论文地址:Learning Transferable Visual Models From Natural Language Supervision
CLIP:单模态正样本换成多模态,用文本提示做迁移学习
Abstract and Related Work
-
CLIP 强大的一个主要原因是 OpenAI 收集了4亿个图片和文本的配对,打破了固定类别标签的做法。
-
彻底摆脱了 categorical label 的限制,无论在训练还是在推理的时候,都不需要一个提前定好的标签列表,任意照片都可以通过给模型喂不同的文本句子从而知道图片里是否有感兴趣的物体,也延申出了一些很有意思的工作。
2.1 StyleCLIP:CLIP + styleGAN,文字上的改变引导图片的生成,code
2.2 CLIPDraw:CLIP 预训练模型指导图像生成,做几步 gradient descent 就可以生成简笔画图像
2.3 物体检测和分割:检测出新的类,比如不仅识别出玩具,还能识别出这是什么颜色的玩具
-
直接做 zero-shot 的点太低,11.5%,即使大家知道做有类别的这种预训练泛化性太弱了,依旧没人跟进,于是有人寻求图片和文本的中间地带。
-
例如从 Ins 带有 hastag 的数据学习,或者从 JFT-300(类别一万多) 的标签学习,都算是从自然语言中学习图像特征的方法,但是多是在亿级规模的数据上训练,这说明不是类似 CLIP 的方法不行,而是数据不够大,尝试了8个模型,横跨2个数量级,且发现效果和规模成正相关。
-
即使预训练的模型训练好了之后把它冻住(Linear-Probe),只抽特征训练最后分类头训练分类任务也比 ImageNet 上的效果好,而且计算高效
Method

-
为什么要用自然语言信号来帮助训练:
1.1 不用标注数据,筛选类别,请理数据,现在只用文字和图片的配对。而且因为信号是个文本,而不是n选1的标签,模型的输入和输出自由度大很多
1.2 因为训练的时候把图片和文字绑定在一起,因此现在学习到的特征实际是一个多模态特征而不是简单是视觉特征
-
造大数据集,有4个亿,数据增强都不用做了,就做了一个随机裁剪,也很难过拟合。也因为大,导致不好调参,就导致了 temperature 是一个很重要的超参数
-
不同的人对同一图片的文字描述可能差距巨大,所以用预测型任务预训练模型训练很慢,而将任务变成图片和文字配对任务就似乎简单很多,这样不需要逐字逐句预测文本,训练效率提高了4倍
-
