论文地址:Two-Stream Convolutional Networks for Action Recognition in Videos
双流卷积网络:空间+时间,视频处理开山作
神经网络开始难以学习到物体的特征,现在从传统方法的光流直接把抽取好的运动信息特征塞进去,让网络学习映射,提供先验信息或许能够大幅提高网络效果
Abstract
-
学到 appearance(空间) 信息和 motion(时间) 信息
-
贡献:
2.1 提出了双流网络,效果好了一大截
2.2 在少量数据上也能体现出不错的效果
2.3 弥补训练上的不足,提出 multitask learning 在两个数据集上训练骨干网络
Introduction
- 视频里的时序信息能够给图像分类提供重要线索,并且视频天生能提供很好的数据增强
- 简单粗暴的把数据丢进网络效果不好,甚至不如手工提取特征。于是作者发现手工方法都是按光流,能够很好的提取运动信息,于是提出双流,使用 late fusion 在 logits 上做合并
- 从人脑受到启发
Related Work
- spatio-teporal features 演变成了 3D 网络, dense point trajectories 演变成了双流法
- 如果把视频帧一张一张的输入 2D 网络,和一系列的视频帧叠加丢进 3D 网络或 2D 网络进行时空学习效果一样,比传统方法低了20个点。说明这种方法并没有抓取到动作和时序信息,也让大家意识到这种动作和时序信息的重要性
