论文地址:Language Models are Few-Shot Learners
GPT做了实验在子任务时提供少数样本但是不是所有样本时,语言模型能够极大地提升性能
GPT-2在GPT上往前走了一大步,不使用任何样本直接预测
GPT-3来解决GPT-2效果不怎么好的问题,于是又使用了少部分样本,做了大量实验,总结来说就是大力出奇迹,我有钞能力。但写得太长了,六十多页
一些快速应用的网站与预览:300+ GPT-3 Examples, Demos, Apps, Showcase, and NLP Use-cases | GPT-3 Demo
GPT-3:NLP预训练系列之三
Abstract
有1750亿个可学习参数,与非稀疏模型比大10倍,因此在做子任务时还更新模型成本受不了,因此不做梯度更新或微调。
Introduction
-
三个问题:
- 大数据集需要标注
- 样本没有出现在数据分布的时候大模型不见得比小模型泛化性更好,也就是说如果在微调上面的效果很好也不能说明预训练的模型泛化性特别好,因为可能是过拟合了预训练的数据,而且这个训练数据和微调任务有一定的重合性,比如换个语种,换个专业性的领域表现就不那么好了。作者的意思就是说不允许做微调那就是硬拼模型泛化性
- 人类不需要大量数据
-
重新定义了”meta-learning“即训练了大模型,泛化性不错,又提出了一个”in-context learning“即告诉了训练样本也不更新权重
-
三个评估:
-
few-shot learning:提供10-100个样本
-
one-shot learning:1个样本
-
zero-shot learning:硬做
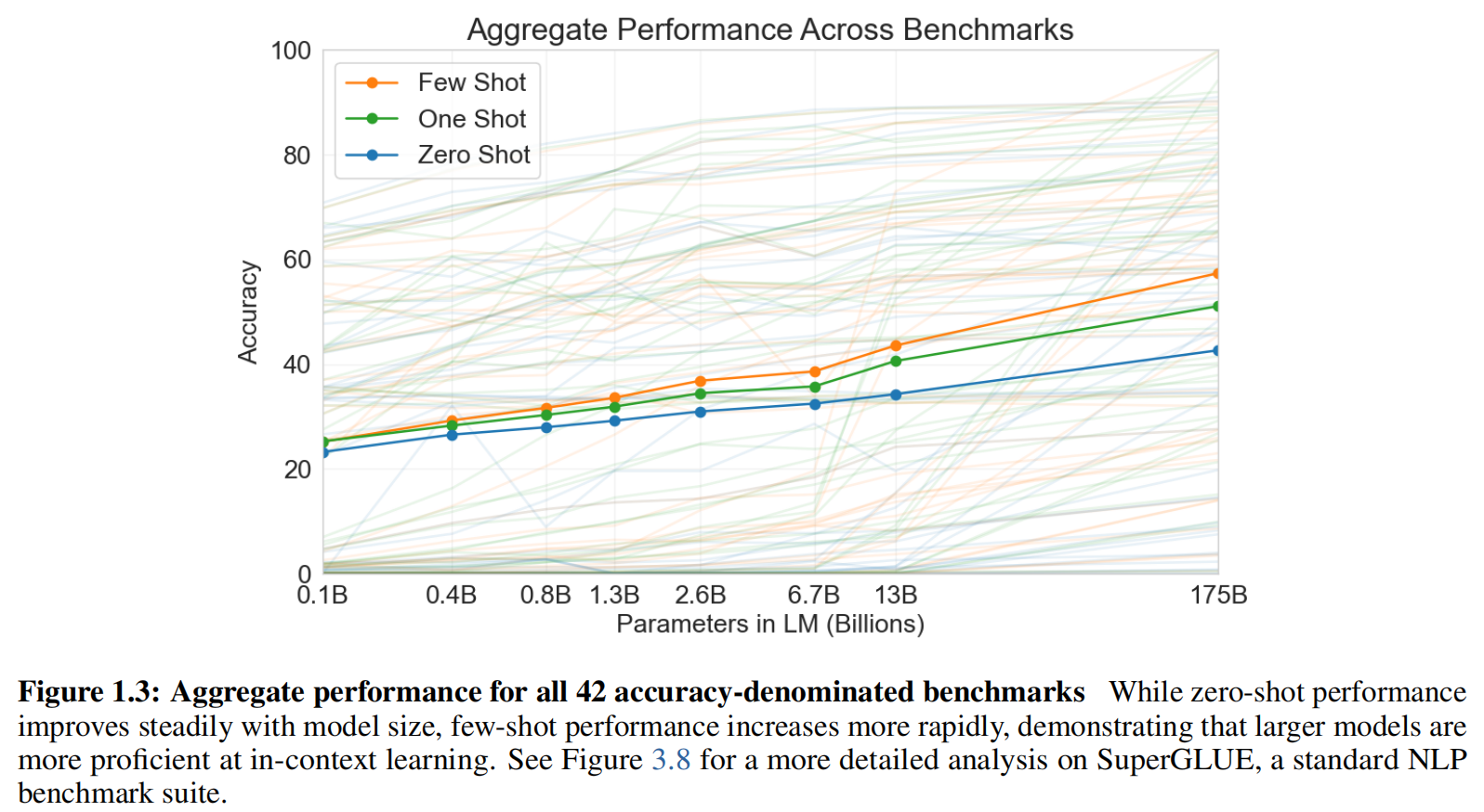
-
Model

还是有两个问题:
