Coder:个体判别+对比学习出更健壮的向量
1. 简介
-
从大量代码段中抓取等效和不等效的挑战:
1.1 通过测试用例比较代码的启发式去自动标注代码段,这种方法有极大的程序执行开销
1.2 从GitHub等抓取,但这样增加了大量噪声,不是所有文档、注释都是语义等效的。比如Code2vec模型是专门用于方法名预测的,它在其他任务上迁移表现就不好,可能是由于学习到了不正确的代码匹配模式
-
代理任务:个体判别
这里的数据增强(program transformation technique)后的程序叫做“语义等效程序”,比如改变变量名,交换代码顺序等,要保证他们嵌入到相近的向量空间中

-
这是篇挖坑型文章,因为它说它是第一个在自监督代码模型中使用数据增强方式的
2. 相关工作
- 自监督学习方法不需要人为标注数据,只需要最小化正样本距离,最大化负样本距离即可,在CV和NLP都有很多应用
- 目前的深度模型多是AST、AST to Graphs、RNN变种等等一系列方法,但目前急需减少对大量标注数据的依赖,也迫使研究者去找寻更合适的方法
3. 方法
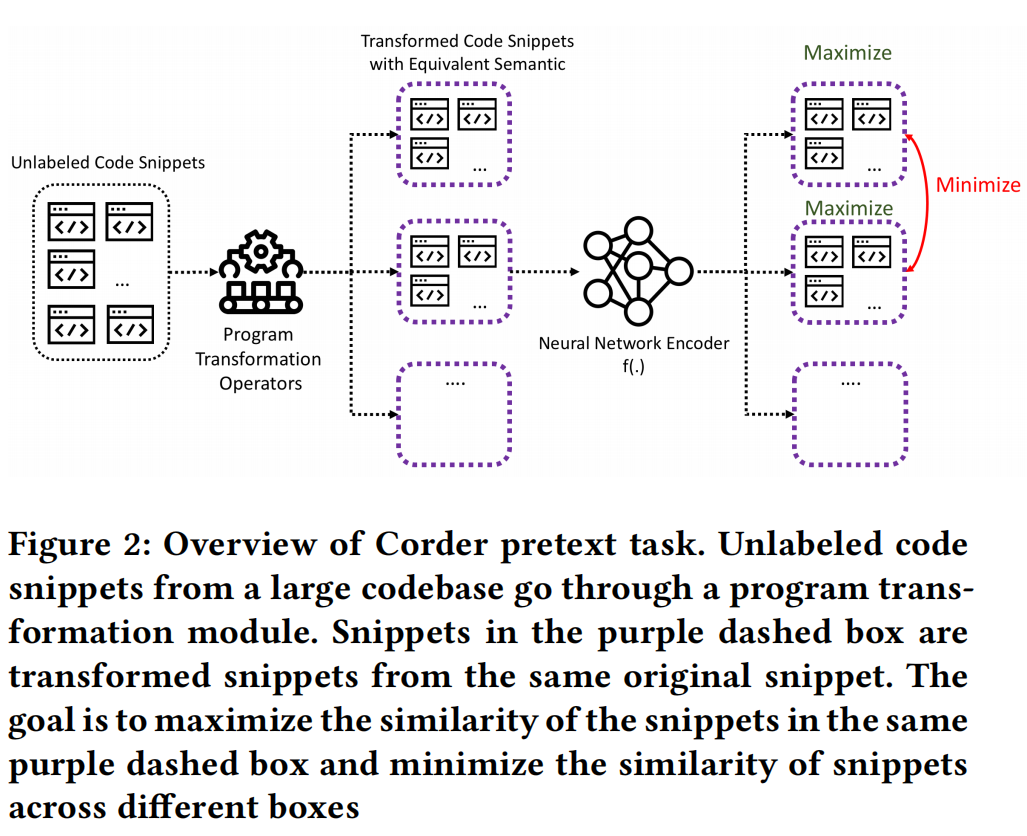
-
三个模板:① 程序转型模块;② 网络编码器;③ 对比损失函数
-
