
论文地址:Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
从论文图1来看很难识别出他们到底要干什么,是要亲过还是没亲过,以及接下来的走向通过单一的视频帧都很难预测,只有理解上下文后才能很好的预测。
但是现在即使是Kinetics数据集也是存在这样的缺陷的,它的数据集预测中间的某一帧仍然能达到很好的效果,这就使得模型或许不要很好的时序建模信息就能进行预测。
所以到现在大家也没能想到一个很好的方式去构建一个能让模型学习时序信息的数据集,去处理长时间复杂的信息,从而拓展到各个方面
Kinetics和I3D:视频理解的新数据和新模型
Abstract
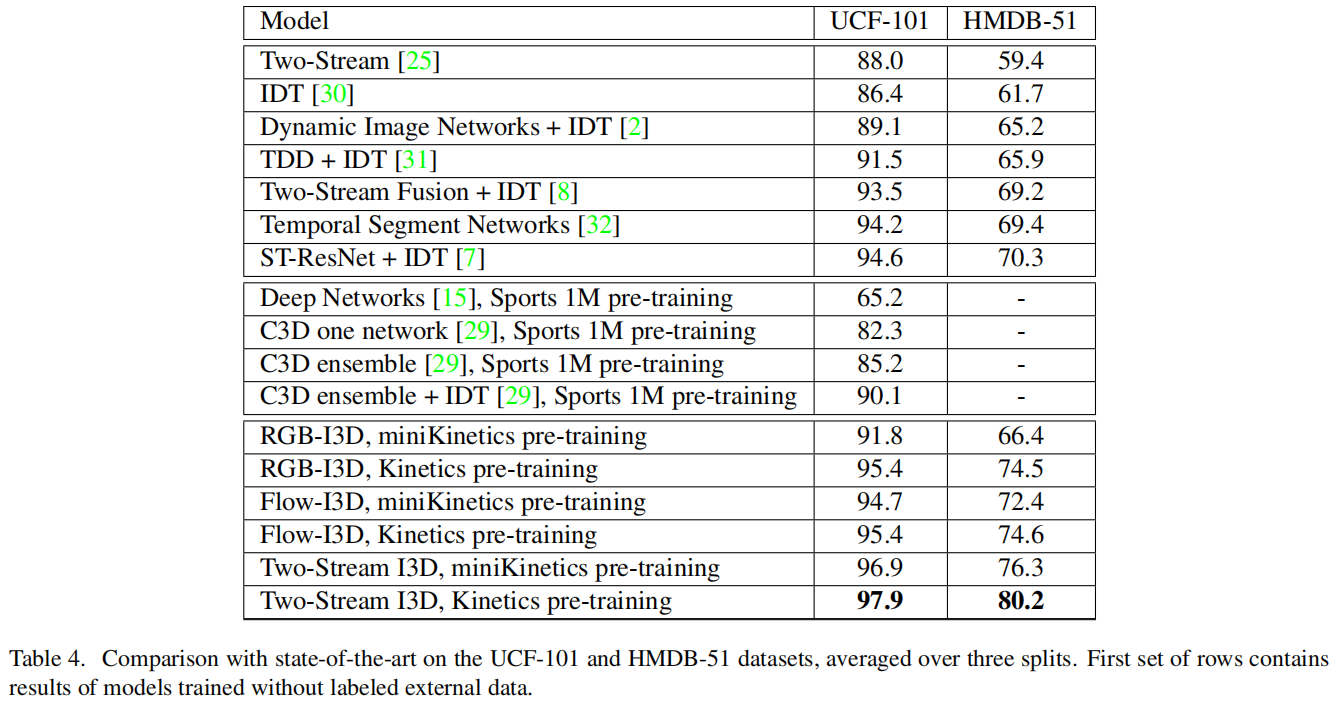
视频领域缺少好的数据集,导致大家很难很好的理解和识别出更好的框架。所以本文提出了一个又大又好的Kinetics数据集,又提出了一个叫I3D的模型,在HMDB-51达到80.2%和UCF-101达到了98%,基本把这个两个数据集给做没了
I3D的重点还是在于这个I,也就是Inflate的操作,作者是坚信一个好的预训练参数能带来很大提升,但是前面的方法都是2D网络,重点就变成了把2D扩充成3D而不改变网络整体结构
Introduction
ImgaNet带来的好处不止于可以训练深度神经网络,最主要的好处是我们可以直接从网络里抽取特征。
深度学习方法已经逐渐在分割、预测、动作评估,分类等等领域都取得了很好的效果,但在视频领域这种大规模训练再在小规模数据上迁移的方法还没有很好的展示出来,主要是因为没有很好的大规模数据集
构建一个新数据集之后第一步一般就是把之前的最好用最常见的方法拿来benchmark一下,这样可以
- 一是可以看一下之前的那些方法有哪些优点缺点
- 二是也可以验证一下新数据集的有效性。因为收集的新数据可能有自带的bias导致它过于简单或者过于难,使得没有人去用这个数据集
另外是作者是将双流和卷积结合一起,且已经不和传统方式做比较了
Model & Related Work