- 这种方法本身就只能放一小部分数据,比如我如果我将子任务的所有标注数据都丢进去,不可能建立一个样本能包含所有的标注数据的,因为模型很难抓取如此长的一个上下文语义信息
- 假设直接推理时效果不好,给了一个样本效果好,那么每次推理都要加个样本使模型从中间抓出有用的信息又,因为不能更新,没有存下来。这就使得用GPT-3做few-shot其实用处稍小
模型大小分析:
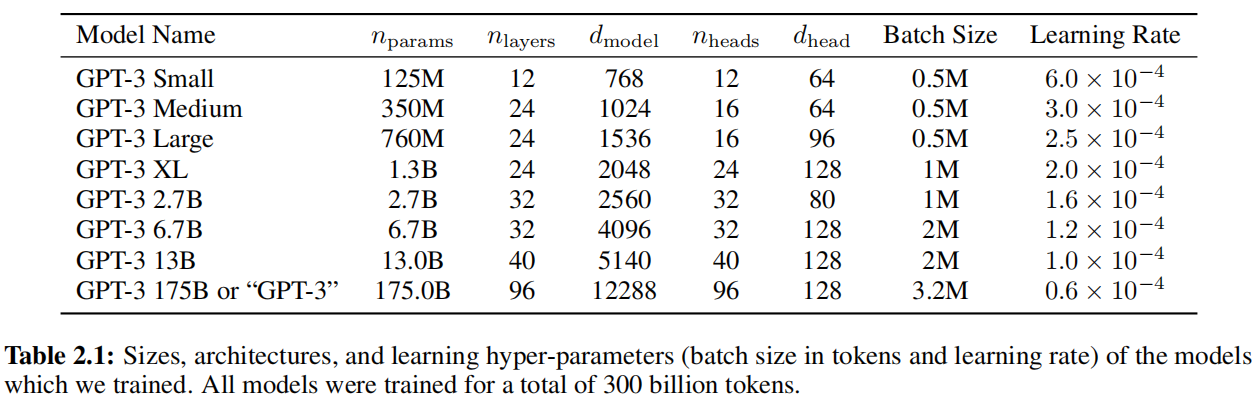
小模型的batch_size不用很大主要原因是容易过拟合,这样采样时数据噪音比较多。模型变大的时候用大的batch_size降低了噪音问题也不大。有一些解释比如:大模型有可能能搜索到一个可能的比较简单的模型架构,把它概括进去,小模型就不太行等等
Dataset
因为要做大做强,不得不再次考虑Common Crawl这个数据,还是做了一个过滤操作:
