论文地址:Retrieval-Augmented Generation for Code Summarization via Hybrid GNN
HybridGNN:CPG检索增强+静态图与动态图融合
Abstract
摘要写得很诱人
作者指出大多数方法都是基于检索或基于生成,各有利弊
-
基于检索:
可以利用数据库中相似的例子,但泛化性较弱
-
基于生成:
泛化性较好,但不能利用相似例子
于是作者提出了将两者结合方法,一种新的 GNN 来捕获局部和全局结构信息
Introduction
自动代码注释生成是一个离解决还很远的问题,主要挑战有:
- 源码和自然语言语义、结构等差距很大,且各种各样
- 源码逻辑复杂,变量多样,使得学习到语义信息很难
Model
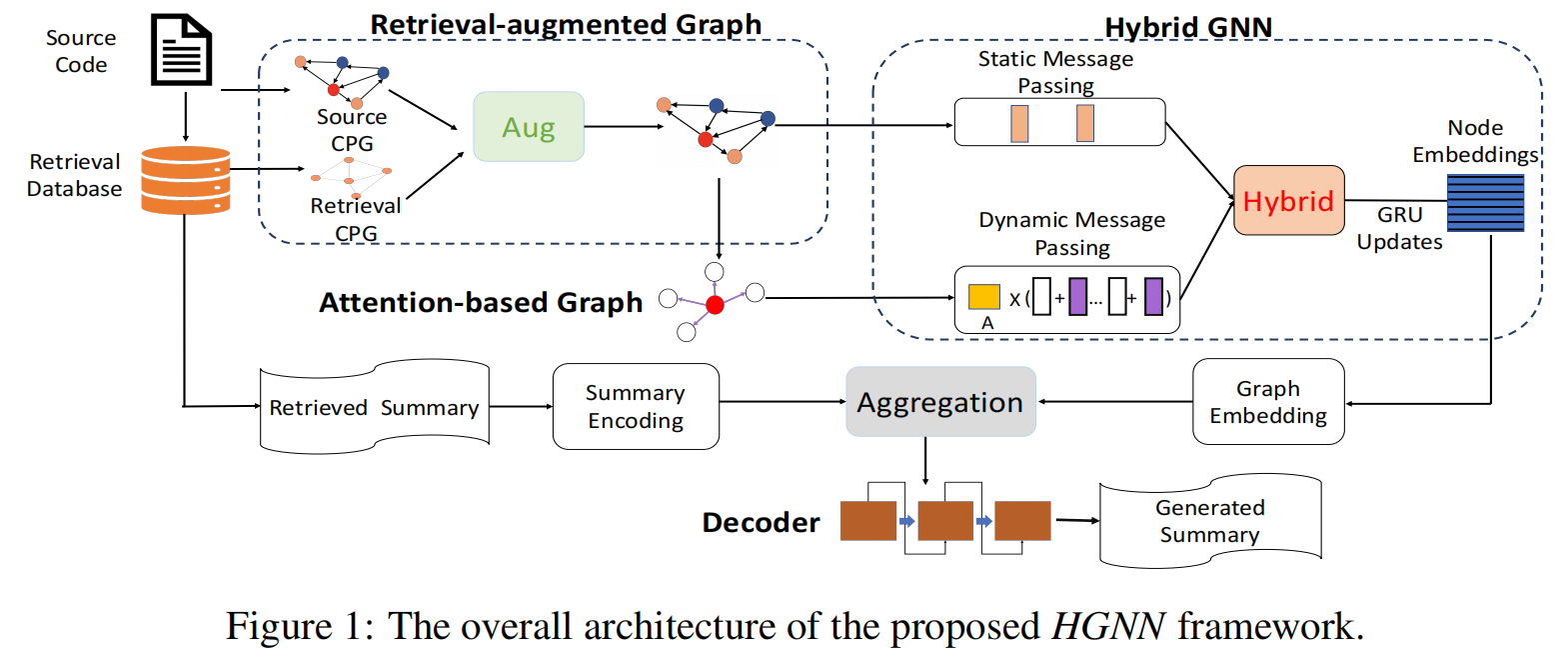
Retrieval-Augmented Static Graph
Graph Initialization
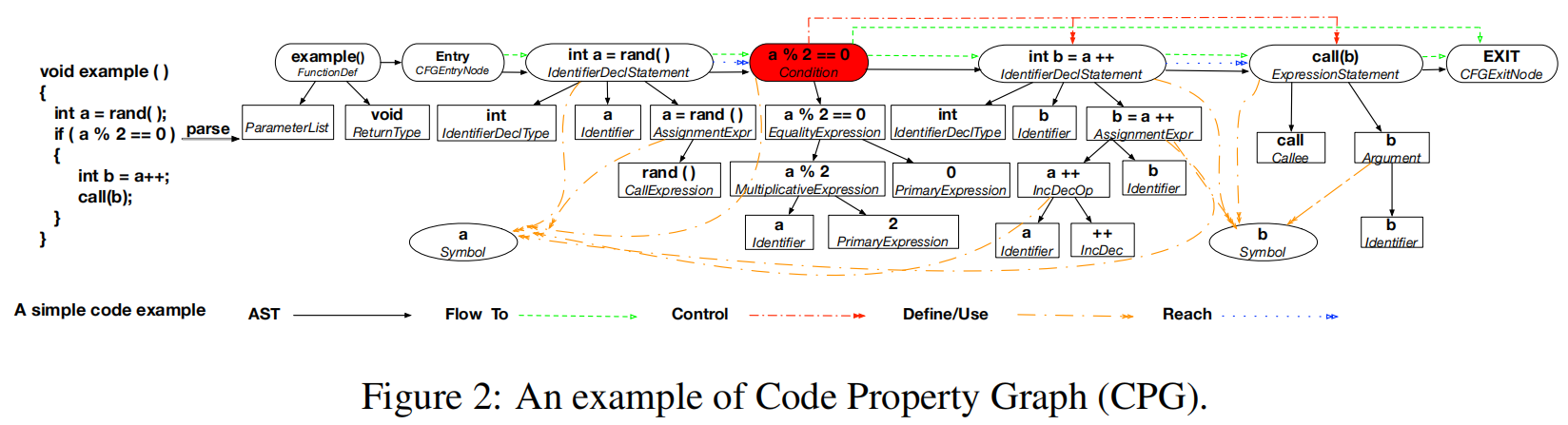
Code Property Graph(CPG):通过不同的边种类(Flow to,control,define/us,reach等)表示为 AST
Retrieval-Based Augmentation
因为对于代码 $c$,目的是学习一种映射把它转换到自然语言总结 $s=f©$ 。于是对于任意的代码 $c’$,其实都有 $s’=f(c’)$ 。
