复杂度的效果 (图 4):研究人员用这三个不同复杂度的子集训练 LLaMA-3.1-8B-Instruct 。结果显示,在总体准确性和工具使用准确性方面,使用 $ToolACE_{medium}$ 训练的模型比较另外两个子集显示出轻微的优势 。
结论:这一发现与他们的假设一致,即最佳的数据复杂度对 LLM 训练至关重要,因为数据太简单或太复杂都可能阻碍模型达到其全部性能潜力。
3.3.3 Ablation on Diversity
数据采样:为了评估多样性的影响,研究人员生成了三个不同多样性的子集:$ToolACE_{low}$、$ToolACE_{medium}$ 和 $ToolACE_{high}$。首先,所有 API 根据 API 上下文树被聚类为 30 组。随后,通过分别从 6 个、14 个和 30 个集群中选择 API 来构建三个 API 子集。最后从每个子集中随机选择约 30,000 个实例。
多样性的效果 (图 5):在 BFCL 上的结果显示,训练数据的多样性与模型的整体准确性呈正相关。特别是在无关性检测(irrelevance detection)方面的提升尤为明显。这表明,接触更广泛的 API 增强了模型区分 API 间细微差异的能力,从而提高了无关性检测的能力。
3.4 Scaling Performance of Model Size
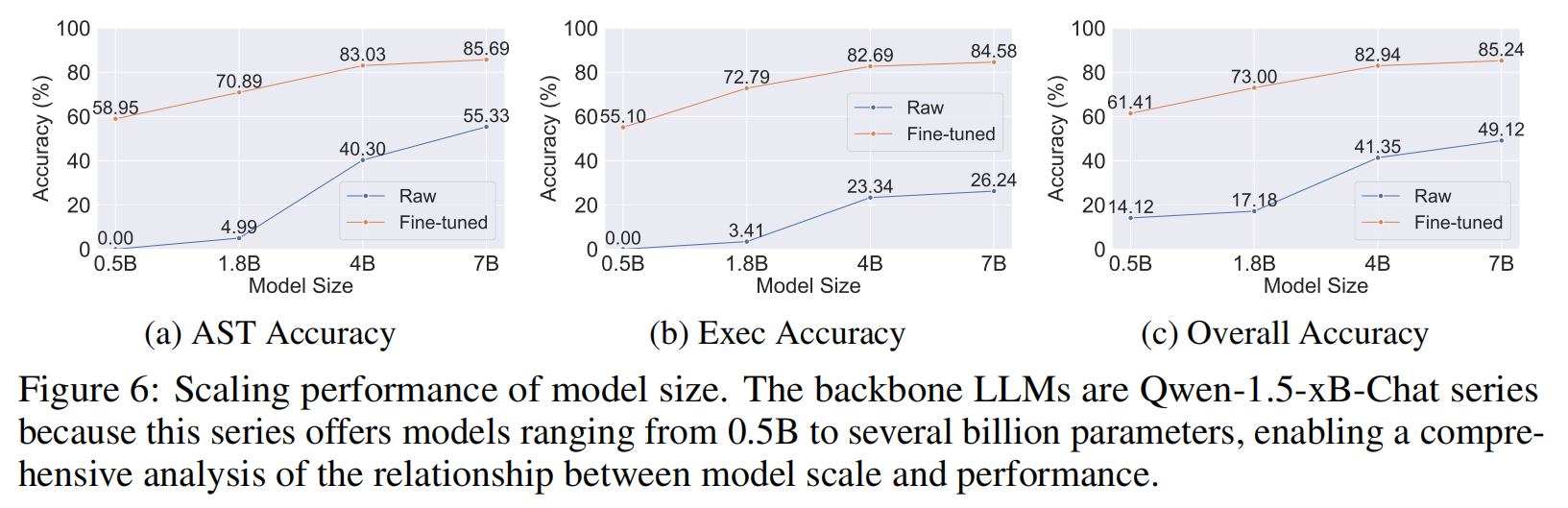
为研究函数调用能力的可扩展性,实验使用了 Qwen-1.5-xB-Chat 系列(包括 0.5B, 1.8B, 4B, 7B 等多种模型大小) 。研究人员在 BFCL 基准上评估了原始(raw)模型和使用 ToolACE 数据集微调后的模型(结果见图 6) 。
结果:
- 正如预期的,更大的模型在 AST 和 Executable 准确性上均表现出更优越的函数调用性能 。
- 较小的原始模型(0.5B 和 1.8B)几乎没有函数调用能力 。
- 在 ToolACE 数据集上微调后,这些模型的能力显著增强 。微调后的模型展现出一致的扩展性能 ,这凸显了 ToolACE 提升更大型 LLM 性能的潜力 。
