论文地址:A Novel Neural Source Code Representation Based on Abstract Syntax Tree
ASTNN:将大AST拆分为小AST树
1. 简介
-
基于AST的神经网络两大缺陷
1.1 当树比较大和深的时候容易梯度消失,在 C 和 Java 中 AST 的最大节点数和深度分别为 7027/76 和 15217/192,使用滑动窗口等方法又易导致长距离信息损失
1.2 为了简单和高效将 AST 直接视作二叉树,损失了句法结构也加深了 AST 的深度,弱化了抓取更复杂的语义信息的能力
-
解决限制的方法
引入控制流和数据依赖图,使用图嵌入技术来表示代码,比如变量和函数的长距离依赖定位(PDG),构建代码块的控制流图(CFG)。前者非常依赖中间代码表示,对于不能编译的,不完整的代码段很难应用
-
于是作者提出了一种新的表示代码段的方法,它不需要代码段可编译,叫做 ASTNN ,通过将函数或方法的 AST 树分解为以句子为单位的小型AST树再分别embedding成向量后采用双向RNN网络来处理生成代码表征。这样即解决了深度问题,也解决了结构表示问题。
2. 模型
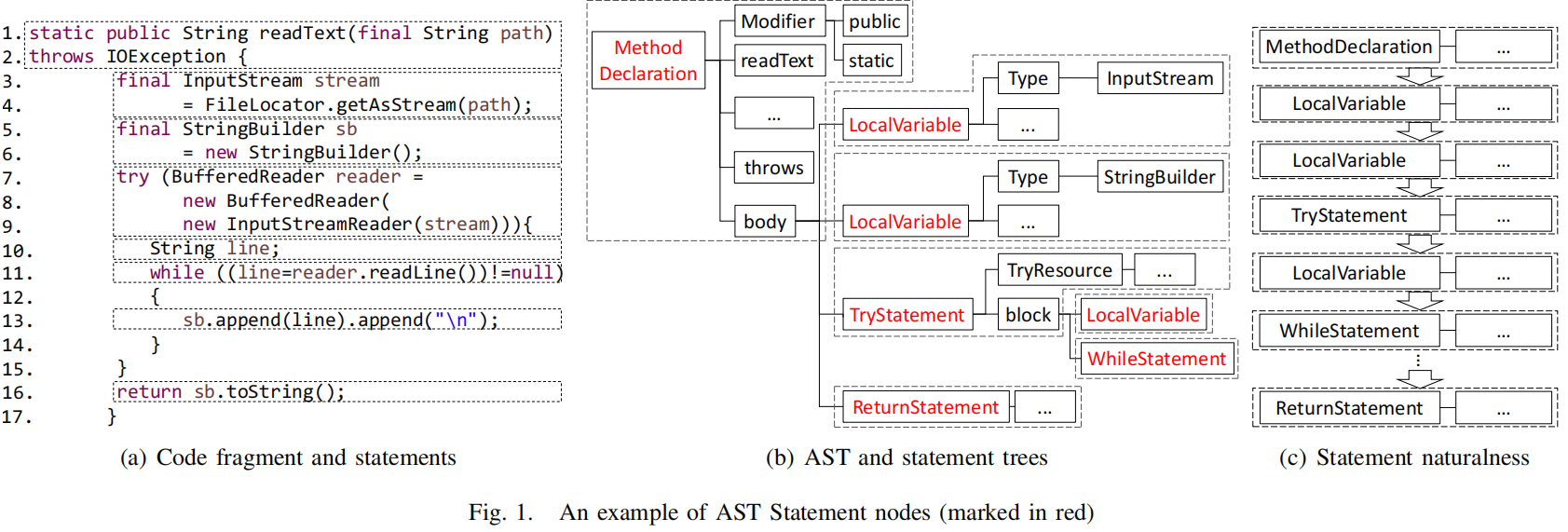
