
论文地址:Impact of Evaluation Methodologies on Code Summarization
论文实现:https://github.com/EngineeringSoftware/time-segmented-evaluation
这篇文章对评价方法数据集分割进行了思考,我认为很有启发性
time segmented:按时间戳划分数据集
Abstract
目前人们将数据集分割成训练集,测试集,验证集的方法还没有得到有效研究,所以作者提出一种基于时间戳的数据集分割方法,并将这种方法与常见的混项目和跨项目分割进行了比较,以及介绍了这种方法实际落地场景
Introduction
尽管深度学习的数据驱动方法产生了很多新技术,但是对于评价方法还是没有过多研究
基于时间的数据集在软工里面是有意义的,比如新的代码摘要往往会收到老的摘要影响,但先前的工作往往假设数据是独立同分布的,这就可能导致模型数值膨胀或者实际应用时产生误解
比起不管代码是什么时候写得就直接评估生成注释(批处理方法),一个更现实的场景是连续使用模式的用例,在一个时间戳训练的模型在后面的时间戳进行评估测试(连续处理方法)
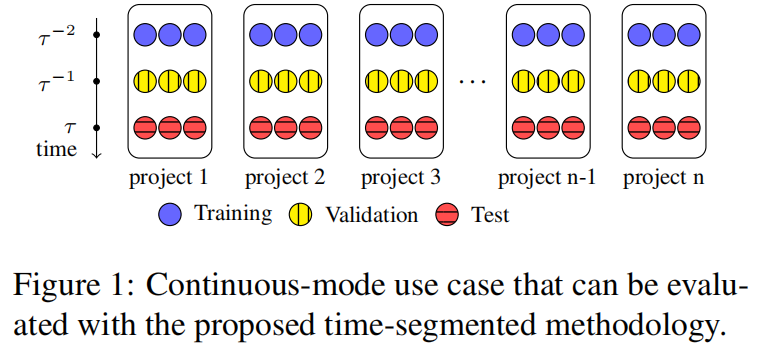
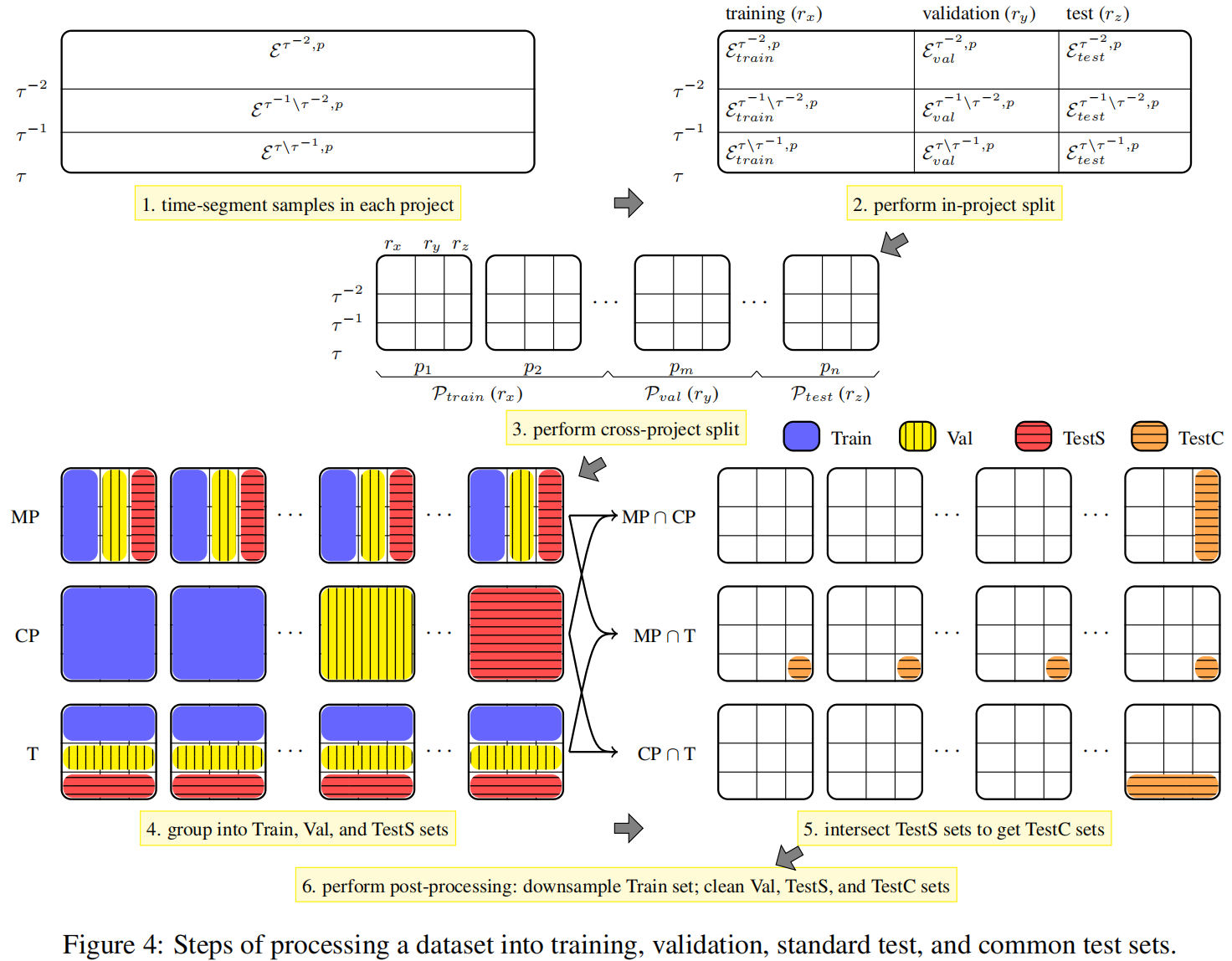
按时间段分割数据集
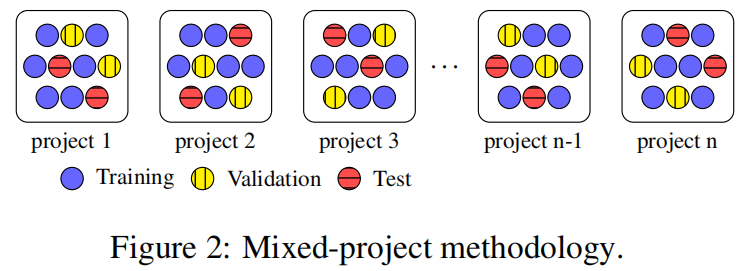
混项目分割数据集
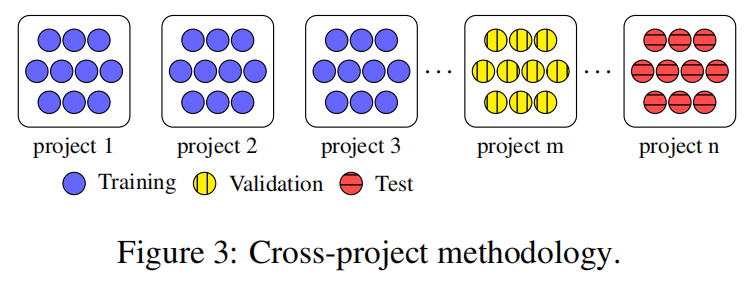
跨项目分割数据集