发现无论是 none-linear 还是 linear 投射层都对结果没太大关系(none-linear在SimCLR提了10个点),可能只是用来适配纯图片的单模态学习
-
模型可以选择 ResNet,也可以选择 Transformer
Experiment
-
之前的无监督或无监督的方法主要研究特征学习的能力,目标是学习泛化性比较好的特征,比如MOCO,SimCLR,DINO等,但应用到下游任务时还是需要有标签的数据进行微调,能不能有一种不用调的
-
zero-shot 推理
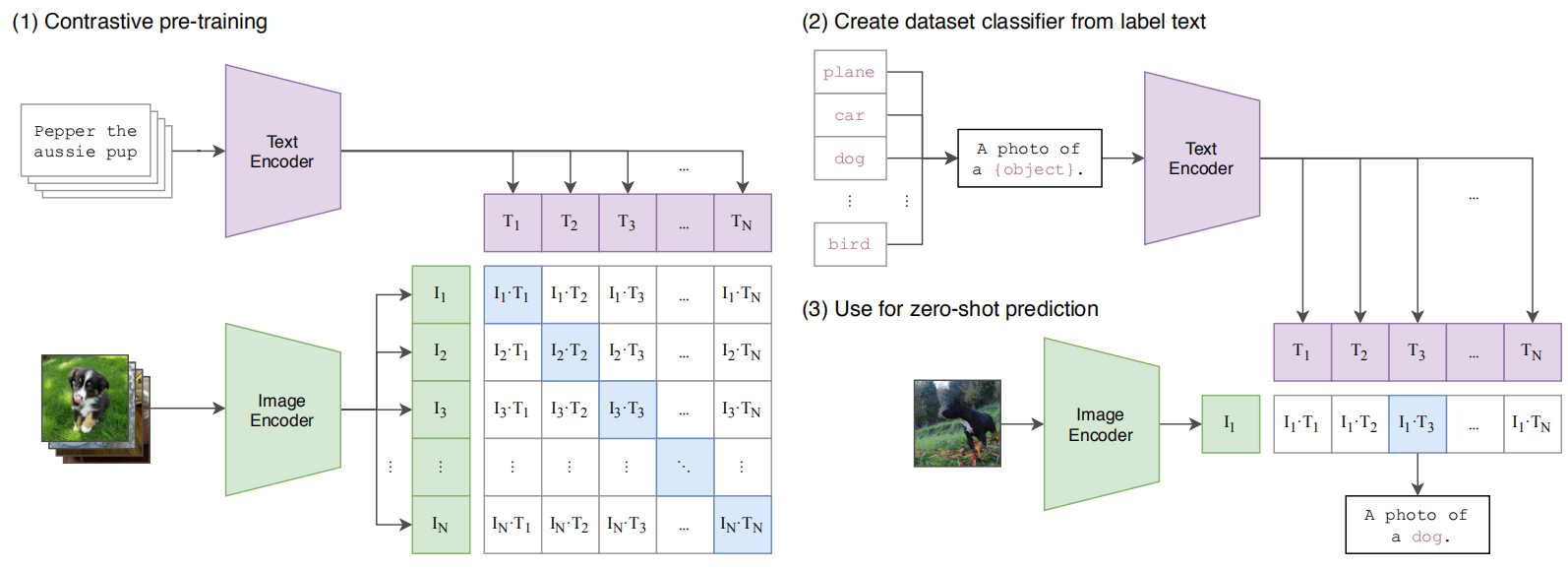
图片经过编码器,文字经过编码,计算余弦相似度后 softmax 得到最终结果,例如 ImageNet 的分类任务就是有1000个句子,类似于一个个去问图片“你是不是狗”,“你是不是猫”
-
prompt template:
作者用了80个“提示模板”,它起到的是一个文本引导作用,怎么样变句子也有讲究,所以 CLIP 后面也提出了 prompt engineering 和 prompt ensemble
3.1 为什么要做 prompt engineering 或 prompt ensemble 呢?
① 多义性,一个单词多个含义,只用一个单词做特征抽取肯定歧义;② 因为模型没有分类头,而且在训练的时候采用一个“句子”配对一个“图片”,所以在推理的时候要将“单词”扩展为“句子”,这样尽量避免降低准确率
