
论文地址:How Much Can CLIP Benefit Vision-and-Language Tasks?
论文实现:https://github.com/clip-vil/CLIP-ViL
CLIP-ViL:CLIP在视觉下游任务的实验性文章
Abstract
实验性文章,把CLIP拿到多模态来初始化还能继续提高下游vision language task的准确度
Introduction
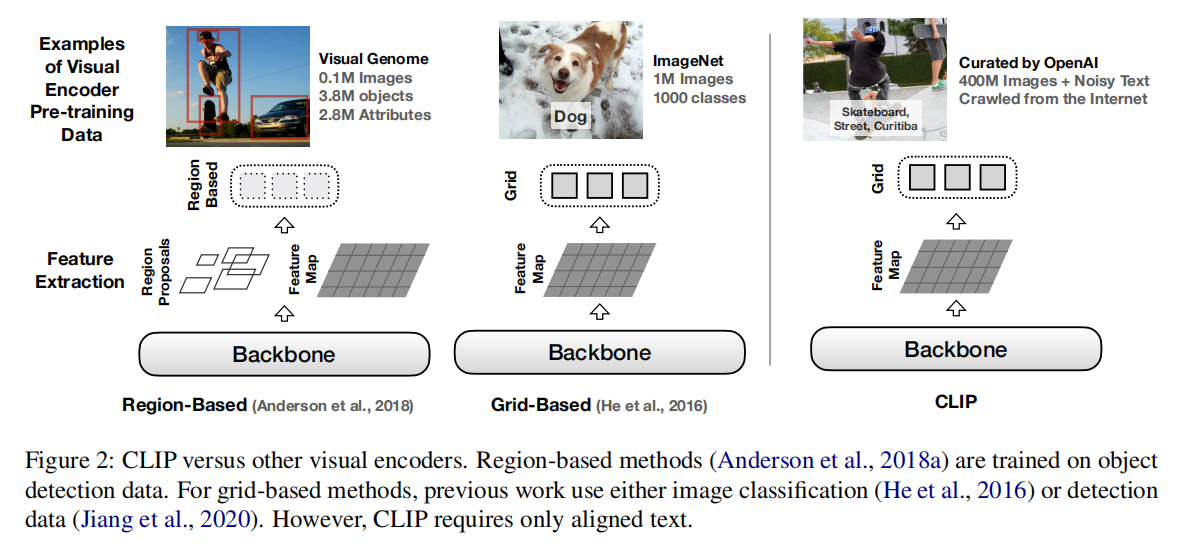
主要贡献:第一个大规模的用CLIP预训练好的模型当作视觉编码器的初始化参数,在各种下游任务上做empirical study