视频领域里从2017年到现在都没有一个定论,是使用2D,3D还是transformer,都没有固定的结论
当时有几种选择:
- 2D网络+一些操作(LSTM)等
- +光流
- 3D网络
经过大量对比作者就提出了自己的Two-stream Inflated 3D convNets(I3D)
- 用Two-stream的主要原因是发现加上了之后效果会好很多
- 用Inflated的主要原因是之前的3D网络的参数太大了,而且可以直接启用一些比较深的,好的2D网络,比如VGG,Inception,ResNet等,而且还不用很多的视频数据去训练了
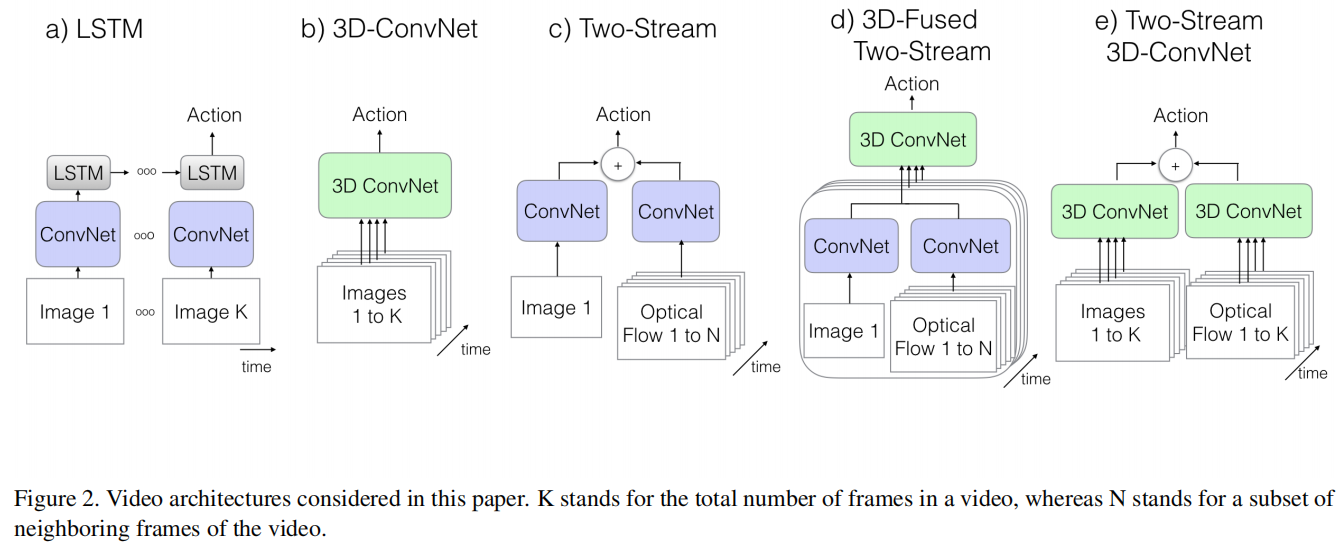
a)LSTM:
- 一张张抽特征,然后经过LSTM模拟时序信息,糅合起来用最后一个结果做分类
- 虽然听起来很合理,但实际上效果很一般
b)3D-ConvNet:
- 切割视频段,整个扔到网络里强行时空学习,用三维的卷积核,比如3*3*3。经过一些3D conv,3D pooling等然后返回一个特征,最后在这个特征上操作
- 作者表示数据量上来了效果还不错
c)Two-Stream:
- 提前把光流抽取好,蕴含了很好的视频时序信息表示,去学习到动作和光流的映射,而卷积网络本身就不需要进行时序建模
- 具体就是两个2D的卷积,左边是空间流,输入是一帧或者多帧,主要负责学习场景信息,右边是时间流,输入是光流图像,学习物体运动信息,最终根据特征给出结果
d)3D-Fused Two-Stream:
- 融合了b和c的工作,把双流的加权平均换成了3D ConvNet
e)Two-Stream 3D-ConvNet:
- 双流3D卷积网络,最后加权平均
The New Two-Stream 3D-ConvNet
Inflating 2D ConvNets into 3D
把2D网络很暴力的换成了3D网络,遇到一个2D的卷积核就变成3D,遇到2D的池化层就变成3D。这样就不用设计网络了
Bootsrapping 3D filters from 3D Filters
如何在2D的预训练好的参数弄到3D里面?