- 一是将DPT-2的数据作为正类,Common Crawl数据视为负类来训练一个逻辑二分类器,接着对Common Crawl数据做推理,如果是正类则说明质量高留下来,很负类就丢掉。
- 二是去重,用LSH算法判断一个集合和另一个集合的相似度
- 三是加了一些已知的高质量数据集
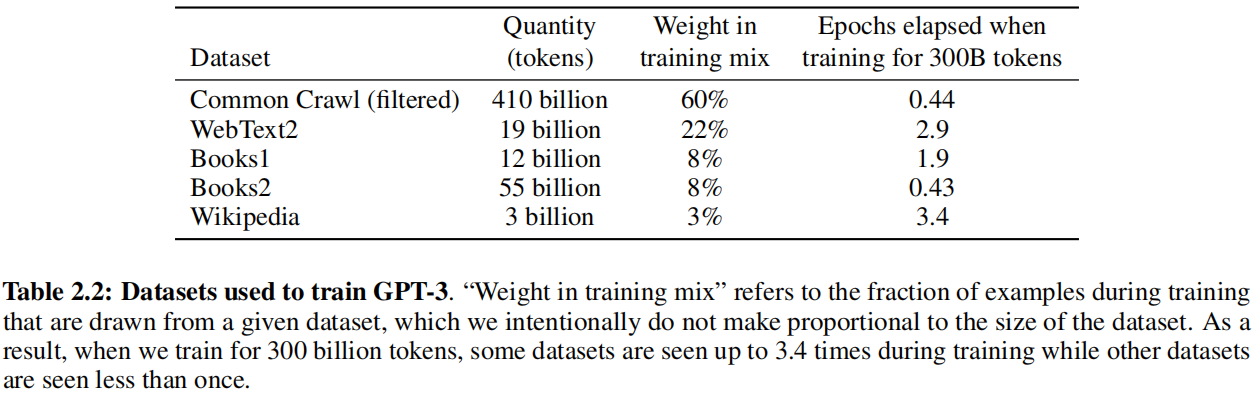
虽然Common Crawl数据很大,但依旧视作较差的数据,所以设置了一个采样率,保证批量里面有一定的高质量数据
Evaluation
在下游任务中采样K个样本作为条件,多分类prompt使用的是”Answer:“或”A:“,二分类用”True“或”False“,自由答案用”Beam Search“
Result
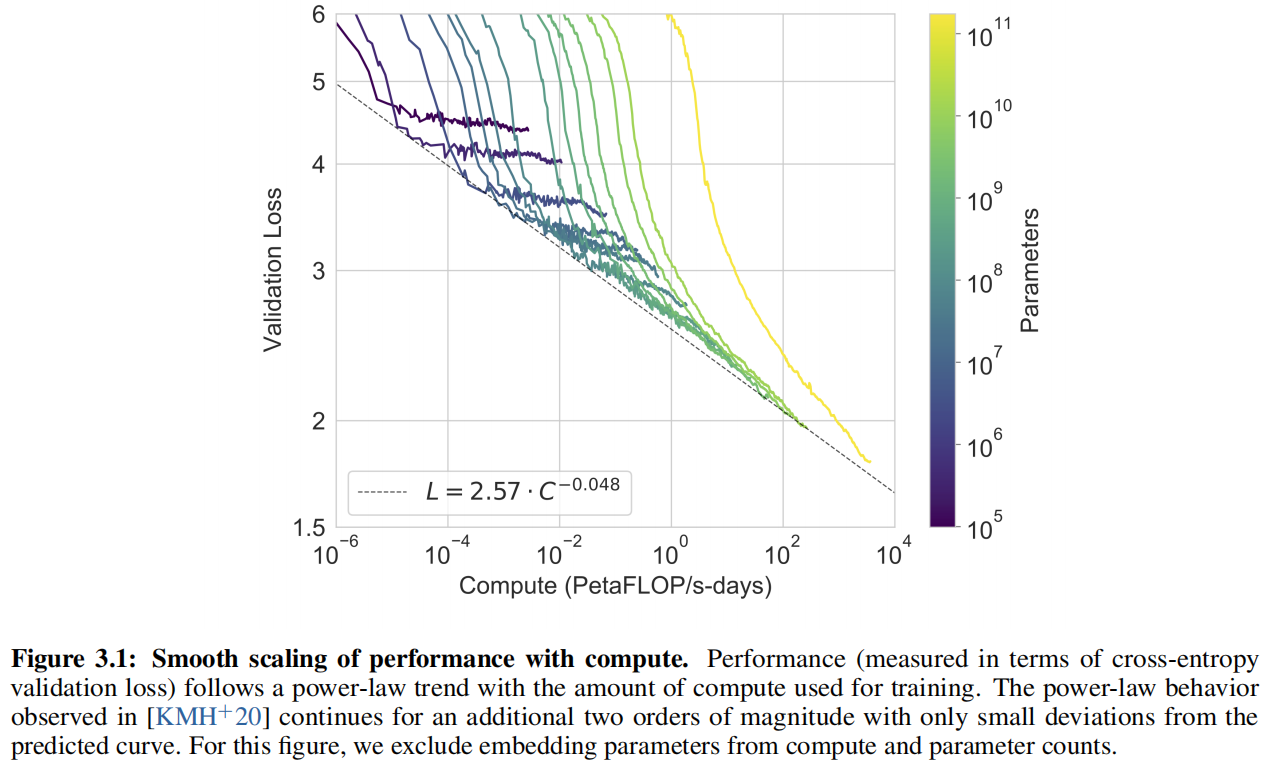