基于此可以推出 $s=f©-f(c’)+s’$,表示可以计算出 $c$ 和 $c’$ 语义上的不同,从而进一步通过这种语义上的不同和 $s’$ 得到 $s$。
这时任务就变成了学习函数 $s=g(c,c’,s’)$
步骤如下:
-
检索:
对每个样本 $(c,s)\in D$,获得最相似样本 $(c’,s’)=argmx_{(c’,s’)\in D’}sim(c,c’)$ 其中 $c\ne c’$ , $D’$ 是检索数据库
相似度 $z=1-\frac{dis(c,c’)}{max(|c|,|c’|)}\$,其中 $dis(c,c’)$ 是文本编辑距离
-
基于代码的检索增强:
融合策略基于带有 attention 机制的初始的图表示($H_c$ 和 $H_{c’}$)
- 注意力权重矩阵 $A^{aug}$,$A^{aug}\propto \exp(ReLU(H_cW^C)ReLU(H_{c’}W^Q)^T)$
- 检索表示,$H’c=zA^{aug}H{c’}$
- 合并表示,$comp=H_c+H’_c$
-
基于总结的检索增强:
用 BiLSTM
Attention-Based Dynamic Graph
对于给定的 static graph,使用结构注意力机制,计算对应的邻接矩阵 $A^{dyn}$
$$
A^{dyn}{(v,u)}=\frac{ReLU(h_v^TW^Q)ReLU(h_u^TW^K)+ReLU(e{v,u}^TW^R)}{\sqrt{d}}