对于 program transformation technique,越精致效果越好。作者尝试了变量重命名、循环交换、switch到if等来做不同改变
2.1 变量易名(Variable Renaming/VN):
- 从变量名库中随机抽取替换,只改变文本信息,不改变AST结构信息,影响的是AST节点的特征
- 目的是增加对抗性样本使得模型更加健壮
2.2 无用声明(Unused Statement/US):
- 随机抽取代码块添加不适用的声明,增加了AST节点数
- 目的是希望模型能在节点数量不同时也能抓取相似性
2.3 声明移位(Permutation of Statements/PS)
- 交换互不依赖的声明位置
- 目的是希望模型能在子树在位置改变下也能抓取相似性
2.4 循环改变(Loop Exchange/LE):
- for 循环和 while 循环替代
2.5 条件改变(Switch to If/SF):
- 遍历代码找出 switch,并把子树都换成 if 声明
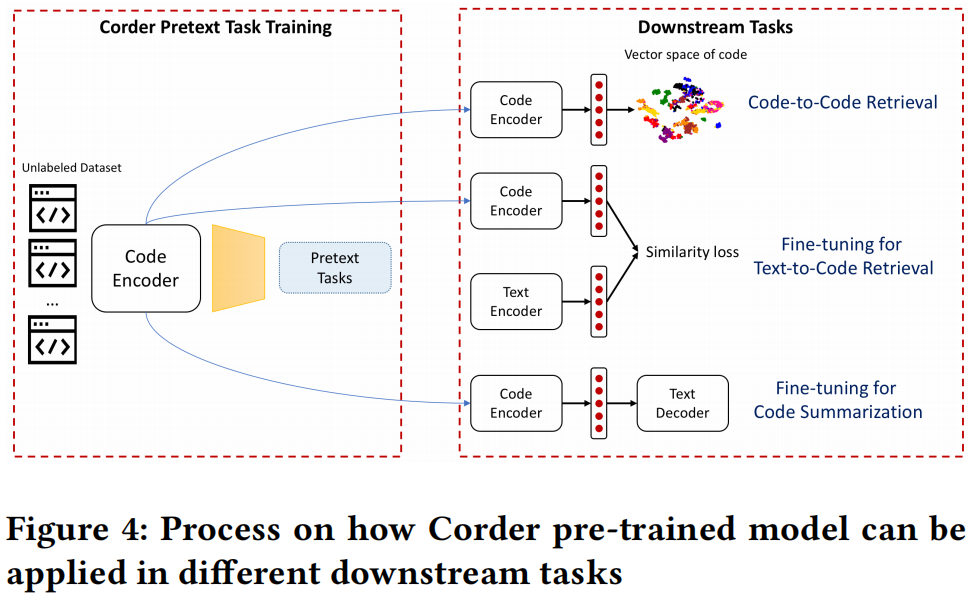
4. 用例
-
Code-to-Code Retrieval
主要用于大型代码数据库查找相似的代码,但目前的相关工作多偏向人工特征工程提取足够好的特征
用预训练好的编码器去将整个数据库抽成特征表示,用余弦相似度获取top-n最近邻
