论文地址:Improving Language Understanding by Generative Pre-Training
GPT 系列来自于OpenAI团队,引用较少源自于他们希望做强人工智能,解决更大的问题,因此模型做得很大,很少有团队能够复现他们的结果,而不是效果不如Google公司的BERT系列。
而Transformer和BERT都是想做技术上的提升,一个是想解决端到端的翻译问题,一个是想将CV领域的预训练和微调方式用到NLP领域,这种技术提升更容易复现
GPT:NLP预训练系列之一
Abstract
标好的数据是比较少的,因此这么训练比较难,但是有大量的没有标注的数据,用预训练的方法或许更好。在NLP领域每个任务都去构造自己的模型,作者提出只改变输入而不改变模型的方法(GPT在BERT之前,所以创新度更好)。
Introduction
-
当时利用无监督的文本最好的模型还是词嵌入模型(word embedding)
-
使用没有标号的文本的两个困难:
- 到底用什么目标优化函数
- 怎么样把学到的优秀表示传递到子任务上
-
作者提出了一种半监督的方法在没有标号的数据上训练一个比较大的语言模型,模型基于Transformer架构,作者觉得这种架构能够有结构的记忆,能够处理更长的文本,抽取出更好的句子层面和段落层面的语义信息;迁移的时候做的是任务相关的迁移表示
Model
最大化似然概率如下,$u$ 指一个个词,$\Phi$ 指模型
$$
L_1(U)=\sum_i \log P(u_i|u_{i-k},…,u_i-1;\Phi)
$$
用的是Transformer的解码器,编码器使用序列时对第i个元素抽特征时能够看到整个序列所有元素,但对解码器而言,由于有掩码的存在,对第i个元素抽特征时它只会看到当前元素和前面的元素,因为是往前预测,所以不能使用编码器
