论文地址:Evaluating Large Language Models Trained on Code
来自OpenAI团队的Codex,辅助程序员生成代码
Codex:基于GPT的code任务,应用创新而非算法
Abstract
OpenAI团队提出了Codex,一种基于GPT的在Github代码上的微调,创新不在模型而在应用,主要是研究的python语言,能解决28.8%的问题。如果允许重复采样的话,即假设采样100个结果,有一个解决了那就算解决了问题,那准确率可以提升到70.2%
Introduction
GPT-3可以生成简单代码,但复杂的不行,所以重新训练了一下。
作者关注的是Python的docstring,即函数前的注释,生成的代码通过单元测试来验证正确性。作者造了一个数据集叫humaneval(https://www.github.com/openai/human-eval),一些简单的数学,编程面试等问题。
生成多个答案,看是不是有答案能通过单元测试。使用120亿参数的模型能达到28.8%精度,3个亿参数能达到13.2%,而GPT-J使用60亿参数只能达到11.4%精度,而其他的GPT基本是0%。
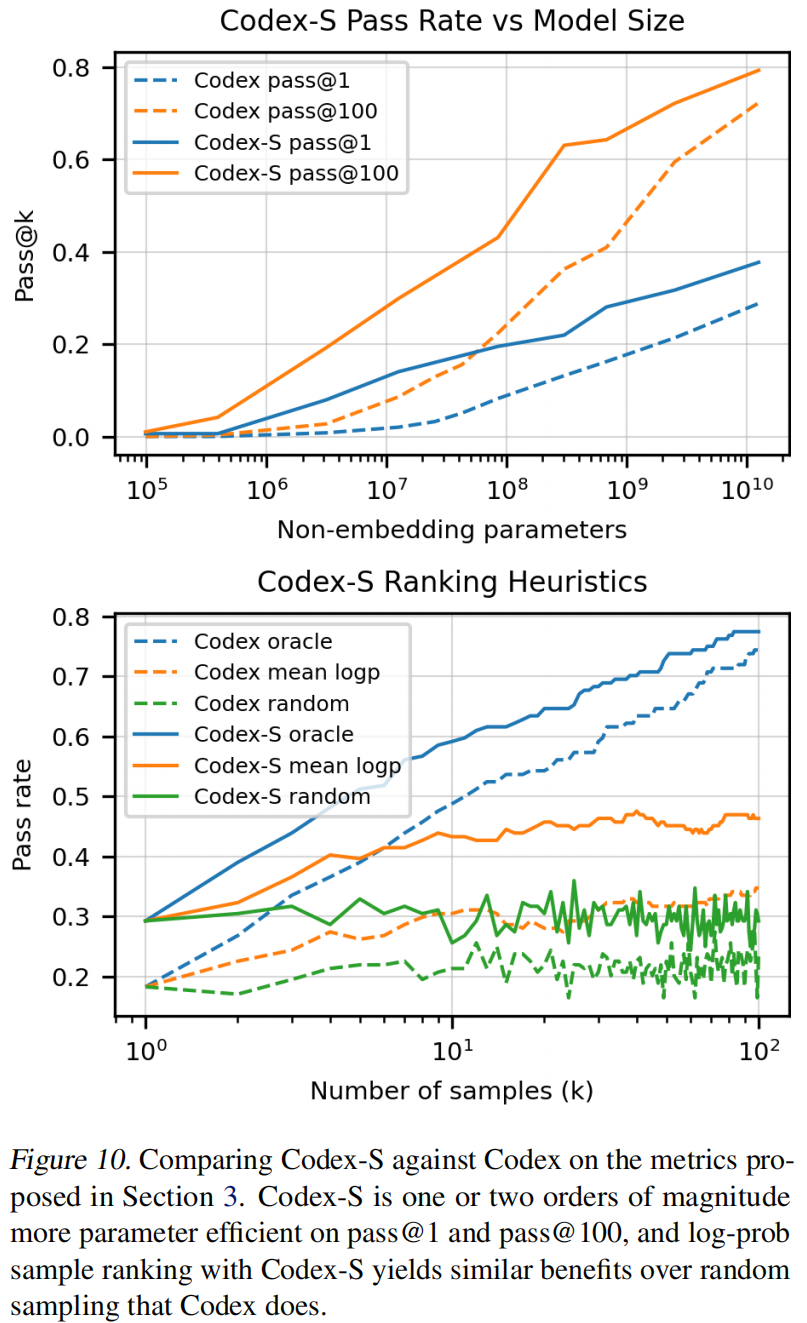
为了进一步体现作者模型的性能,又收集了一个数据集。在上面微调的模型叫做codex-s,只是用一个例子也能提升到37.7%。如果允许生成100个答案,那么其中有一个正确的概率就变成77.5%。
现实肯定是不能这么用的,不能给用户100个结果让用户自己去挑,所以如果提供一个排序算法,得到的最好的结果能达到44.5%的精度(通过率)。
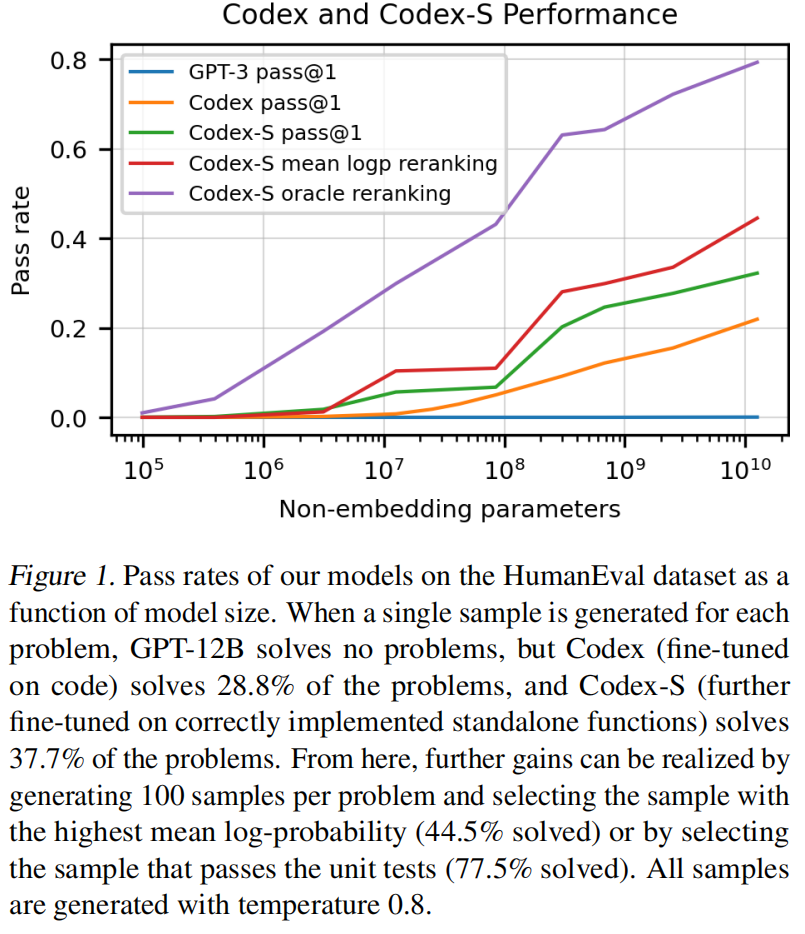
还是有上升趋势,如果用更大的数据更大的模型说不定更好
Evaluation Framework
评价指标
用 pass@k 评估,选k个,有1个通过就算成功,这个k的值如果选很大就不太能反映出这个模型的好坏。因为在真实的生产环境中,给用户生成一堆代码肯定也要给出置信度是多少,对结果进行排序,k太大了就对模型过度乐观了。