$$
其中 $h_v,h_u\in comp$ 是节点对 $(v,u)$ 通过 CPG 增强,这种全局注意力机制考虑了 CPG 中每对节点,不管是否有边连接
最后经过行归一化用来计算动态信息传递
$$
\tilde{A}^{dyn}=softmax(A^{dyn})
$$
Hybrid GNN
为了更好的融合静态图和动态图的信息,提出了 Hybrid Message Passing
-
静态信息传递
$$
h_v^k=SUM({h_u^{k-1}|\forall u\in \mathcal{N}(v) })
$$其中 $\mathcal{N}(v)$ 是 $v$ 的直接邻居节点,对于每个节点 $v$,$h_v^0$ 是初始增强的节点嵌入表示,$h_v\in comp$
-
动态信息传递
$$
h_v^{'k}=\sum_u\tilde{A}^{dyn}{(v,u)}(W^Vh_u^{'k-1}+W^Fe{e,u})
$$ -
混和信息传递
$$
f^k_v=GRU(f^{k-1}_v,Fuse(h_v^k,h_v^{'k}))\
Fuse(a,b)=z\odot a+(1-z)\odot b\
z=\sigma(W_z[a;b;a\odot b;a=b]+b_z)
$$
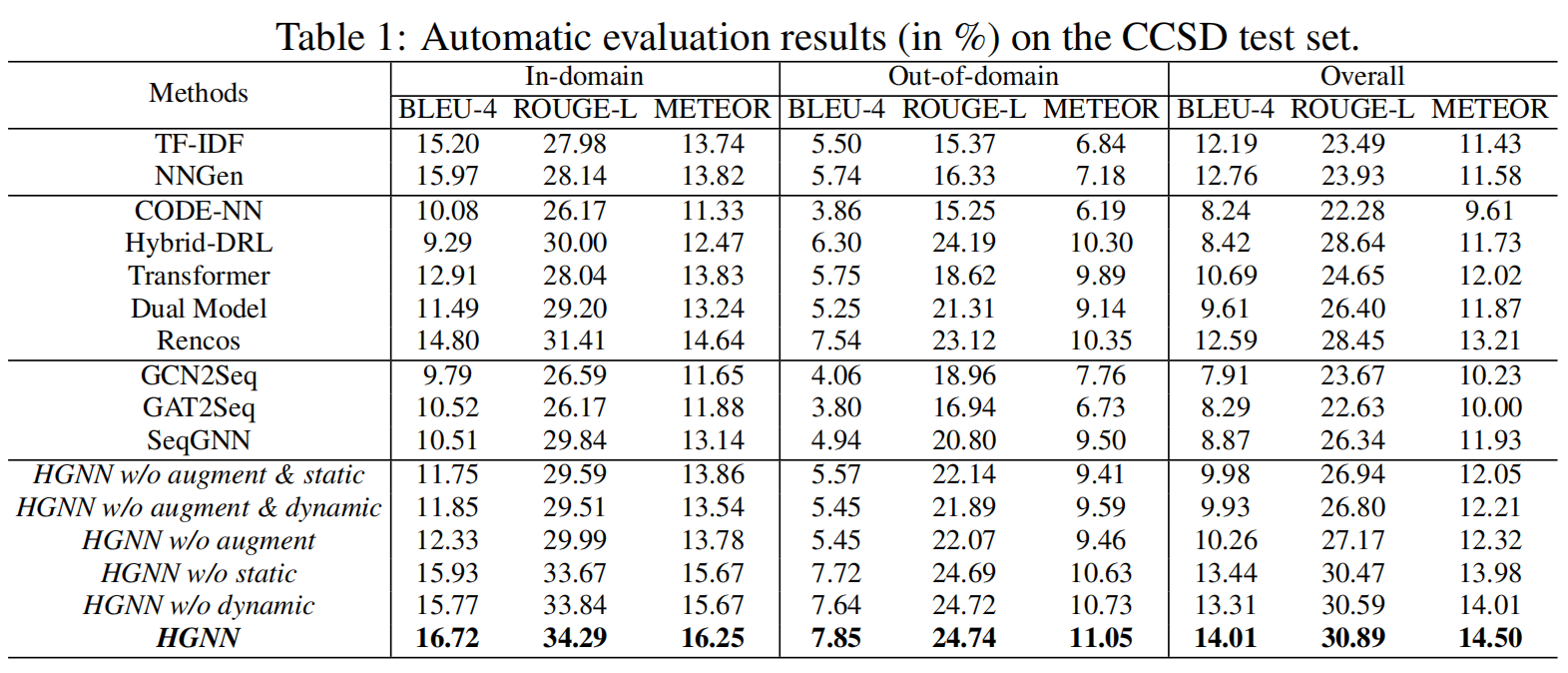
Experiments