论文地址:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer:层级式的Transformer,使用了Patch Merging和移动窗口
-
ViT通过打patch,全局的自注意力操作来达到全局建模能力,但对多尺寸的把握会减少。在CV的下游任务中,多尺度特征很重要。Swin通过window来做local attention,滑动窗口来变相实现对全局建模,使得窗口和窗口可以交互。既省内存,效果又好
-
在CV和NLP模型大一统方面,ViT做得更好,因为它不需要先验知识,不用加内容即可在两个领域效果都不错。而Swin利用了更多的先验知识,类似于CNN的滑动窗口
-
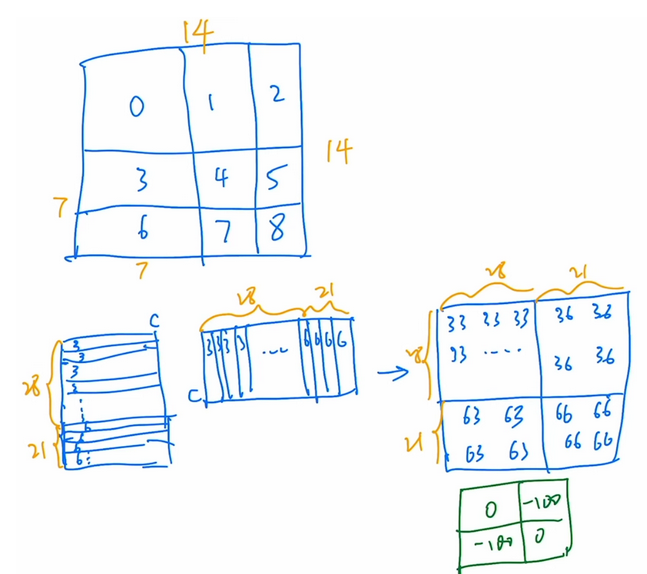
Patch Merging:类似于卷积的操作

-
移动窗口:基于窗口和移动窗口的自注意力机制,可以减少计算量的同时增加模型全局能力
-
提高移动窗口计算效率:采用masking掩码方式;没有用绝对位置编码,而是相对位置编码
5.1 因为移动窗口后可能会增加patch数,形状不一的patch没法直接丢进去,但直接Pad 0无形中也是增加了不必要的计算量
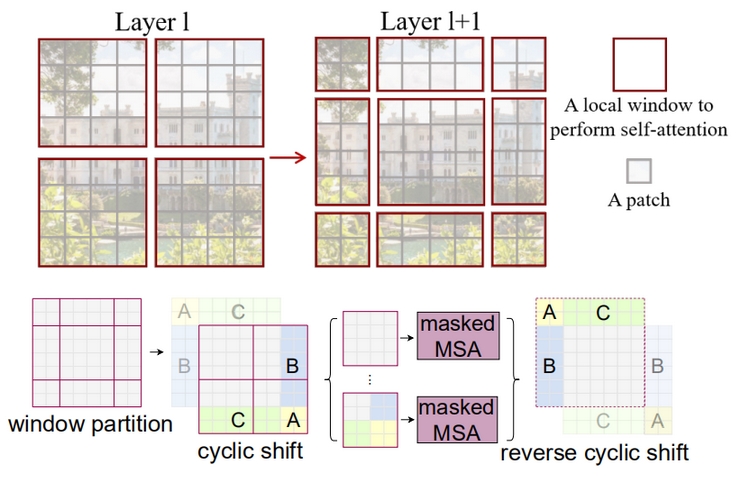
5.2 于是分割填补,同时部署于同一区域的patch不做自注意力计算,即采用masked MSA,然后还原图片,避免图片一直位移