计算方法
每次生成k个答案再判断能否通过的方法不太稳定,需要重复做多次实验。所以作者采用了生成n个样本,n>k,然后再抽k个,c表示正确答案:
$$
pass@k:=\mathbb{E}{Problems}\left[ 1-\frac{ C{n-c}^k}{ C_n^k}\right ]
$$
验证集
手写的,因为网上找容易是训练集里见过答案的(数据泄露)
Model
数据收集
收集了179GB个python文件,但没有过滤协议,这也产生了一些冲突与批评
方法
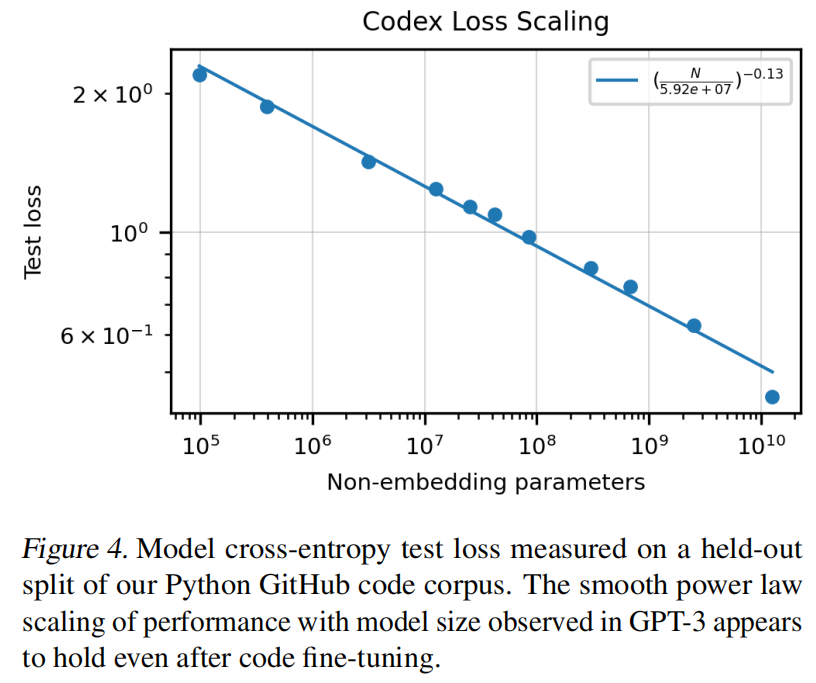
微调:作者原本认为把GPT-3的权重拿过来微调会有好处,但实际没用,但训练收敛更快,这也体现出微调的模型可能有好处可能没好处,但一般收敛都会加快。
词元处理:把不同长度的空格用特殊词元表示,避免模型一个个去认,这样能减少30%的词元
