
DeepCom:NMT的方法+SBT+type替换
Abstract
DeepCom使用了NLP的技术学习大规模语料并从中生成注释,使用神经网络分析Java方法的结构信息,使用机器翻译的评价指标
Introduction
软件开发与维护领域,花了59%时间在理解代码上,所以代码注释有必要
过去的模板式和启发式方法缺陷在于:
- 标识符和方法命名不当时难以提取出准确的关键词
- 依赖于检索相似度代码段和这种相似程度
作者把代码生成问题看作NMT问题的变种,从程序语言翻译到自然语言,与Code-NN只对注释建模不同,作者对代码和注释都建模了,与传统的机器翻译问题相比,本文任务挑战如下:
- 代码有结构:如何用上这种丰富的结构信息来推进现有的NMT方法
- 词表:自然语言就30000个常用,但代码上二十来万很正常,因为有一堆标识符啥的
针对结构问题使用了SBT方法来遍历AST
针对词表问题用它们的类型来替代具体的词或
Proposed Approach
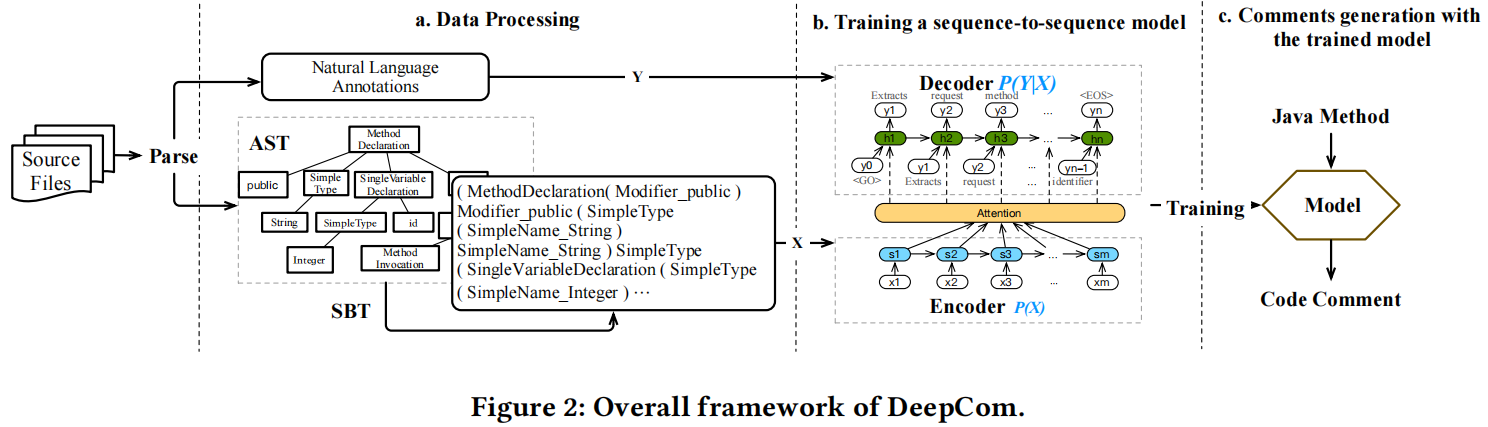
Sequence-to-Sequence Model
编码器都是带注意力的LSTM
Abstract Syntax Tree with SBT travesal
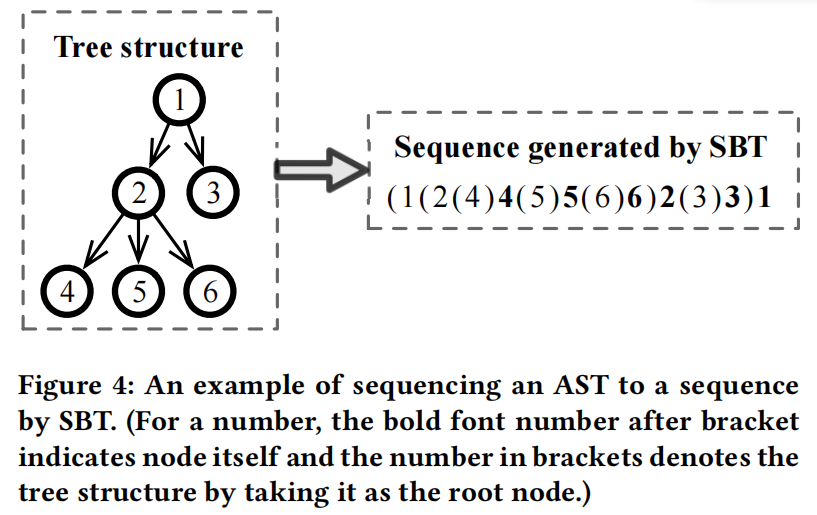
-
从根节点开始,首先使用一对括号来表示树结构,然后将根节点本身放在右方括号的后面,即(1)1
-
接下来,遍历根节点的子树,并将子树的所有根节点放入括号中,例(1(2)2(3)3)1
-
遍历每个子树,直到遍历所有节点并获得最终序列(1(2(4)4(5)5(6)6)2(3)3)1
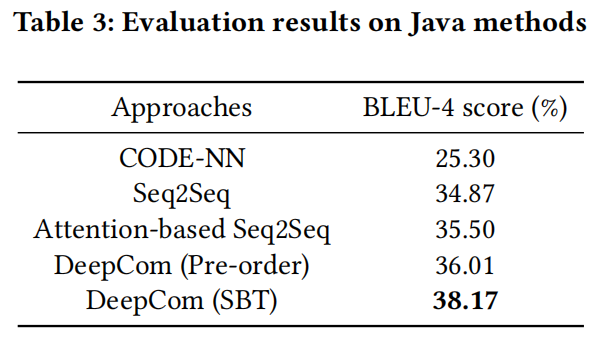
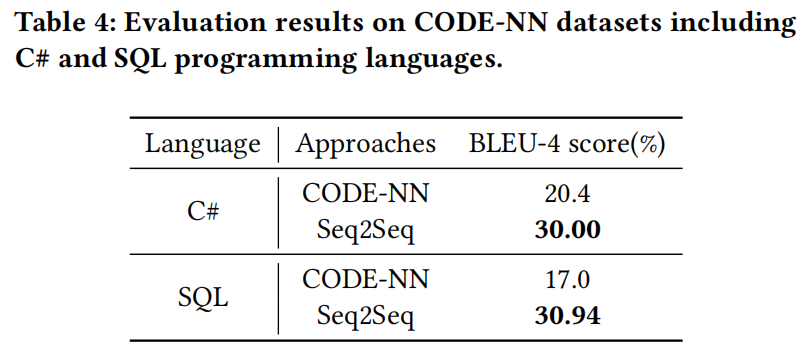
Experiment
<HR align=left color=#987cb9 SIZE=1>