验证预训练好的模型来初始化我们自己的模型的时候,我们可以给定同样的输入,在原来的模型和初始化的模型上都来一遍。作者就把同一个图片反复复制粘贴N次变成一个视频,丢到3D模型里面让他们输出一致,保证3D模型输出一致需要除以N
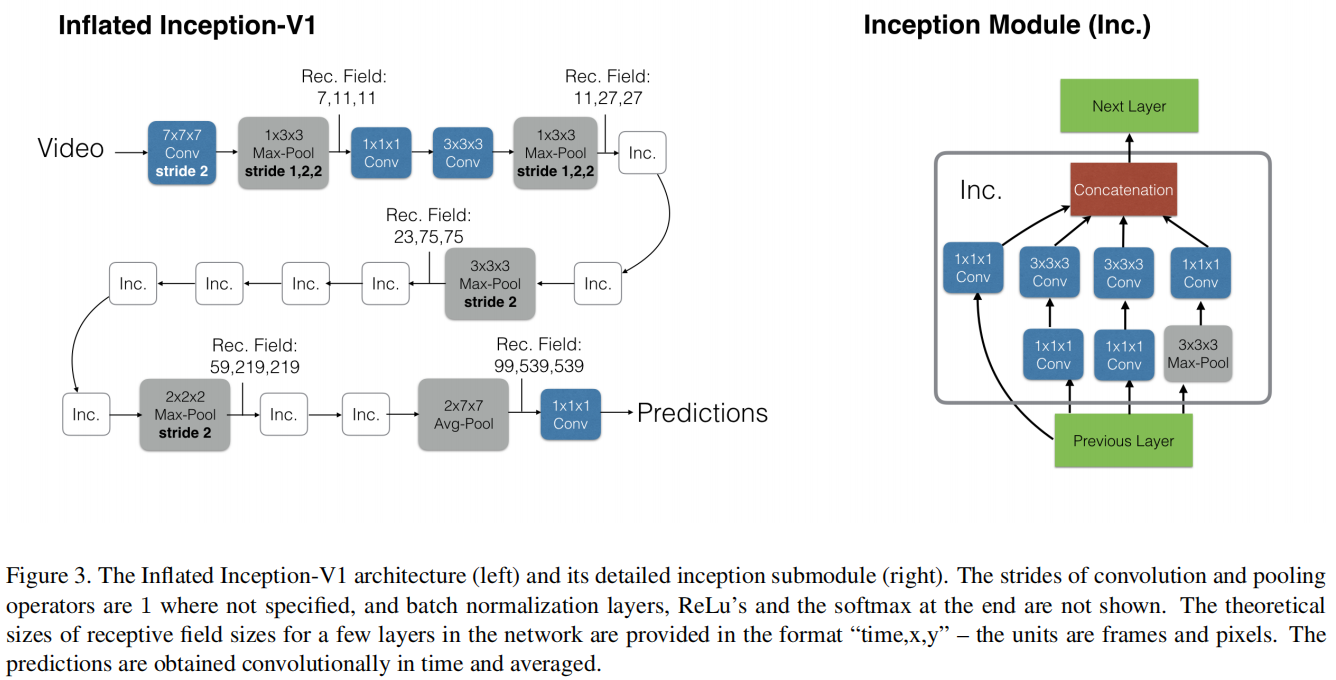
作者发现在时间维度上其实最好不要做下采样,就是本来3*3的卷积核按道理应该变成3*3*3的,但实际上作者是变成了1*3*3,stride也是