论文地址:Language Models are Unsupervised Multitask Learners
GPT作者发现自己用解码器,欸效果不错,但发现几个月后BERT用编码器,采用更大的数据集和更大的模型将自己打败了,估计是有点无语,但又因为已经站队了,不能说“啊对对对,你编码器你大就是吊,我前面白干了”,所以作者只能解码器一条道走到黑了,继续做大做强,但很扯的是发现变大了还是打不过,那咋搞呢?
GPT-2的启发:做研究不要一条路走到黑,做过程可以一条路走到黑,但是在做研究的时候,要灵活一些,不要一条路走到黑,需要尝试从一个新的角度来看问题。
GPT-2:NLP预训练系列之二
Abstract
文本变为百万级别,模型变成10亿级别,但发现比BERT强不到哪儿去,于是换一个角度,找了一个zero-shot的观点作为主要卖点
Introduction
- 现在的主流途径都是在一个任务上收集一个数据集去做预测,主要是由于目前的模型泛化性都不是很好
- 多任务训练看上去比较好(在多个数据集,可能有多个目标函数的方法),但目前主流还是做预训练和有监督的微调,当然这样还是有两个问题
- 对每个任务还是得微调,重新训练模型
- 收集有标号的数据,拓展任务时成本仍然存在
- 用zero-shot设定,看上去不错有竞争力的结果,新意度一下就来了,工程可以一条路走到黑,但研究不能
Model
在GPT-1的时候对下游任务的输入进行了特别的构造,比如加入开始符,分隔符,结束符,这些符号在模型没看到的情况下,通过微调可以认识。
但是做zero-shot时做下游任务是不能调整的,还引入一些没见过的符号模型就会看不懂,所以输入形式必须更像自然语言,加入了提示符的概念,比如“translate to french, eng text, french text”
Dataset
因为你要加入提示符的概念,所以数据集中必须有类似的信息才行,这对数据又有一定要求了,就比如训练文本里必须出现英语翻译成法语的对话
用Common Crawl,这个数据集很大,但不好用,信噪比较低。所以用Reddit,每个人提交感兴趣的网页,选取了至少有3个评论(karma?)的帖子,说明Reddit用户觉得有一定加直的,这种信息就算是过滤后的
Experiment
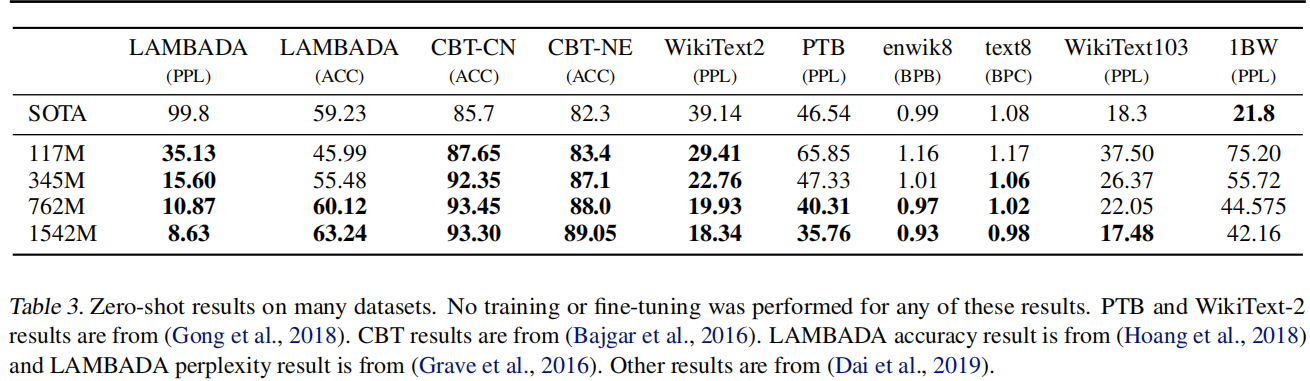
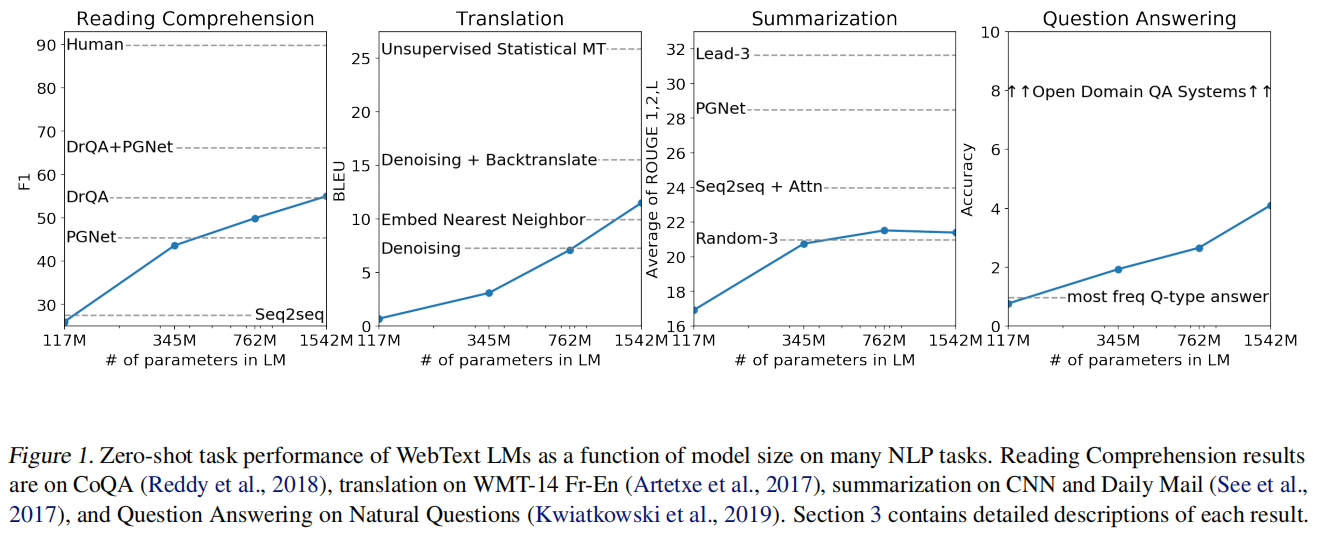
随着模型增大性能还在上升