3.2 prompt engineering
有更多的先验知识的情况下,可以把模板做得更谨慎,减小搜索空间,比如知道某个数据集全是动物等
3.3 prompt ensemble
多用几次模板,把结果综合起来,一般结果更好
-
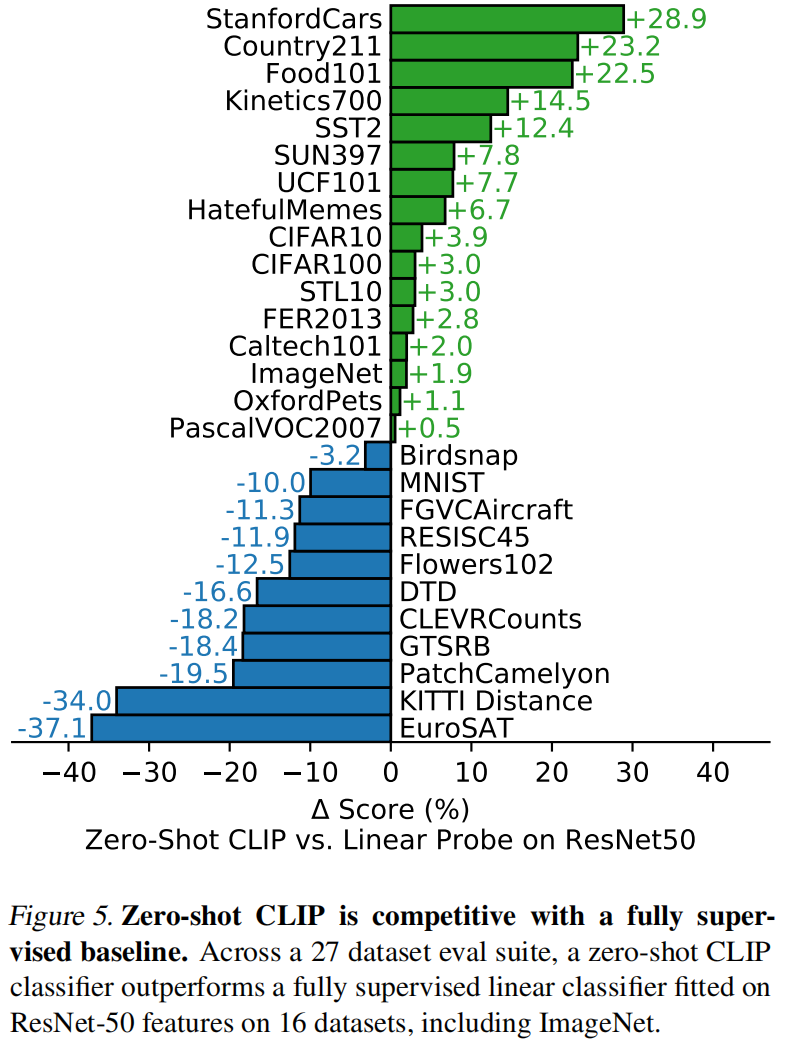
做了27个数据集测试迁移效果,证明了确实是广泛应用的。做分类的普通数据集表现更好,但对特别难的任务,比如计数(复杂),给肿瘤做分类(需要领域知识),直接做 zero-shot 就不是很好,做 few-shot 更公平,其实发现甚至全部数据微调都是吊打所有模型
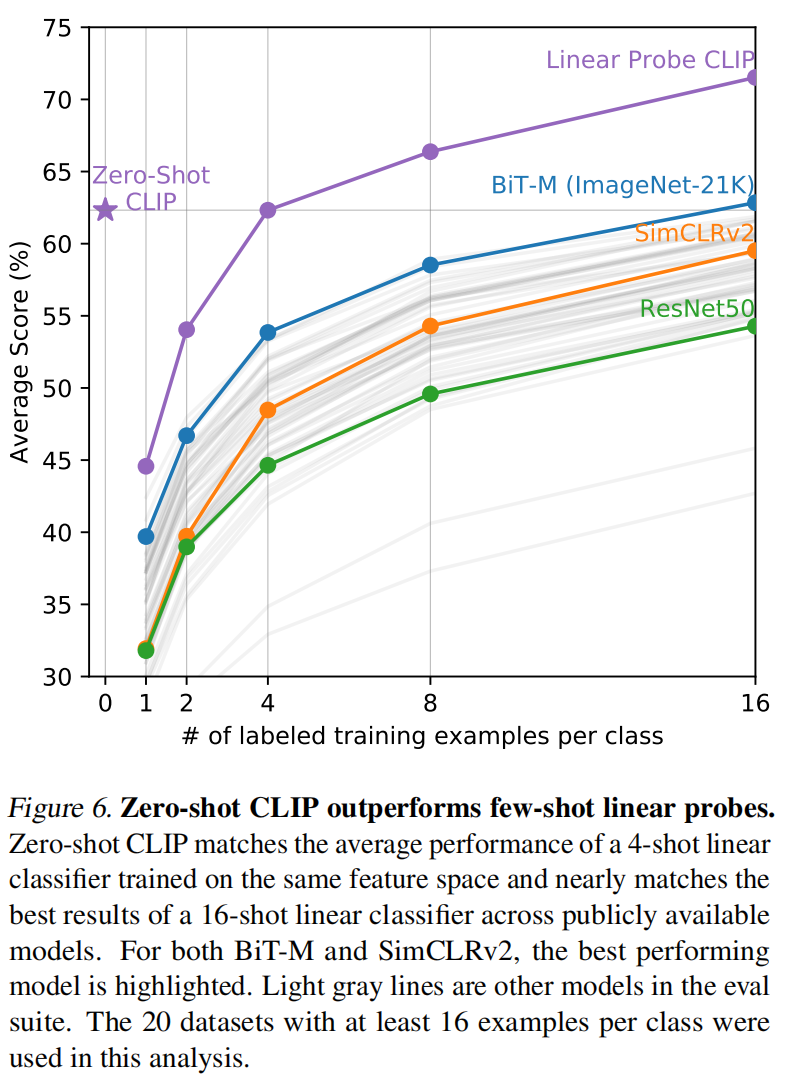
- 作者甚至做了人和 CLIP 的对比,找了志愿者对37类猫猫狗狗分类,志愿者是没看过种类示意图,还做了 one-shot 和 two-shot 的实验
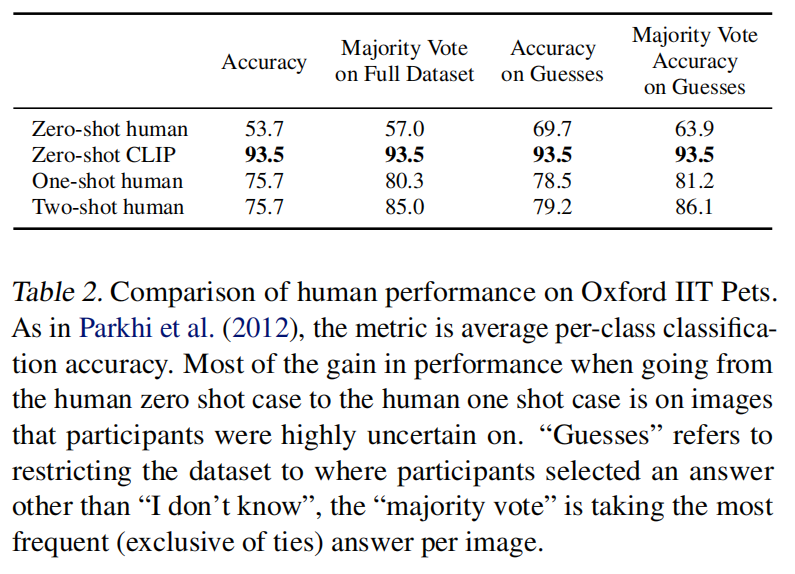
- 同时也做了人和 CLIP 对类别识别难易的对比,对人难识别的类对 CLIP 也难
Limitation
