
MixGen:图像线性差值和文本拼接做多模态数据增强
Abstract
提出了MixGen:一种用于视觉-语言表示学习的联合数据增强方法,它通过插值图像和连接文本,生成具有保留语义关系的新的图像文本对。在四个框架下进行了测试,CLIP,ViLT,ALBEF和TCL
Introduction
图片文本做数据增强时会出现信息丢失或歧义的情况,比如图像反转后,原本描述这个图像的文本可能就不再适合了,所以这种情况下做数据增强是比较困难的。所以需要在保留信息,不改变语义的情况下做数据增强
MixGen
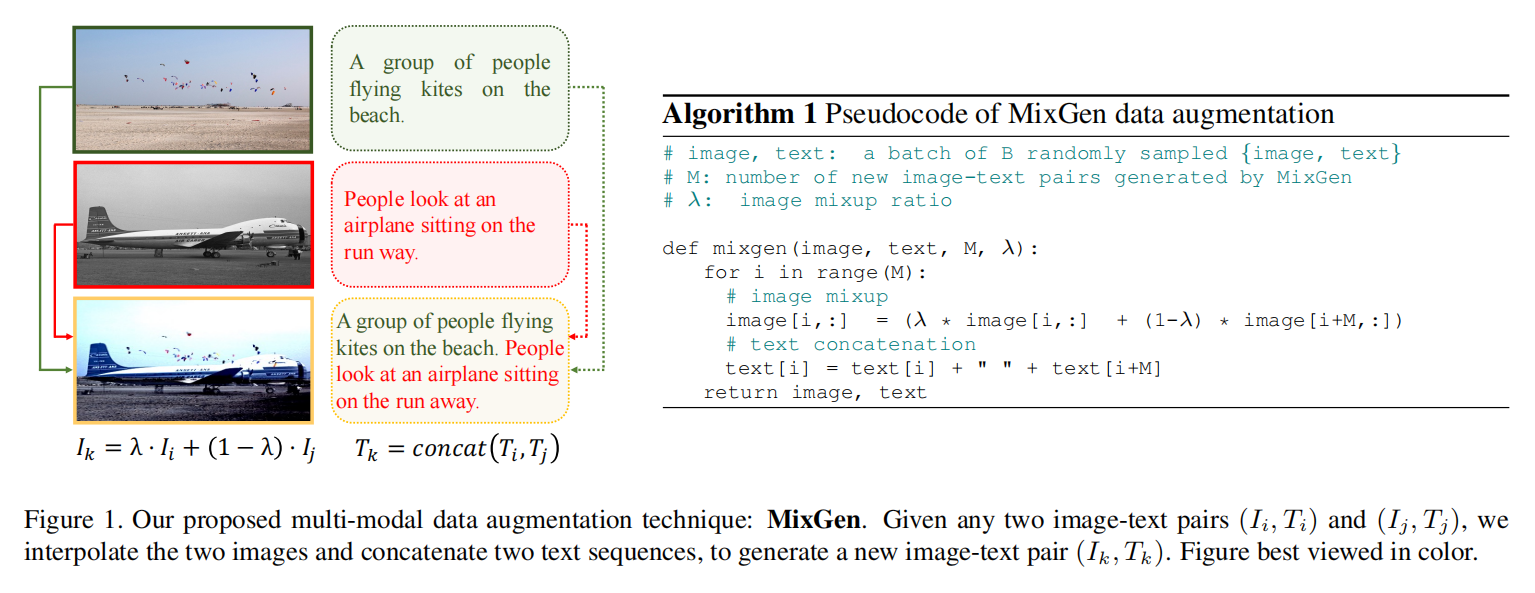
图片通过线性插值,两个图片叠加,句子直接拼接起来,这样得到新的训练样本,就是数据增强了
Experiments
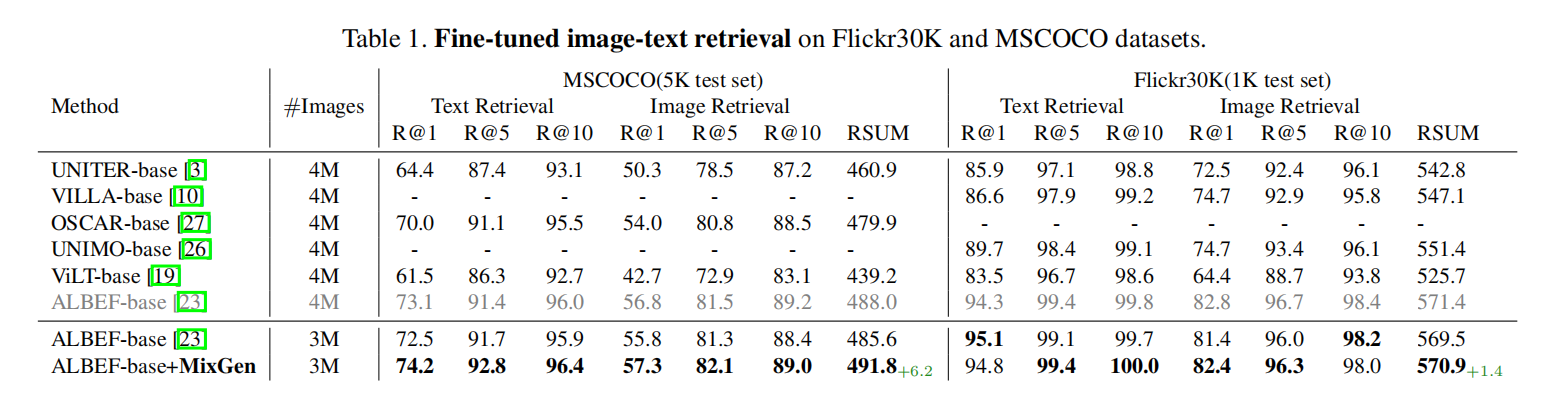
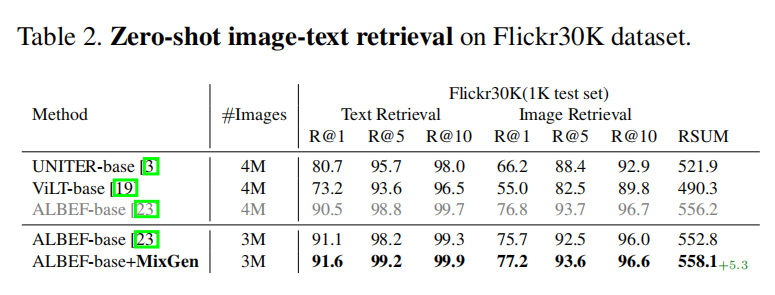
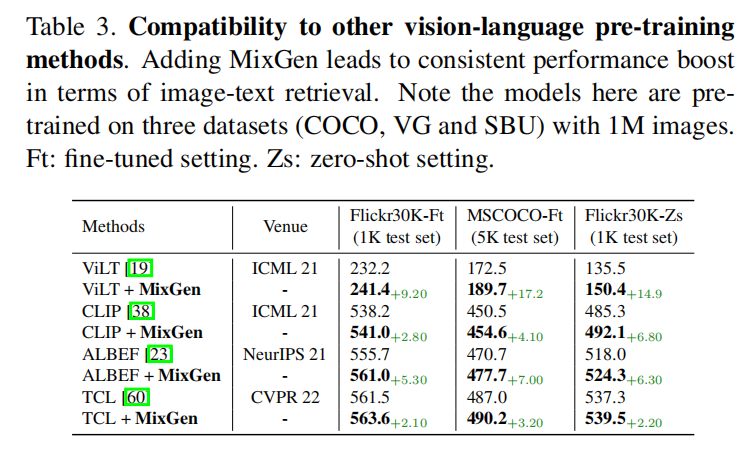
<HR align=left color=#987cb9 SIZE=1>