Model
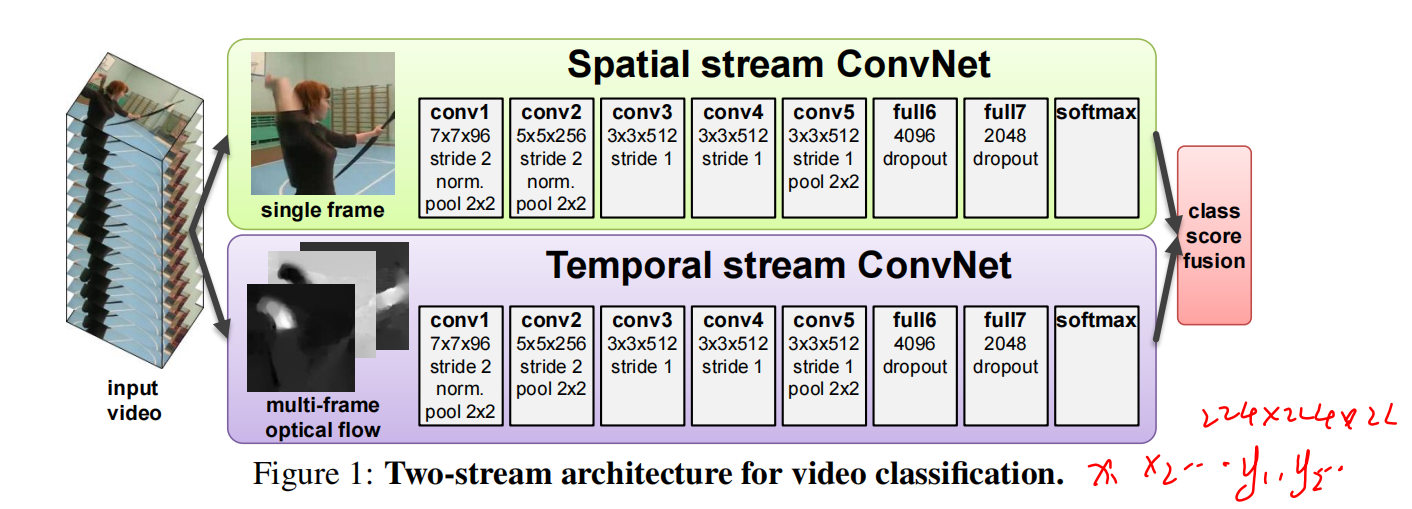
Spatial stream ConvNet
实际上是一帧一帧的处理,和视频关系不大,类似于图像分类,结果还是不错的。但这种静止的信息往往有很强的线索,如果用 ImgaeNet 上预训练好的模型来微调其实也很不错
Optical flow ConvNet

-
视频长度是 L 帧,那么得到的是 L-1 个光流图
-
如果把前后两帧计算的光流直接丢进 2D 网络,那就相当于做一个分类任务,作者认为这样意义不大。为了学习到这个时序信息,就把多张光流图叠加在一起,先叠加水平方向位移,再叠加竖直方向
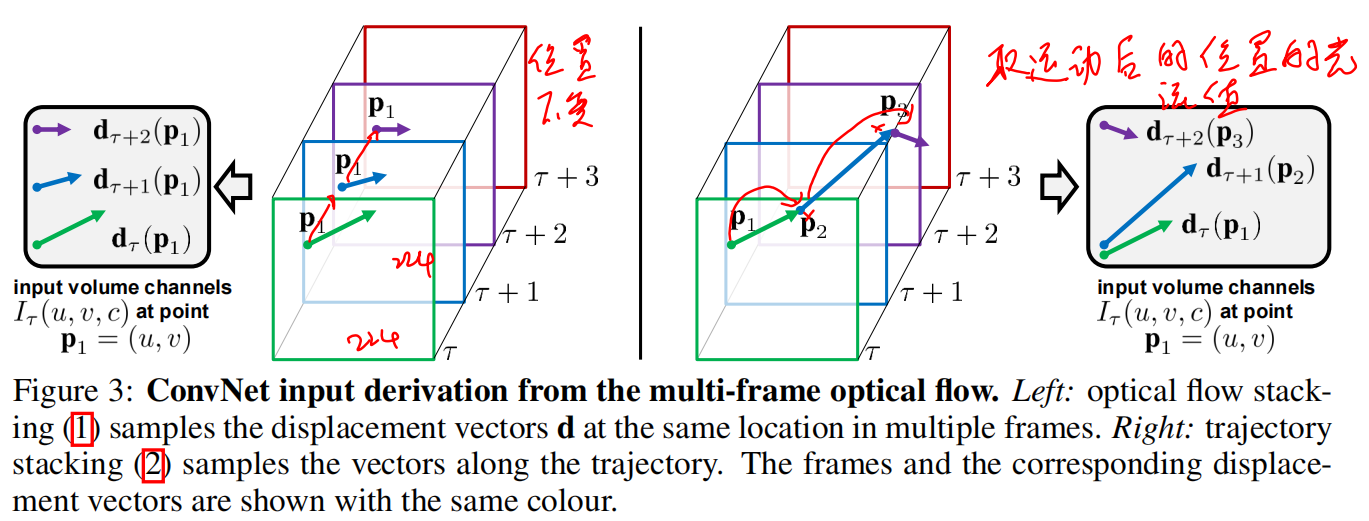
2.1 简单直接叠加
2.2 根据光流轨迹,在轨迹上叠加
2.3 但实验发现基于轨迹效果比基于初始位置的效果差
-
双向光流,这种双向方法起码不掉点
Implementation Details
- 视频等间距取出25帧,不管视频原本有多少帧
- 测试视角数五花八门
- 光流抽取非常耗时,而且光流是密集表示,非常耗空间,于是作者也提出了压缩方法
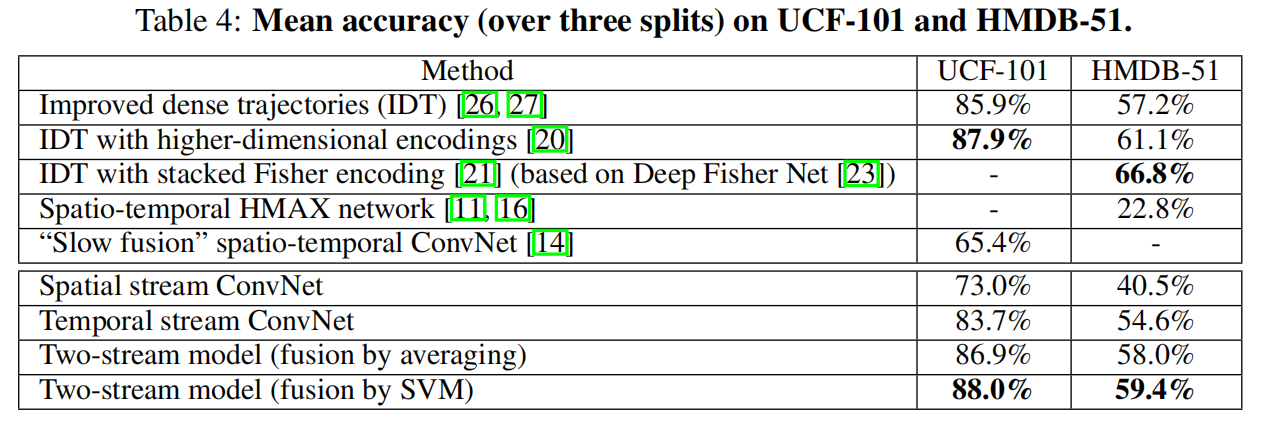
Evaluation