-
Text-to-Code Retrieval
给定自然语言查询,返回最语义相关的代码段
用两个编码器,一个自然语言编码器,一个源码编码器
-
Code Summarization
类似翻译,编码器-解码器结构
5. 实验
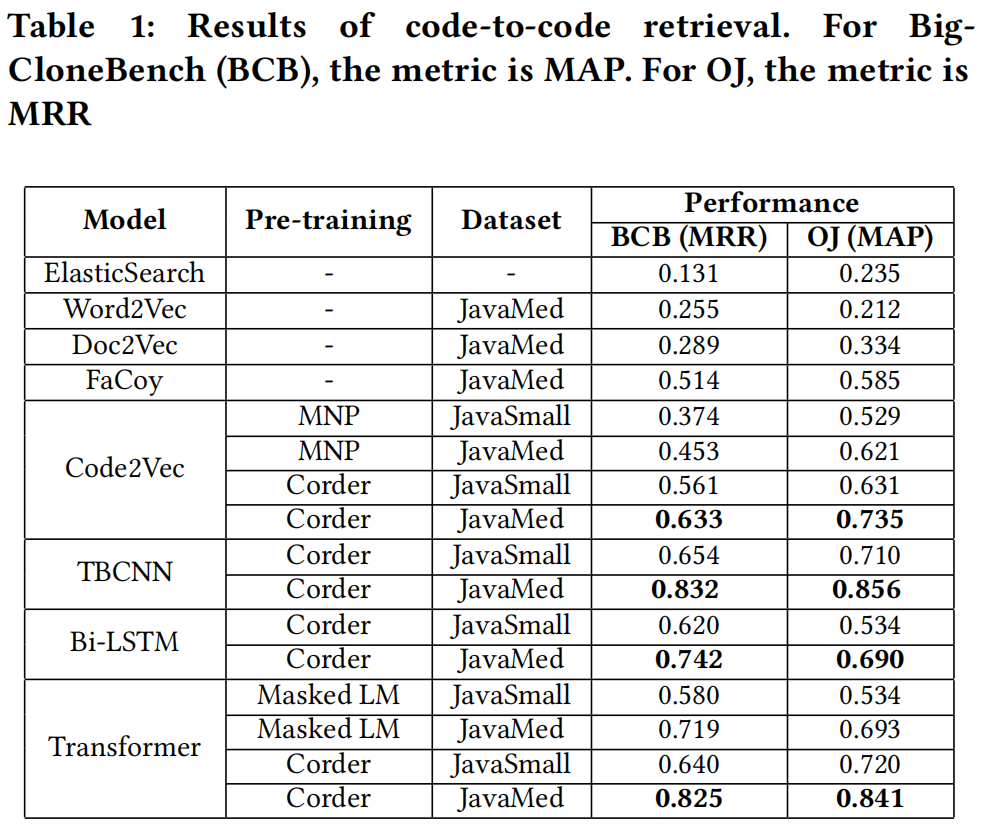
- 实验结果
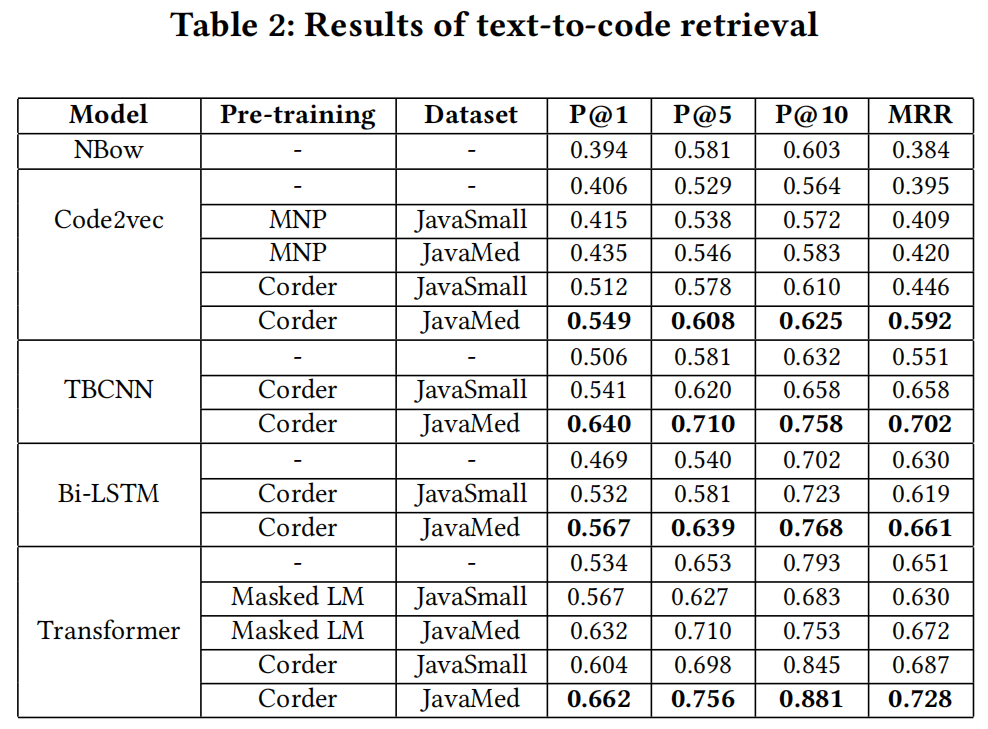
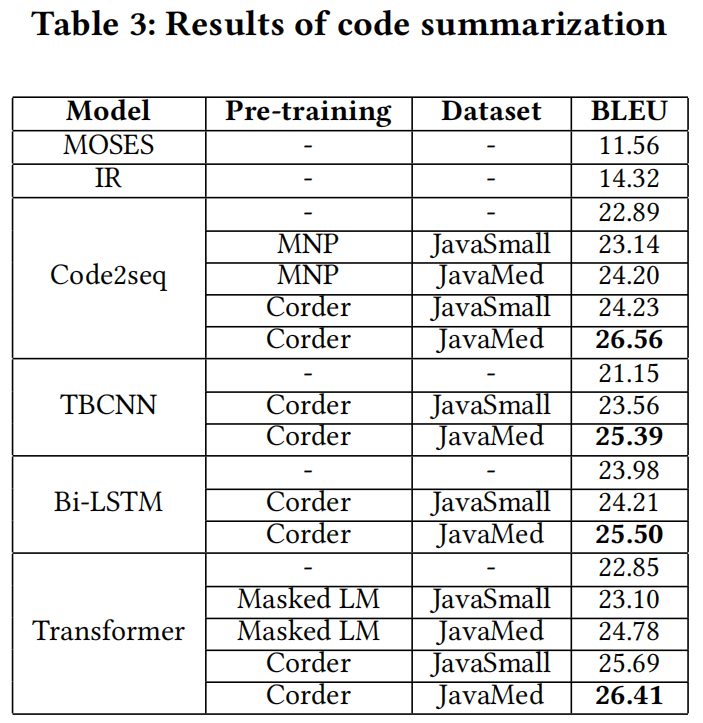
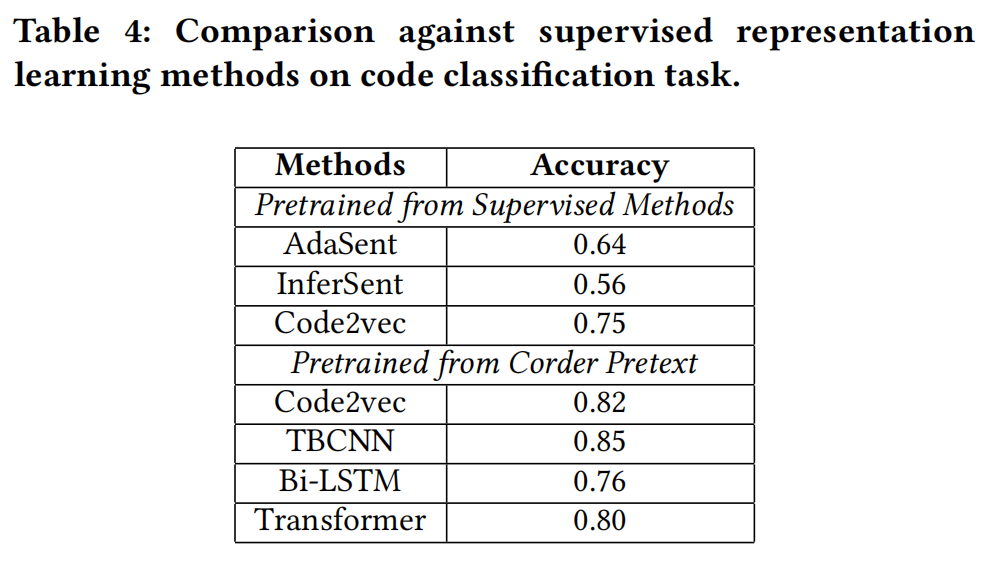