模型生成概率分布,词 $U$ 经过嵌入加上位置信息,经过Transformer块,最后再映射做softmax得到概率分布:
$$
h_0=UW_e+W_p
$$
$$
h_l=transormerBlock(h_{l-1})\forall i\in [1,n]
$$
$$
P(u)=softmax(h_nW_e^T)
$$
与BERT进行比较:BERT不是做标准的语言模型,是完形填空,能看见之前的词又能看后面的词,所以能用编码器。另外一个主要的区别在于目标函数,BERT是完形填空,GPT是预测未来,GPT的开放式结局更难,也可能是效果较差的原因之一,也就是作者一直在提升模型大小,有可能天花板更高
怎么做微调:把最后一层的输出拿出来乘以一个输出层
$$
P(y|x^1,…,x^m)=softmax(h_l^mW_y)
$$
然后优化下面这个目标,一个标准的分类目标函数:
$$
L_2 ©=\sum_{(x,y)}\log P(y|x^1,…,x^m)
$$
作者发现在微调的时候把给一个序列预测下一个词和给一个序列预测标号放一起训练,效果较佳
$$
L_3 ©=L_2 ©+\lambda * L_1 ©
$$
怎么把NLP里面不一样的子任务表示成我们需要的序列和一个标号:
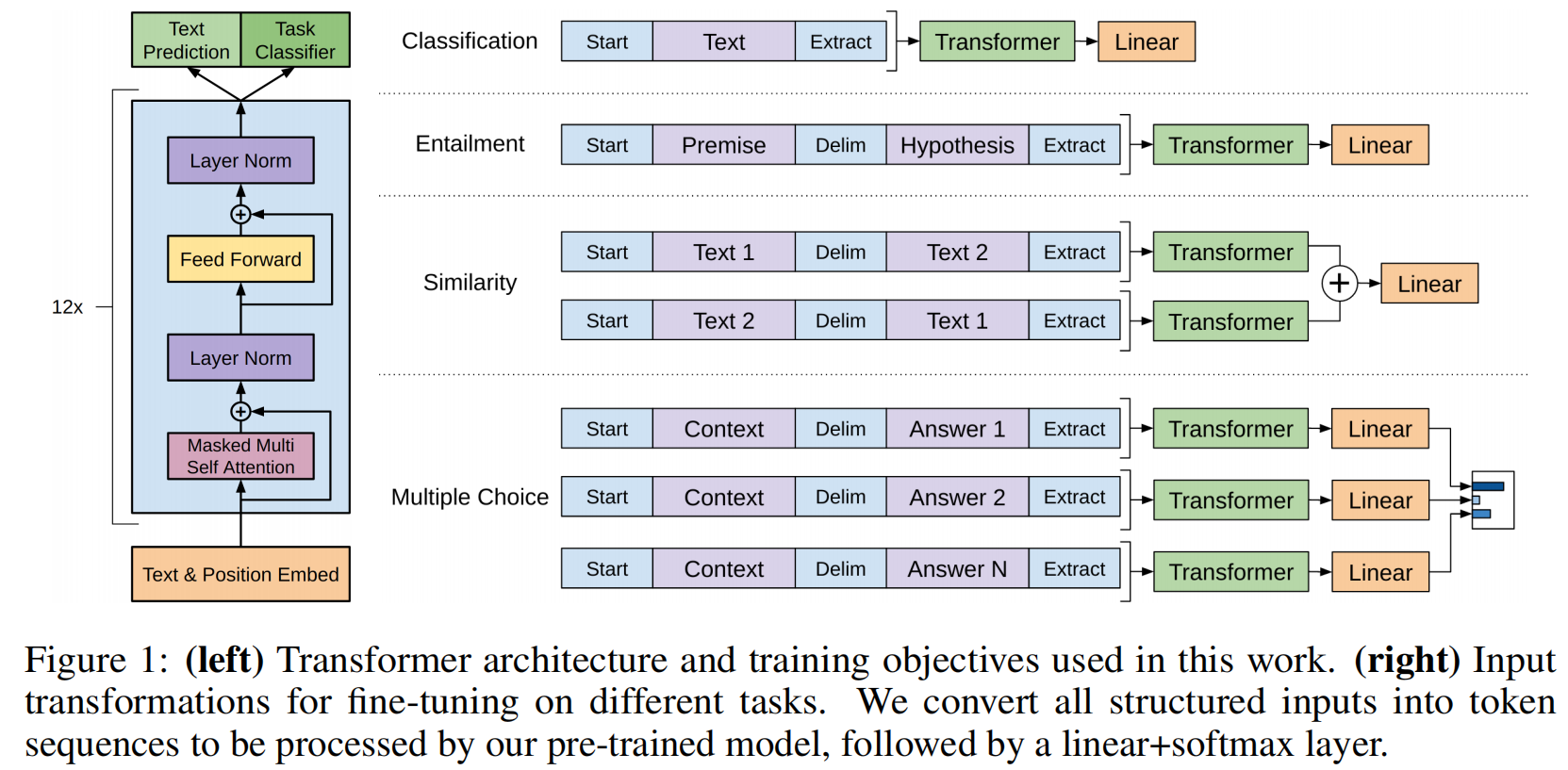
不管输入形式怎么变,输出怎么变,中间的Transformer模型都不会改变
Experiemnt
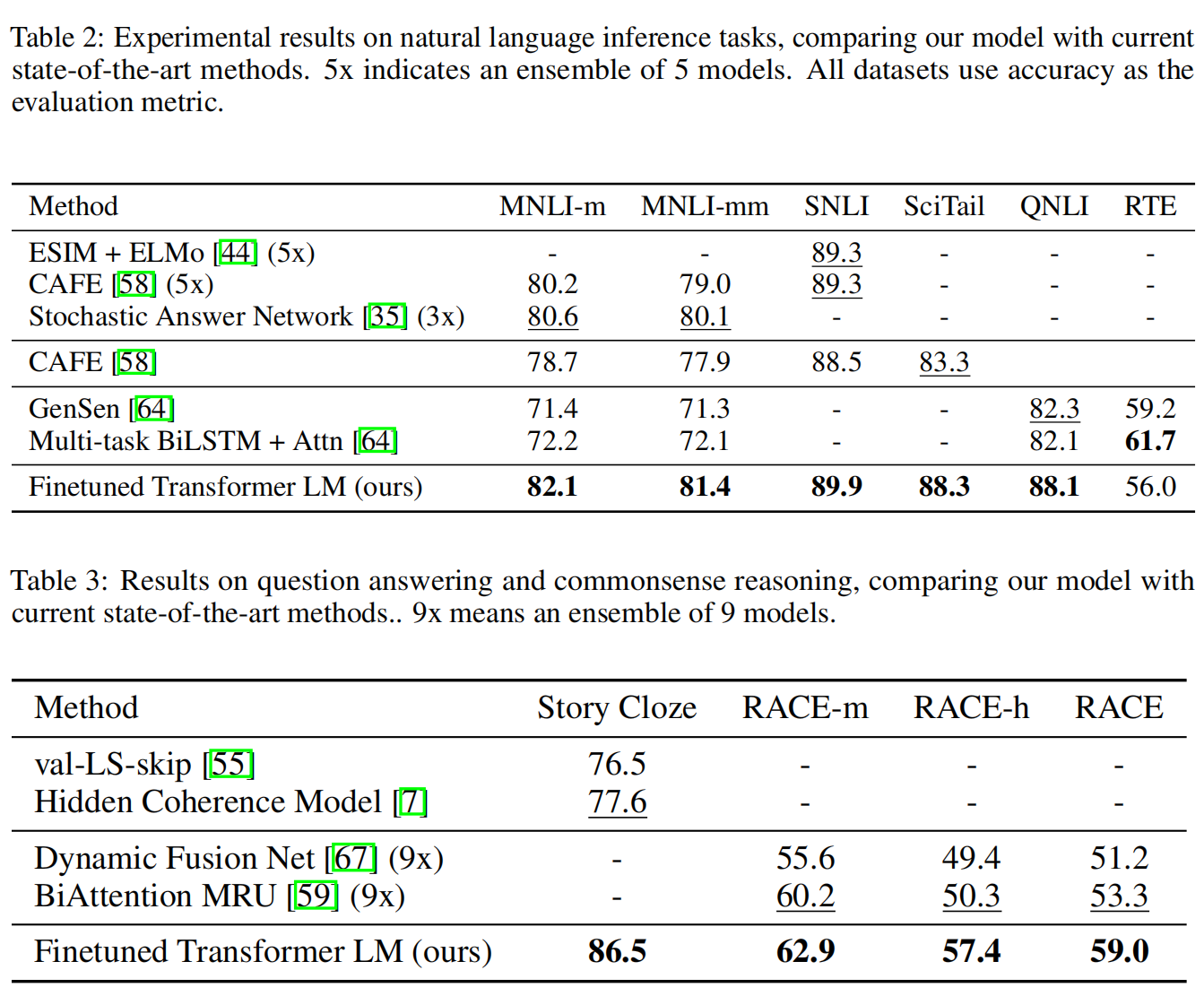
用12层Transformer的解码器,每一层维度是768