3.5 Study on Various Backbone LLMs
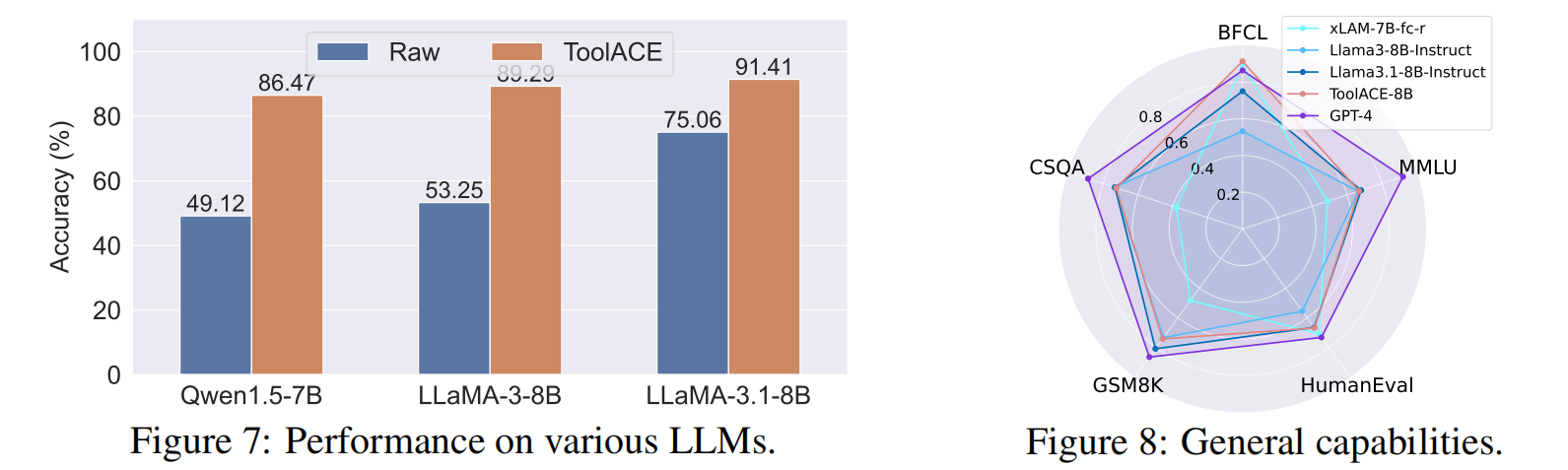
为了研究 LLM 骨干网络的影响,研究人员在几个(约)8B 规模的模型上进行了实验:Qwen1.5-7B-Chat、LLaMA-3-8B-Instruct 和 LLaMA-3.1-8B-Instruct 。微调后的模型在 BFCL 基准上进行了评估(结果见图 7) 。
结果:
- 所有模型在微调后都获得了显著的性能提升,凸显了 ToolACE 的有效性 。
- 由于预训练语料库的差异(例如 Qwen 训练了更多中文对话样本),原始模型展现出不同的函数调用能力,其中 LLaMA-3.1-8B-Instruct 表现更优 。
- 这种层级关系在微调后得以保持,但性能差距缩小了 。这表明 ToolACE 数据集有潜力增强那些为其他技能(如对话技能)定制的 LLM 的函数调用能力 。
3.6 Study on General Capabilities
目的:评估 ToolACE 训练对 LLM 更广泛能力的影响 。
设置:实验跨越了多个评估通用能力的基准,包括 MMLU(综合理解)、HumanEval(编码)、GSM8K(数学)、CommonSenseQA(推理)以及 BFCL(函数调用) 。
基准对比模型:原始 LLaMA-3-8B-Instruct、LLaMA-3.1-8B-Instruct、专门的 XLAM-7B-fc-r 和 GPT-4 。
结果 (图 8):
- ToolACE-8B 在大多数基准上实质性地优于 XLAM-7B-fc-r,尤其是在 MMLU、GSM8K 和 CommonSenseQA 上增益明显 。
- 与 GPT-4 相比,ToolACE-8B 在推理和理解方面表现出明显局限 ,这主要归因于模型规模和训练语料库 。
- 与原始 LLaMA-3.1-8B-Instruct 相比,ToolACE-8B 在某些基准上性能下降可忽略不计,同时在函数调用方面取得了显著增强 。
结论:这些发现表明,ToolACE 数据集有效增强了函数调用能力,而没有损害底层 LLM 的通用能力 。