-
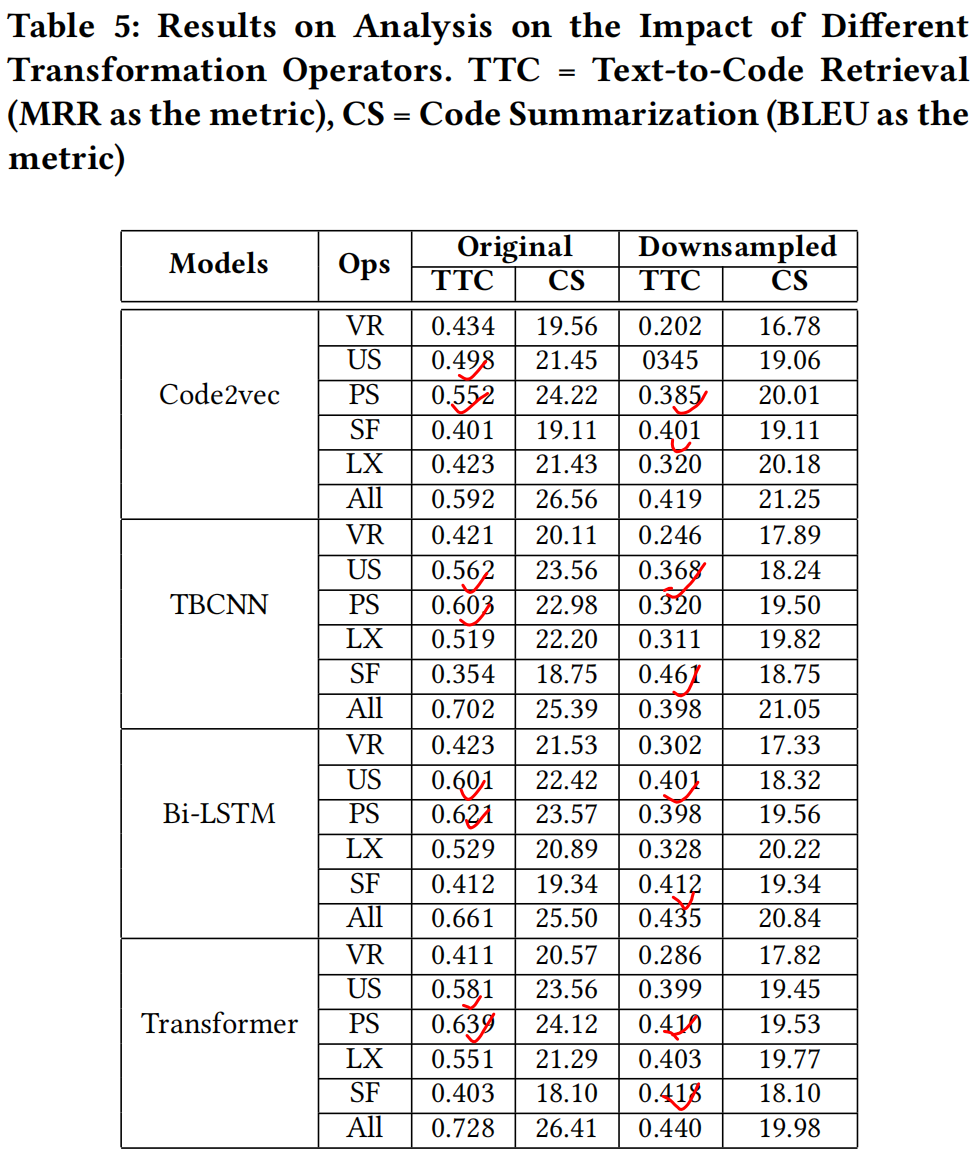
消融实验:
因为每种转型操作不一定对所有代码生效,所以建立了两种设置,① 原始数量;② 下采样了3213个片段针对VR、PS、US,是为了和最小的的SF数据3213保持一致
在原始模式下:PS和US最有效;在下采样模式下:SF和PS、US差不多有效,甚至更佳(我个人怀疑可能是因为SF在小数据下其实改动非常大,因为它对节点数、特征、结构都有影响)
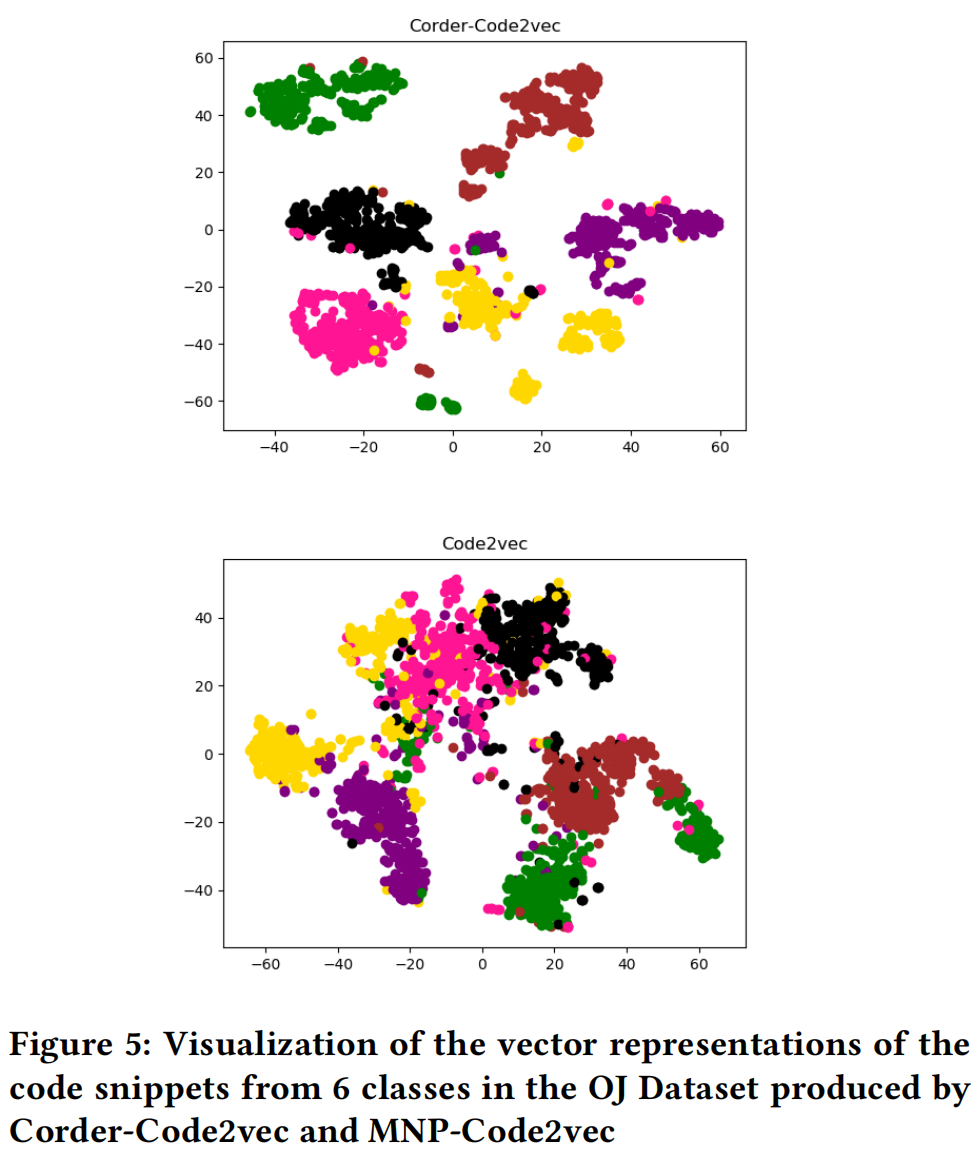
- Corder 学习出来的表示确实有区分度