停止:\nclass,\ndef,\n#,\nif或\nprint
预测:下一个词预测时没有采用最大概率或束搜索,采用了一个**核采样(nucleus sampling)**方法。
- 具体是指在任意时刻对于候选词有一个概率,然后把这些词的概率从大排到小,依次留下来,直到拿到的所有词的概率加起来大于等于0.95就停止,从这些候选词中采样一个词作为序列后的预测。
- 这样能够保证每次运行能得到不一样的结果,且能保证一定多样性,去除特别不靠谱的词
Result
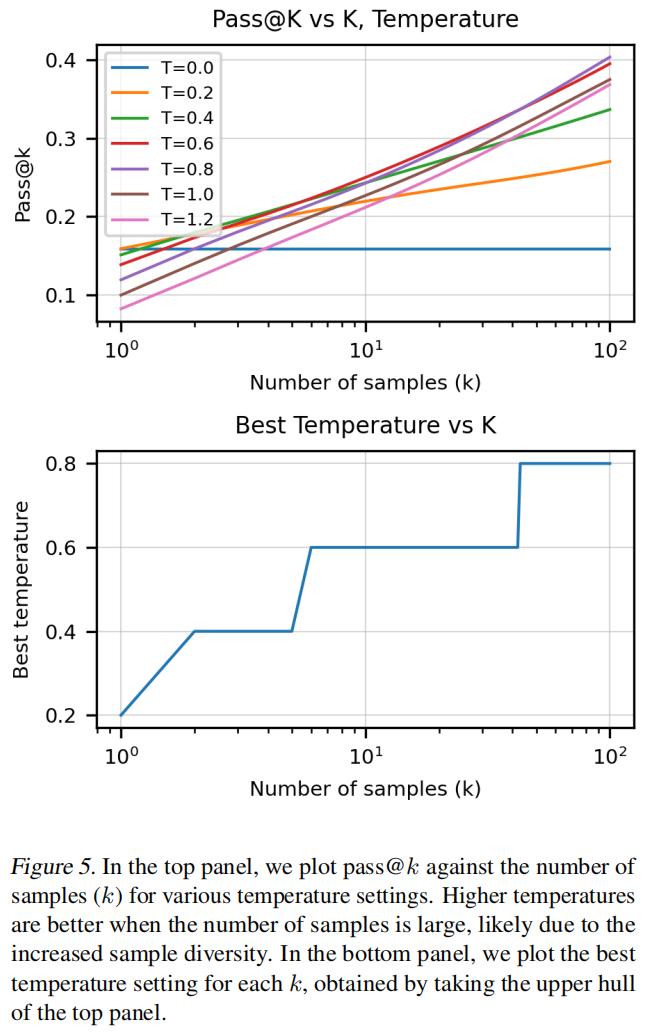
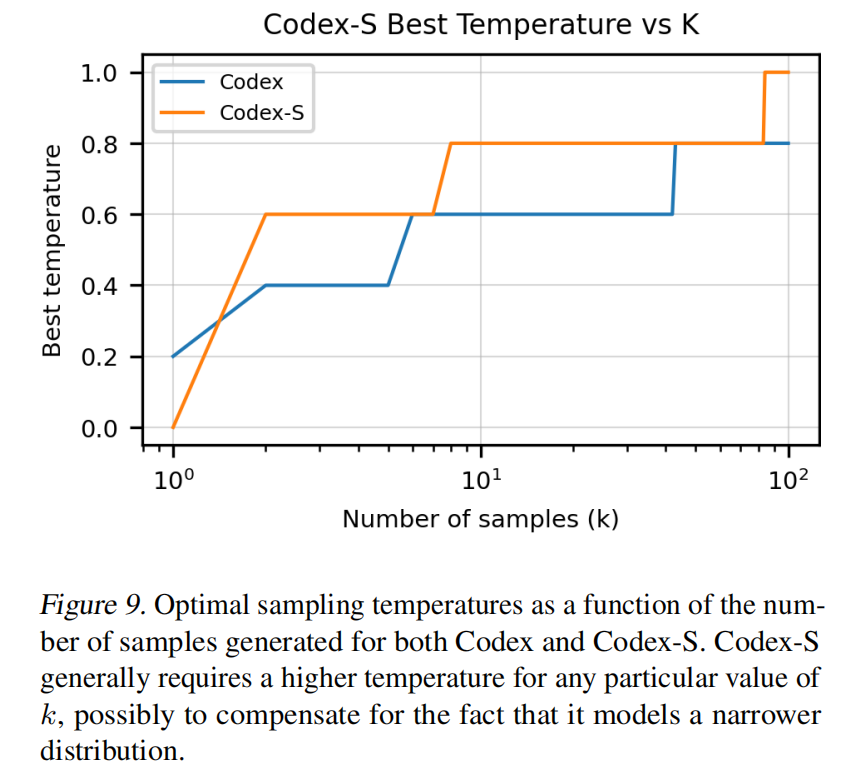
softmax除以一个较高的温度会使候选词概率更加接近,较低的温度值就会比较区分开。也就是说温度值较低的时候,最好的几个词概率会更大,总会采样最好的几个词。温度较高时概率相差不大,就比较均匀。
允许的采样数增加时,温度也应该增加。
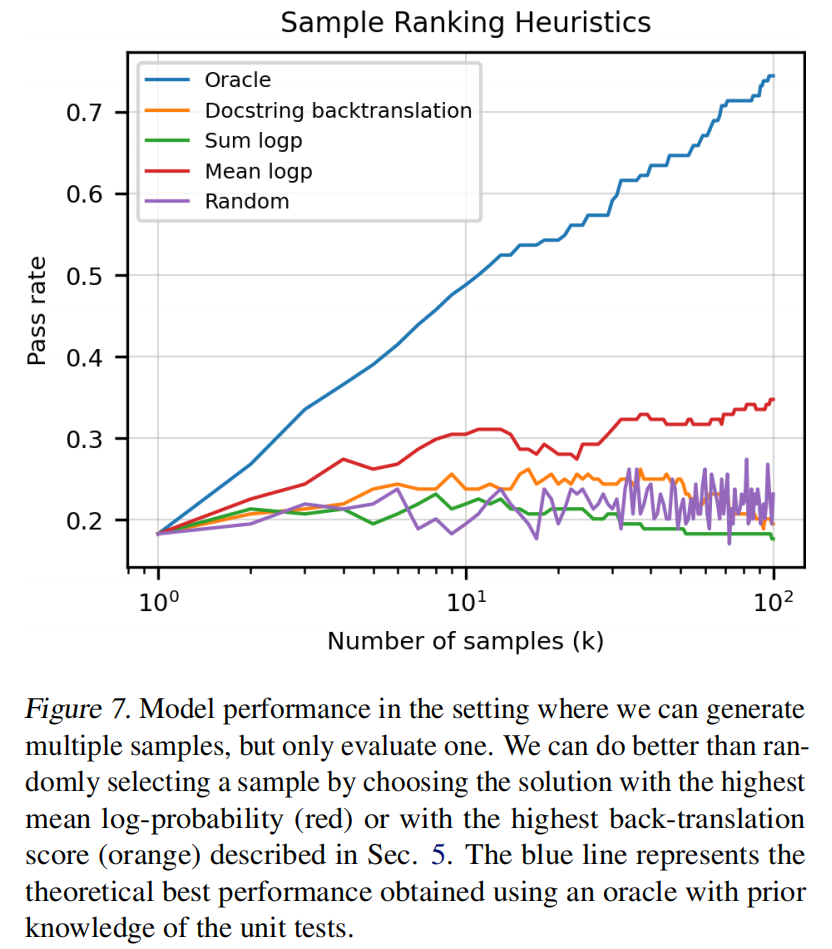