作者发现验证损失跟子任务的精度有一定关系,能够很好表示模型预训练的好坏。在找到一个最好的模型且不用过度训练的情况下,随着计算量指数的增加,损失线性下降
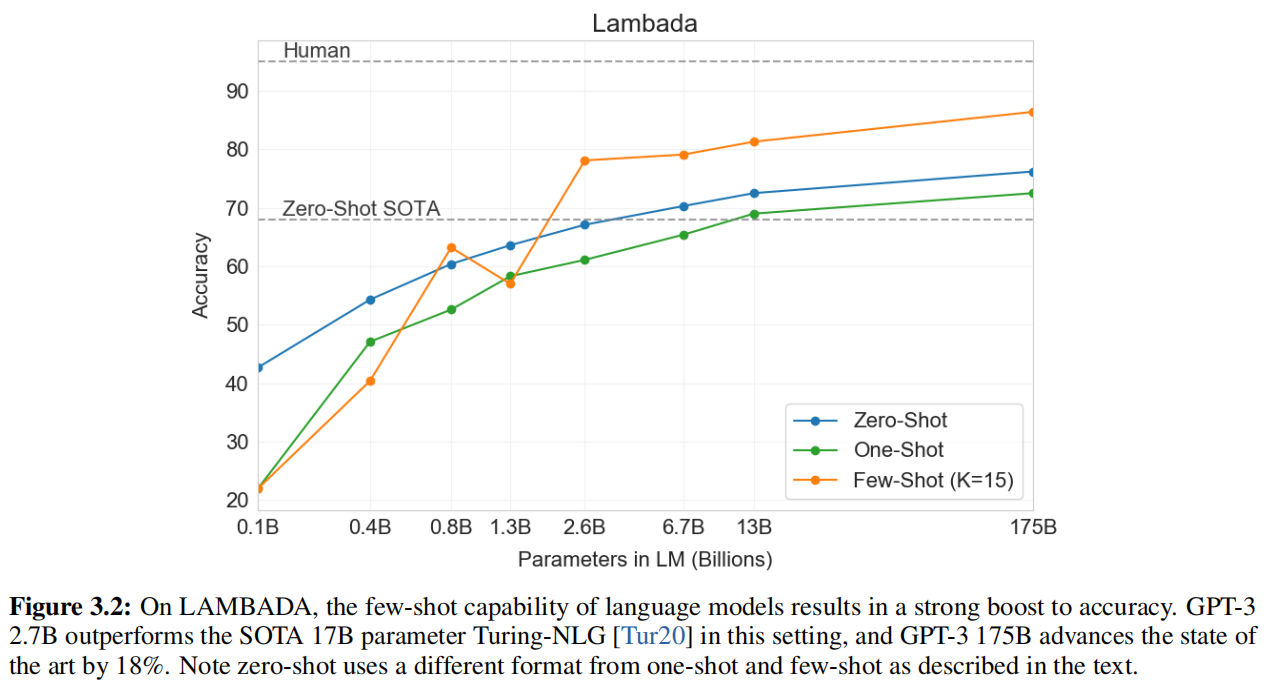
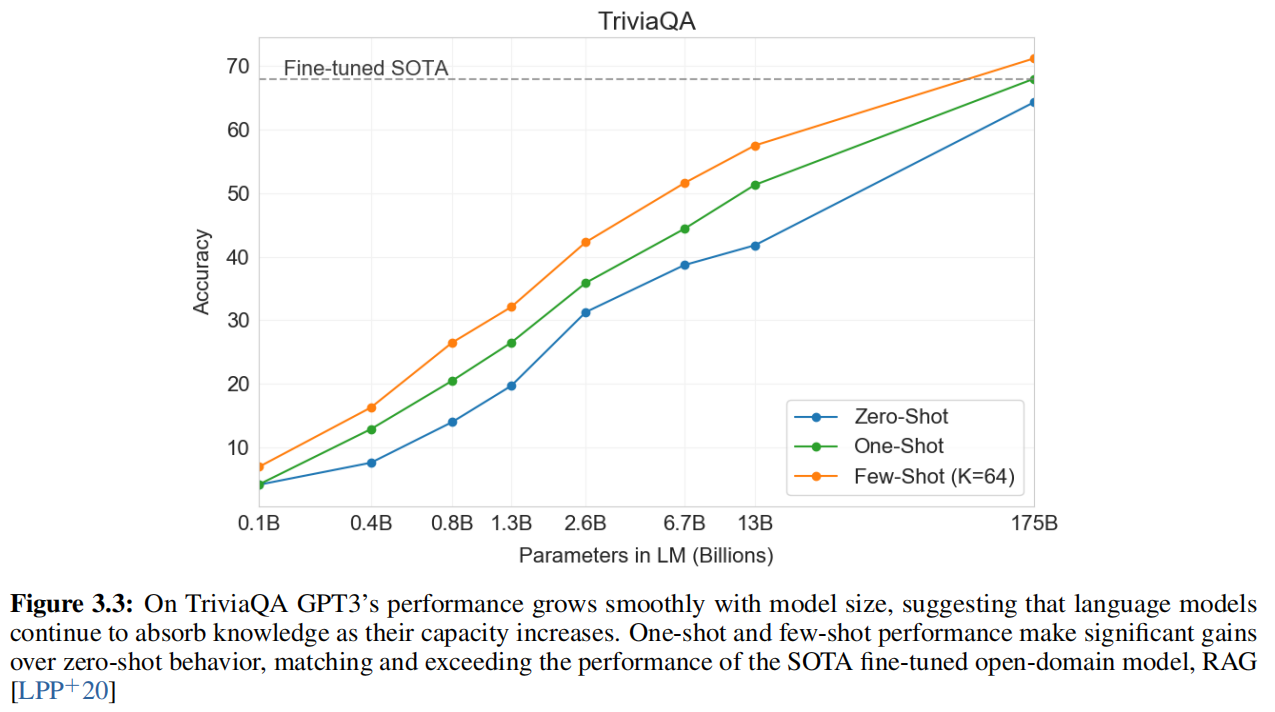

Limitation
- 文本生成方面还是比较弱,写小说很难,但补全没问题
- 结构和算法有局限,不能像BERT那样前后看
- 每个词都是均匀预测,没有去重点学习一些词划重点,例如花了大量精力学习虚词
- 没见过视频,物品交互等等信息
- 样本有效性不够
- 不确定给多个样本的时候是否是真的从头开始学习,是从样本中学习了还是根据样本从之前的找出相关的记住,如果是后者的话泛化性就差了,就是硬拼数据量大小了
- 训练太贵,无法解释,大力出奇迹

