CoDiSum:占位符结构+分割语义
Abstract
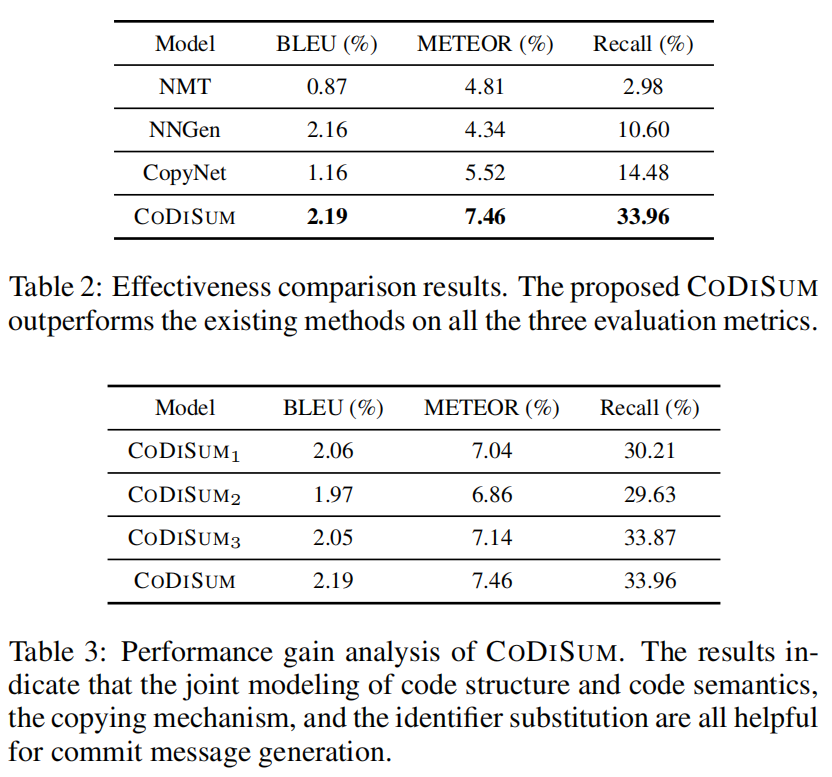
神经机器翻译方法受限于忽略了代码的结构信息,已经难以捕捉超出词库的词的问题
于是作者提出了CoDiSum来处理上述两种性质
Introduction
-
演变历史
1.1 开始是基于预定义的规则和模板,这种方法繁琐无用
1.2 随后采用信息检索技术,主要是重复利用相似代码修改中的commit信息
1.3 最近采用神经机器翻译(NMT)模型,但这种模型的问题就是对于超出词库的单词还是难以预测,以及忽略结构信息

- 对于结构信息,提出了一个有意思的结构提取方法:占位符(placeholder),识别出 class/method/variable 的名字并换成占位符
- 对于语义信息,将 class/method/variable 的名字分割成各种sub单词
Model
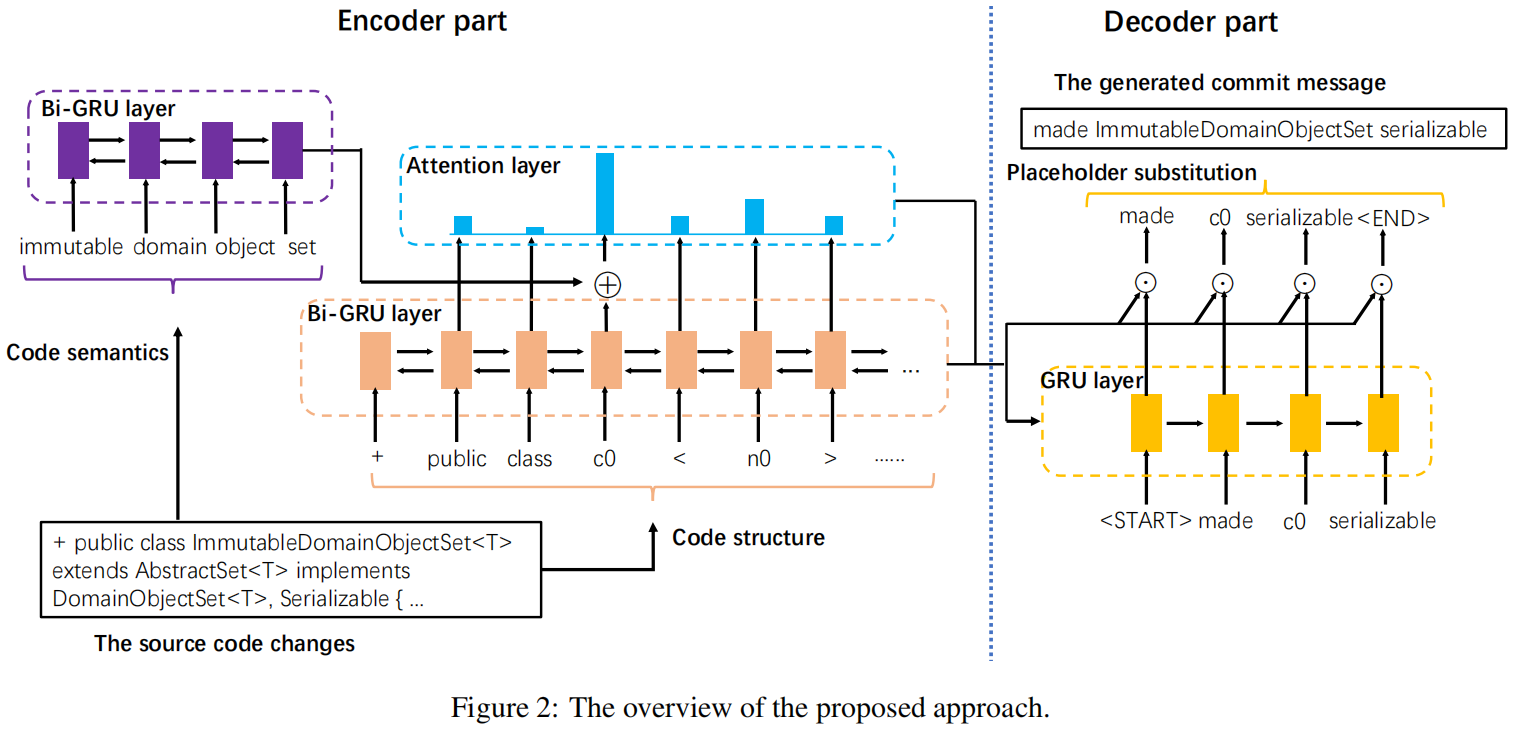
输入数据是改变的代码段
Modeling Code Structure
把增删的代码标识(+/-)也嵌入进去了
Modeling Code Semantics
通过双向GRU编码
Combining Code Structure and Semantics
作者指出如果直接把两种表示concat起来会丢失代码结构与代码语义的通信
对于第i步的单词,如果他是一个标识符(identifier),就concat两种表示作为全局表示;如果不是就补0再concat
在解码器增加了attention
Experiment