作者指出,我们需要更准确的选择评价方法来报告ML模型的结果,要符合目标任务和使用方法
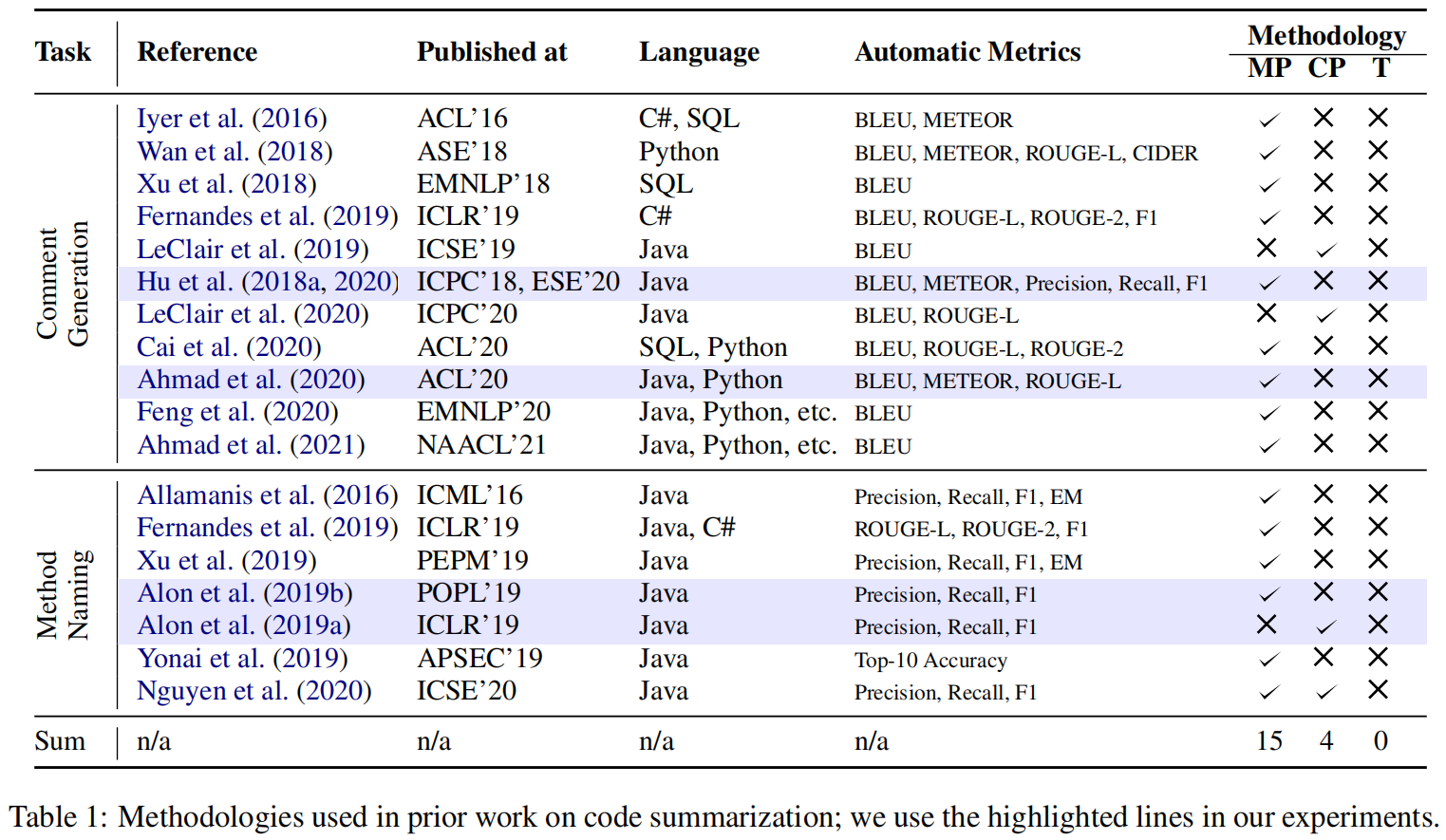
Use Cases
先前的ML模型只是为了实验,没有描述和注重用例场景,我们需要关注开发者最终是用怎么使用这些模型的,所以作者介绍了一些用例,全是假设的,俗称编得
对于写了一点注释的就用混项目,什么注释也没写就跨项目,同一时间写了注释的就用时间分割
Application of Methodologies
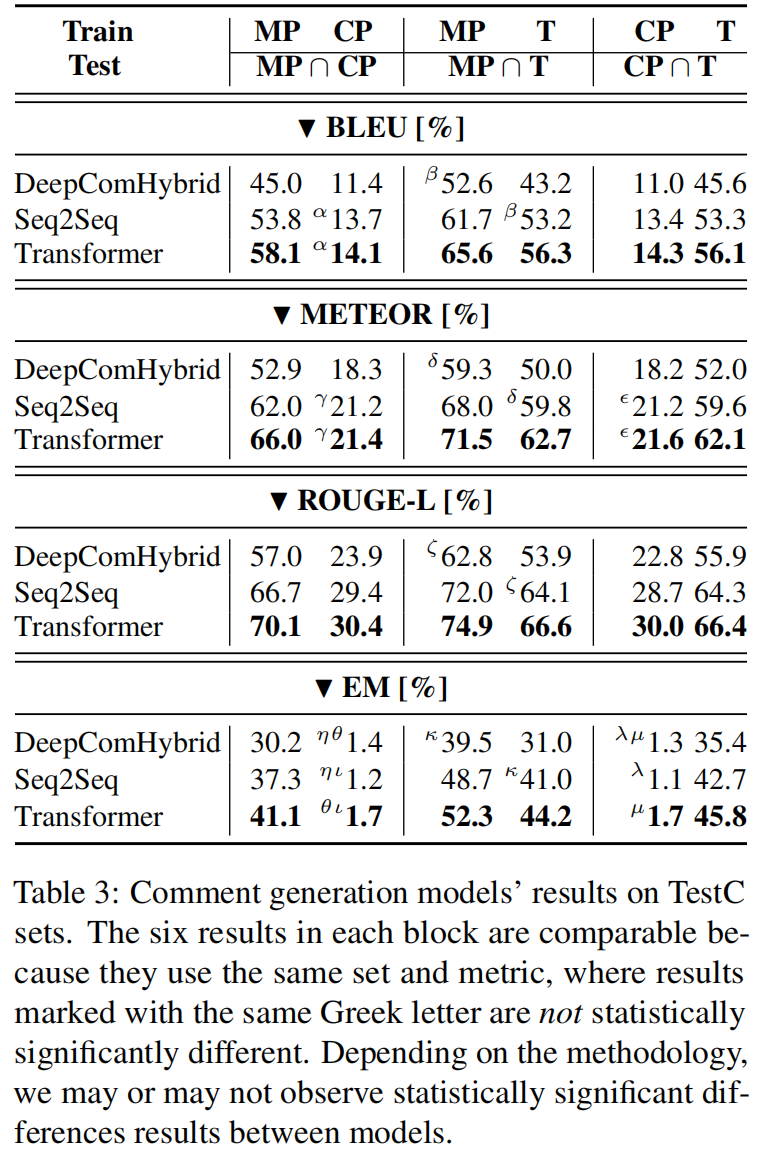
Experiment
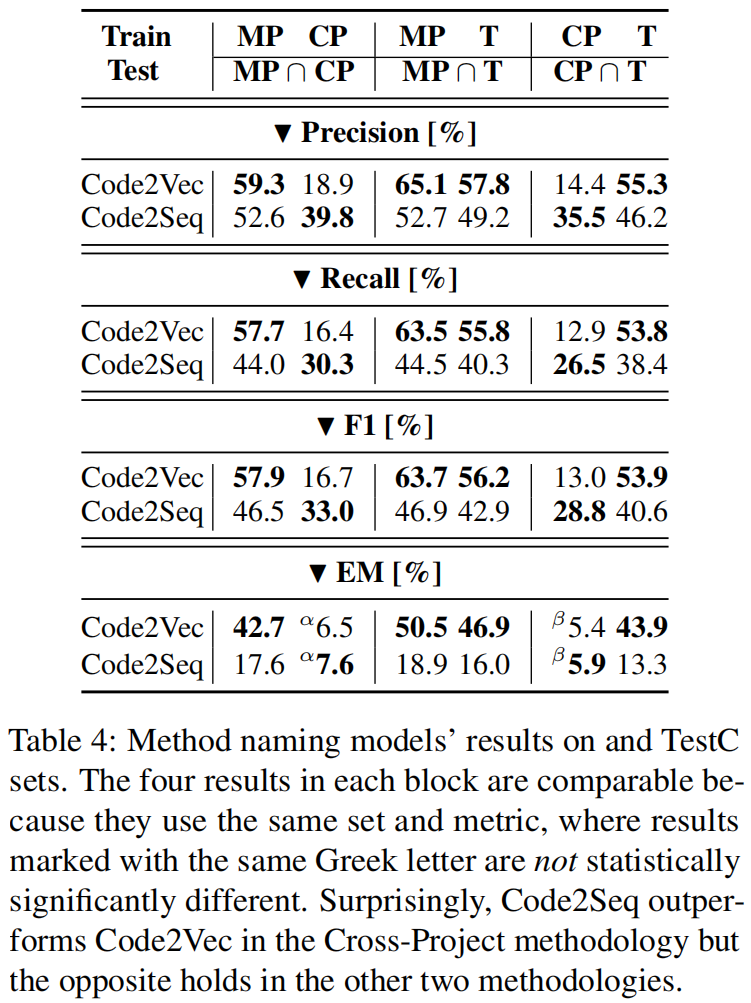
Future Work
Methodologies for Other SE Areas Using ML Models
将本方法从代码摘要任务迁移时只需要针对输入和输出进行修改就行,比如对于commit message 任务,把“(code, commnet)对”换成“(code change, commit message)对”就可以
Other Use Cases and Methodologies
跨项目连续模型用例:在 $\tau$ 时刻训练时不使用之前同项目的数据,而是使用别的项目样本,从实用性角度来说可能要差一点,但是从评估角度可能更能验证模型的泛化能力
在线连续模型用例:在 $\tau$ 时刻训练时不摒弃在t时刻之前的模型,也不是从0开始重新训练,而是使用在线训练方法,使用 $\tau^{-1}$ 和 $\tau$ 之间的数据
<HR align=left color=#987cb9 SIZE=1>