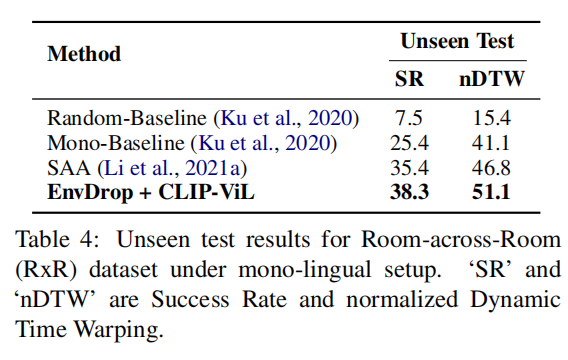
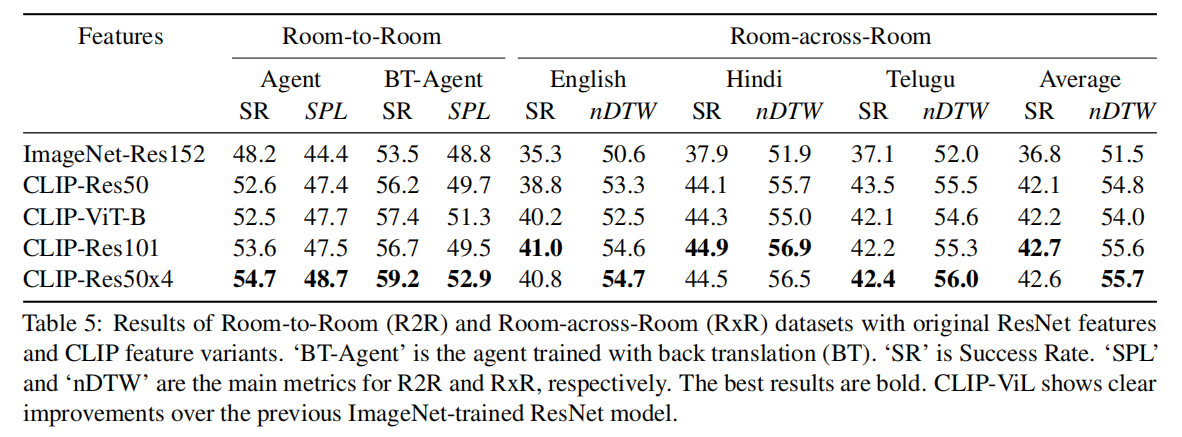
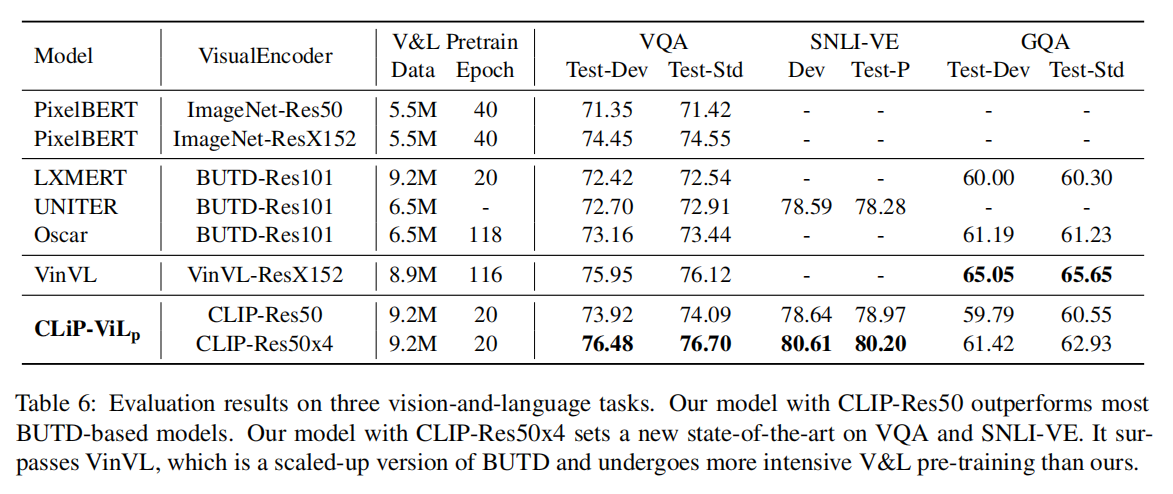
Experiments
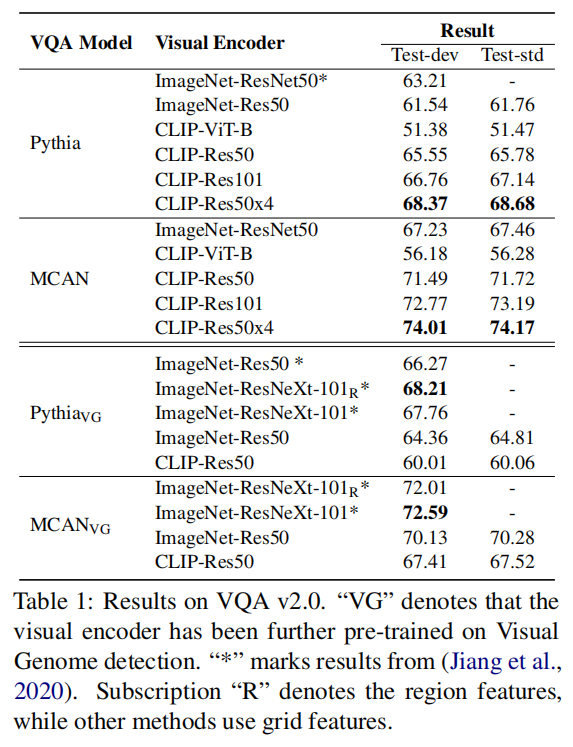
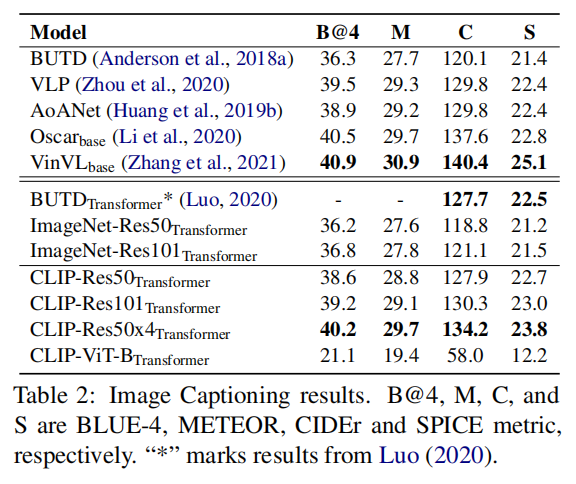
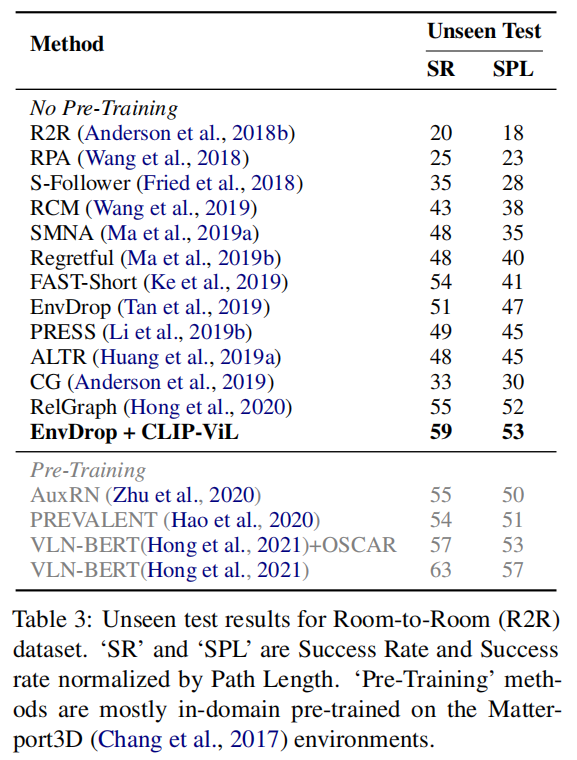
<HR align=left color=#987cb9 SIZE=1>