从2*2变成1*2*2,这个意思就是输入是多少帧,输出也还是多少帧。只是在后面几个块做了下采样
Experiment
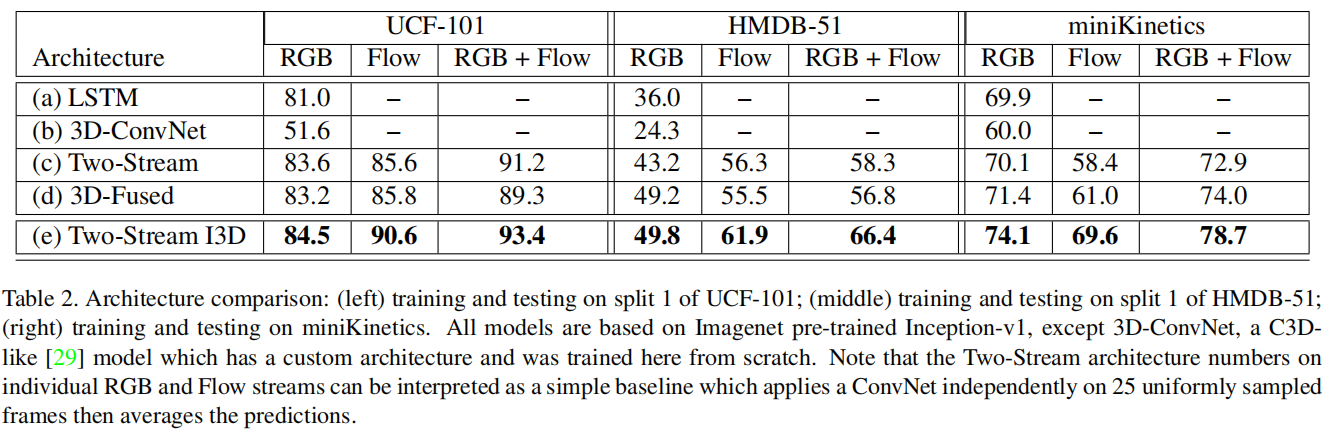
无论时间流空间流的效果是好还是坏,结合起来效果都能得到大幅提升
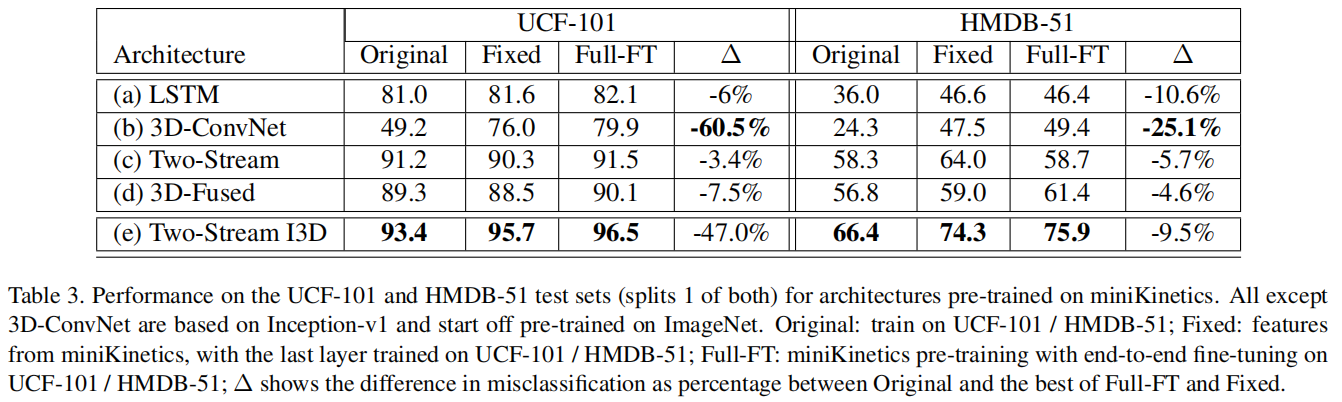
整体微调的效果一般更好
<HR align=left color=#987cb9 SIZE=1>