挑选答案时的排序算法,较好的方法是看每个候选词在softmax里的概率,做log后计算均值,均值最高的解拿出来
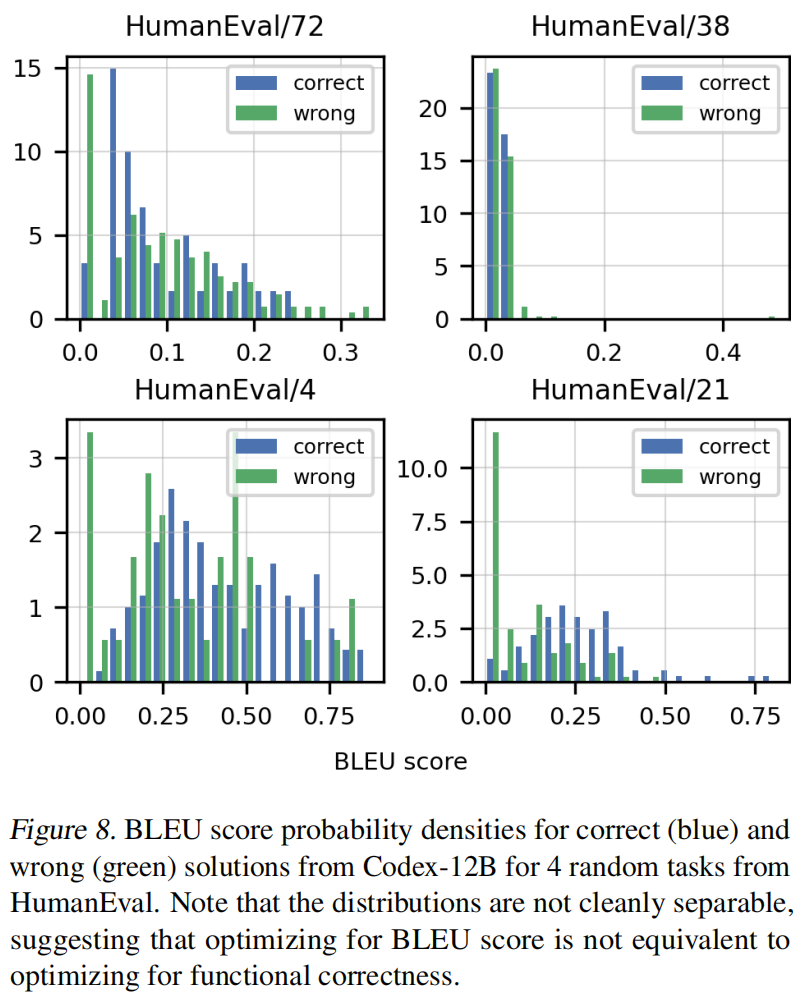
BLEU分数很难区分出答案的正确性,很难保证代码的语义正确
Supervised Fine-Tuning
额外准备了一个带标准答案的数据集,意思是训练集和human eval还是有一点区别,如果有训练集和human eval一致说不定还能提升
- 从各种程序比赛中拿到了10000个问题
- 敏捷开发中每次代码提交都会出发持续集成(Continuous Integration)这个服务,将所有单元测试跑一遍。从持续集成中拿数据,能够看到里面要跑哪些任务,大概4万个
拿到问题后又做了一个过滤,把最大的模型拿出来,生成100个结论,如果至少有1个是单元测试通过了就把问题留下来,如果通过不了说明问题太难或单元测试不正确,对模型训练没多大帮助
Docstring Generation