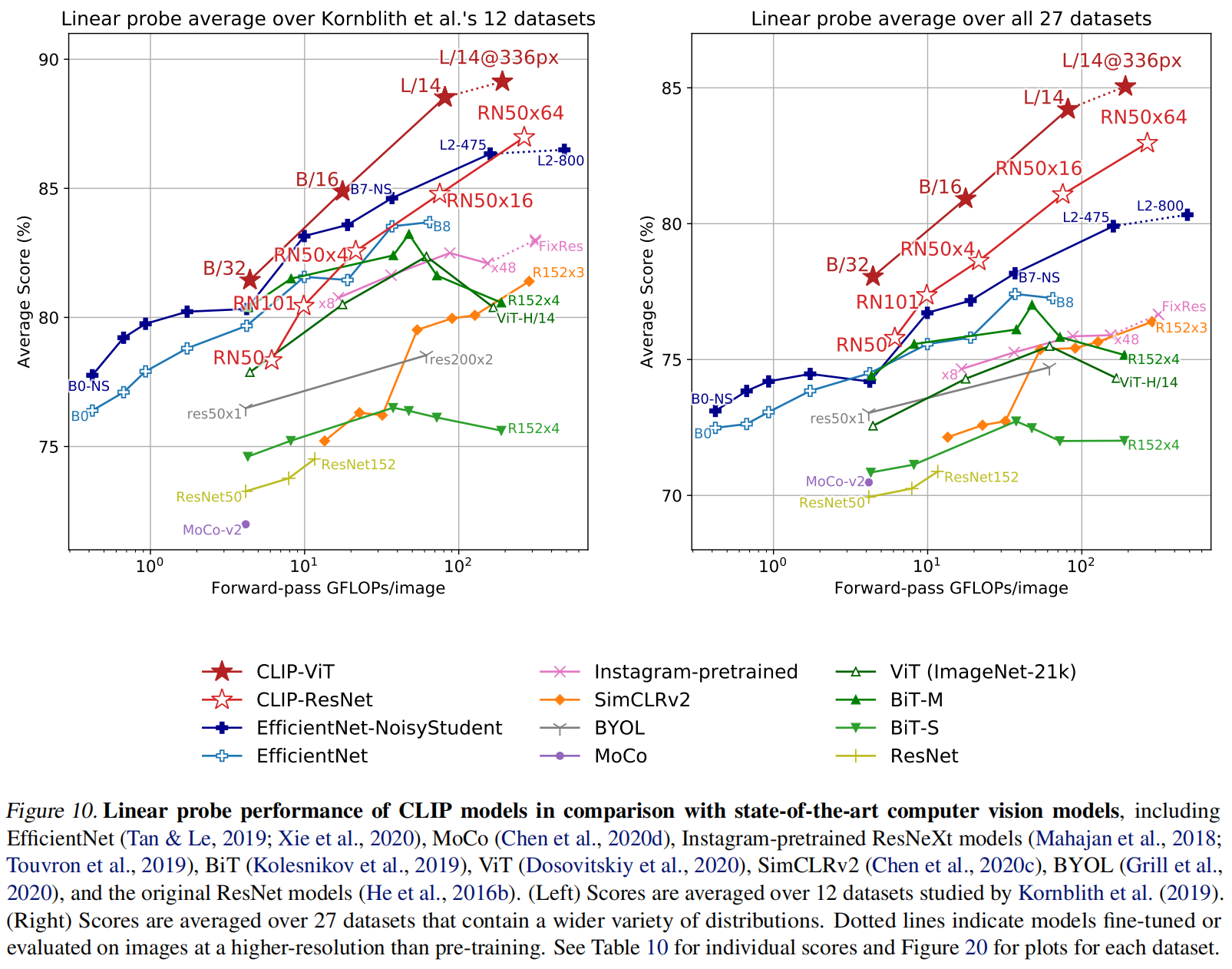
- 性能强是和 Res50 比较,实际上和各种 SOTA 比还是差了许多,估计得x1000才能达到。肯定需要新的方法在计算和数据的高效性上提高
- 在有些数据集上 zero-shot 的结果也并不好,比如细分类等,也无法处理抽象和难的任务,可能在很多领域 CLIP 和瞎猜一样
- 做推理的时候如果数据和训练的分布差距真的很大,泛化性照样很差。比如在 MNIST 这种甚至只有88%,一个线性回归都比它高
- 虽然可以做 zero-shot 任务,但还是在给定的类别里做选择,更灵活的方式是生成图像标题,这样都是模型处理,可以生成新输出(生成式模型),考虑有没有一种损失函数可以包含对比学习和生成式学习
- 对数据利用不是很高效,需要大量投喂,其实大概跑了128亿张图片。减少数据量得方法:数据增强、伪标签、自监督
- 在做下游任务时,不断用 ImageNet 带入指导,其实已经有偏见,也就其实不是真正的 zero-shot 的情况
- 数据从网上爬的,没清洗,可能有社会偏见等被不正当使用
- 其实很多工作用语言也无法描述,如果下游任务能提供一些这种训练样本也会很有帮助(few-shot),有时候多给了几张图片反而训练精度不如 zero-shot

