CUP:新的分词器和单独编码器
Abstract
帮助开发者提交变更文本的任务称为“Just in Time(JIT) Comment Updating)”,并提出了CUP方法
做了几种定制的增强:特殊的分词器和联合注意力机制
比之前最好的baseline好7倍
Introduction
-
坏的变更注释文本容易误导且没用
-
这种方法不是从零开始更新代码注释的,所以需要注意两点:① 保持新旧注释的一致性;② 旧注释是更新的基石,需要端到端模型去学习代码的修改和旧代码表示
- 新的tokenizer和copy机制
- 对代码变更和旧注释分别用两个编码器
- 构建代码和注释联合词库,使用预训练的fastText模型获取词嵌入
- 增加联合注意力机制
-
数据:1496个GitHub的Java项目,构建了108K个代码注释和修改的样本
Model
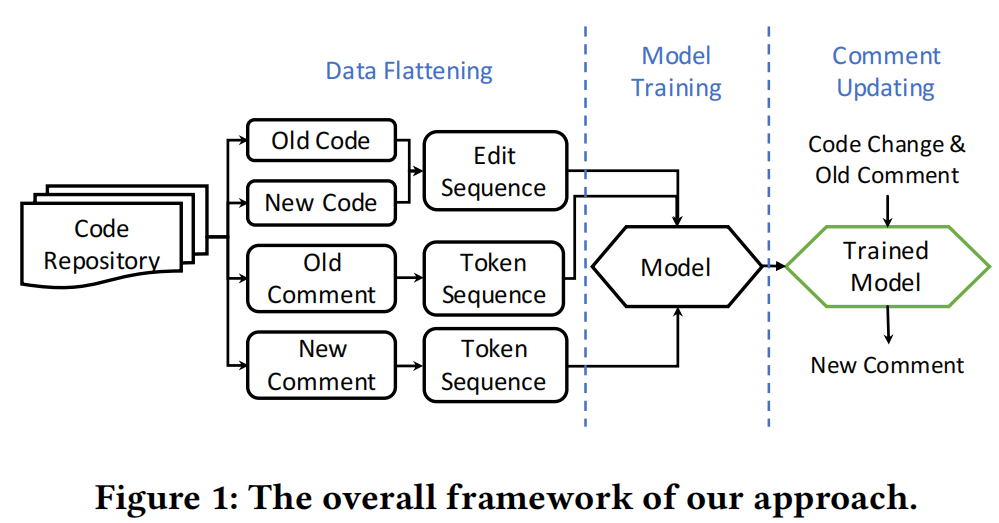
Data Flattening
-
分词
- 移除空格,标点保留,复合词拆分,如果两个邻接的词没有用空格分开,就插入一个
<con>符号 - 主流的分词有三种:不改变复合词,直接拆分,添加特殊符号
</t>,比如“inputBufer” -> “inputBufer</t>”,第一种不能消除 OOV单词,第二种丢失了格式,第三种不能处理当复合词的子词元被视作独立词元预测的情况
- 移除空格,标点保留,复合词拆分,如果两个邻接的词没有用空格分开,就插入一个
-
代码更新表示
- 一个edit由三块组成
-

Seq2Seq Model
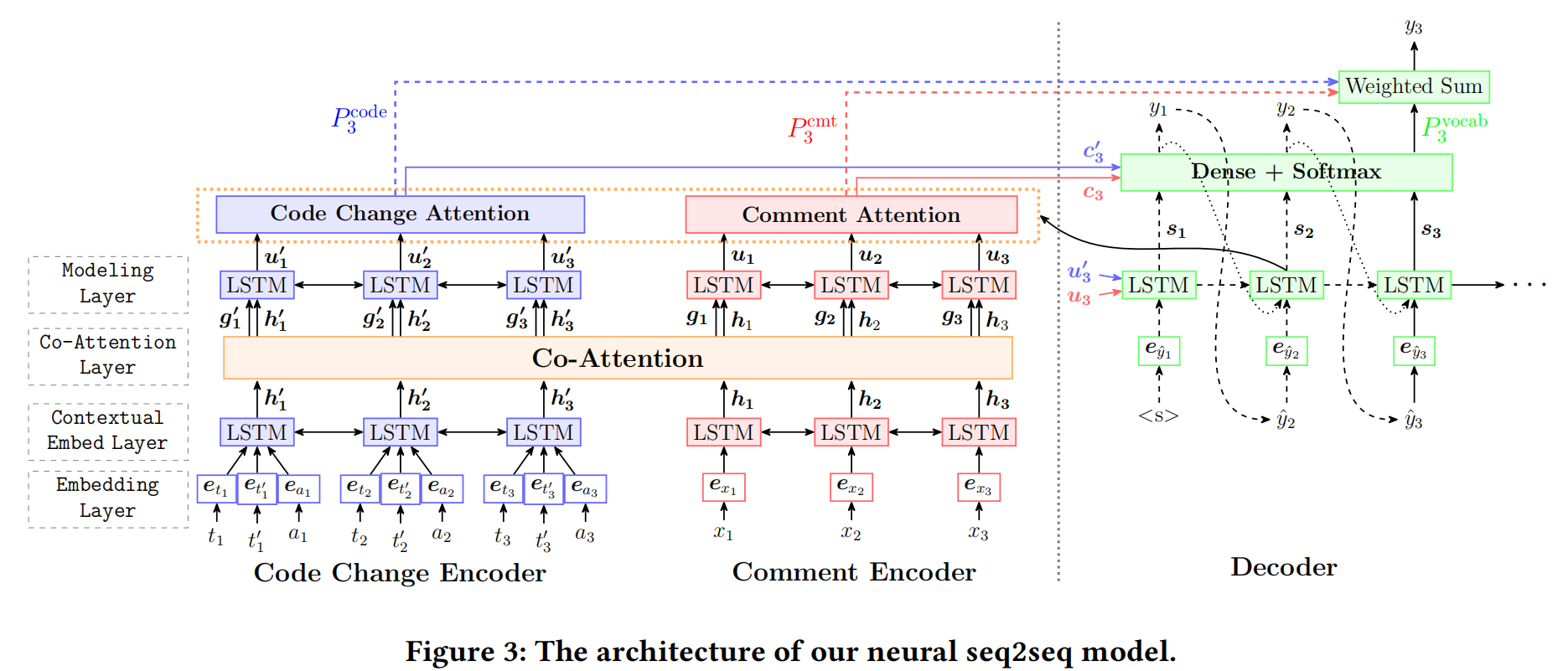
- 每个编码器有四层:嵌入层,上下文嵌入层,联合主力一层,模型层
- 嵌入层:用统一的词库,fastText模型预训练
Data
- 收集了1496个至少500次提交的仓库
- 修改的方法提取:使用GumTree来计算在两次修改中的方法分布
- 数据处理太长了,实现的时候再看原文
Experiment