因为python里面注释是在函数签名和函数本体中间的,这个GPT这种预测不了中间这种。所以就又重新做了一个数据集,把注释挪到最后。
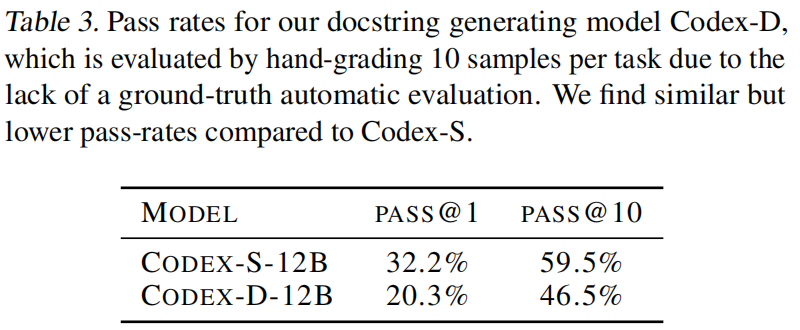
这种模型叫Codex-D
评估办法:
- 眼睛看
- 先用Codex-D生成文档,再根据文档和函数签名反过来实现答案,再通过单元测试
Limitation
- 样本有效性不够,需要看很多代码
- docstring的提示应该怎么做?作者发现当docstring比较长的时候,生成出来的代码就会打折
- 组合了13个building block,每个模块是对字符串做一个操作,比如转成小写,转大写,换位置,这13个块可以任意组合,让代码依次完成
- 这种块连起来用的越多,精度越低
- 数学不好,精确复杂操作理解有问题
- 人可能过度依赖模型生成的代码
- 模型可能能干要求的事情,但是不是按我们需要的要求。比如让模型生成注释,那模型会更倾向于生成跟训练数据更一致的注释