首先是如何对AST树进行拆分。本文按照句子的粒度进行拆分,首先先序遍历得到语句树序列S,则S中的每个s都代表这一个语句。对于嵌套语句而言,其由header和body组成,header类似try或while语句。这样以节点s为根节点的语句树就是s所有子节点的语句树的集合。
由上图可见,将示例程序分成了7个AST子树,每个子树代表一个语句,由header和body组成,得到子树先序遍历AST子树的节点,得到的节点序列作为ASTNN的原始输入,也就是作为后续RNN网络的原始输入进行表征提取。
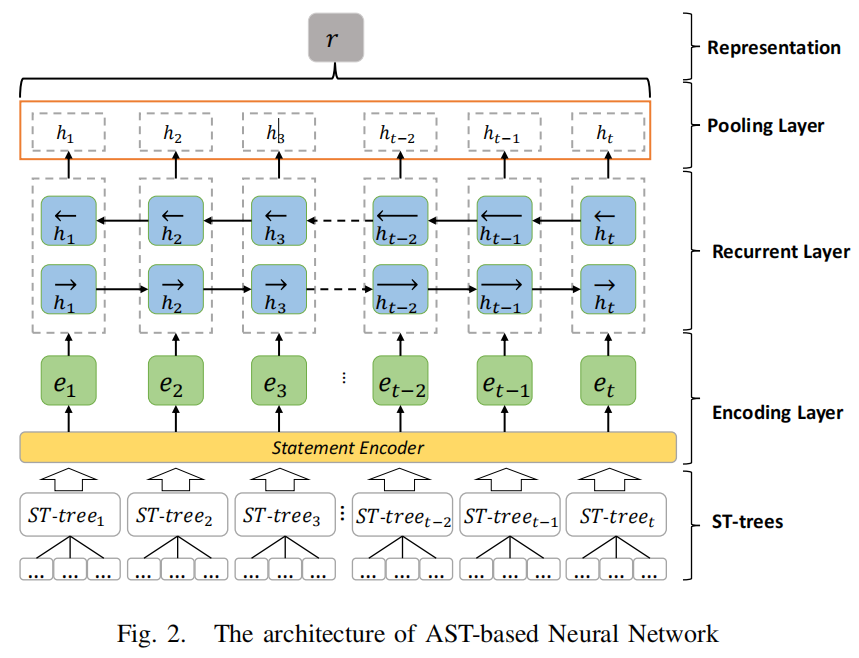
得到线序遍历的AST子树节点序列后,首先对每个单词进行embedding,之后如上图所示,接着不断的迭代递归的将当前节点的embedding作为新的输入进行计算,最终遍历所有节点得到AST子树对应的子树向量,整个过程可以看作是一个pooling过程。
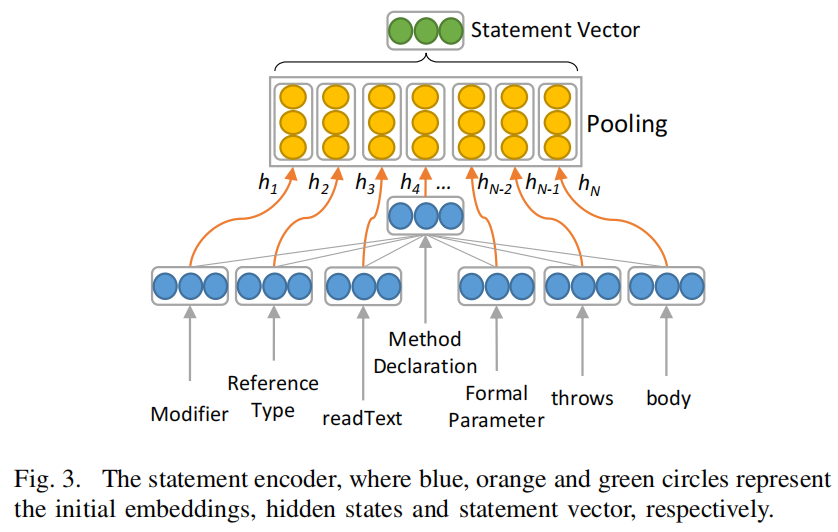
该图中的statement encoder相当于上图中AST子树编码结构,得到AST子树向量后,将其输入到RNN中,再经过一层pooling层得到最终的代码表征输出。
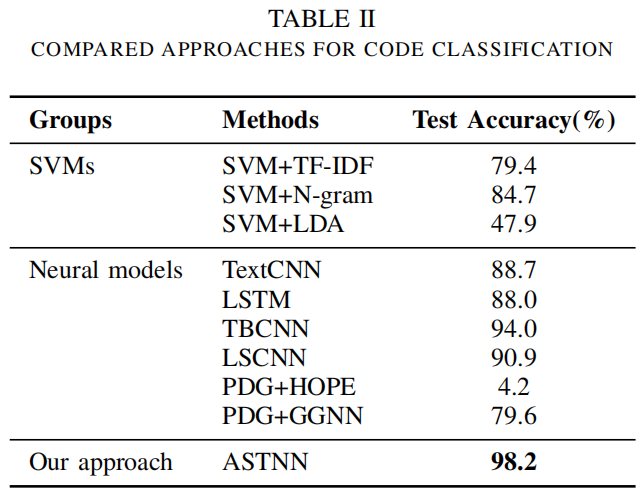
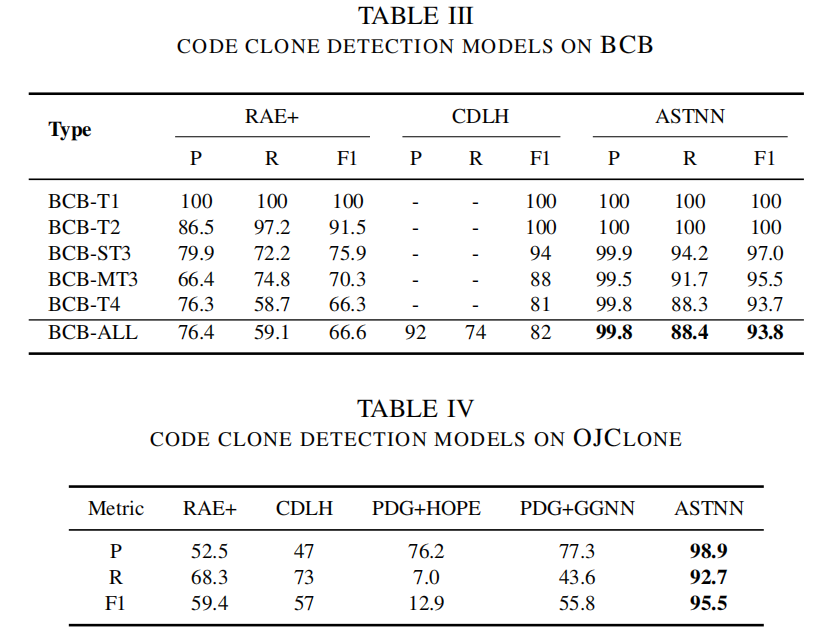
3. 实验