AlphaCode:竞赛代码生成
Abstract
目前AI来做代码生成还是一件很难的事情,作者认为目前的工作还是比较简单,类似于将程序指令来做一个机器翻译问题,做一些复杂的问题还是不行。所以作者提出研究程序竞赛这种问题,再Codeforces平台上面对五千多个参赛人员能打败近半。
这样需要 ① 一个很好的数据集;② 一个高效的基于transformer的架构;③ 需要一个高效采样方法生成大量答案。
Introduction
指出Codex生成短的代码片段的方法类似于直接翻译,也不需要太理解代码在讲什么,所以作者提出要解决更难的问题。
对于ICPC,IOI这种程序竞赛的效果都不是很好,Codex也只能拿到几个点的通过率
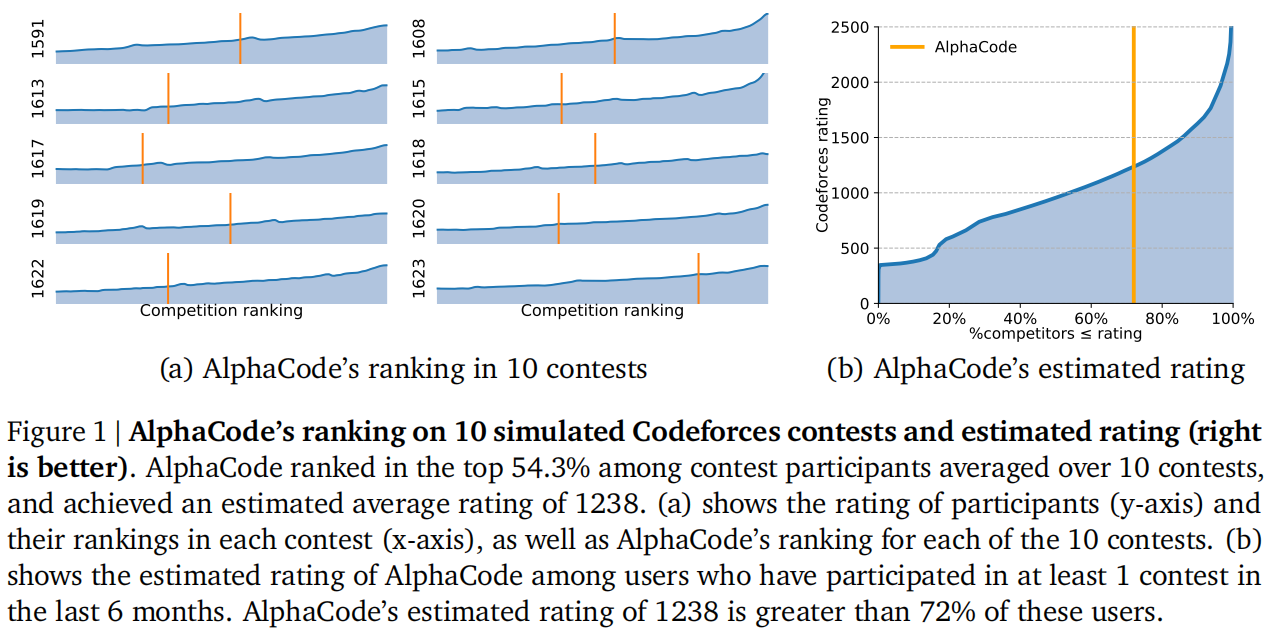
估计能高过72%的选手
Evaluation
线上比赛不多,所以线下评估。采用 n@k ,指模型采样出k个候选算法,对算法进行排序选出前n个,有一个正确就是通过。
Dataset
预训练数据集:不仅收集了python,还收集了C,GO,Scala等等,拿到了715gb的数据,比codex大了五倍左右
微调数据集:codeforces和爬的别的网站数据集全放一起叫CodeContests
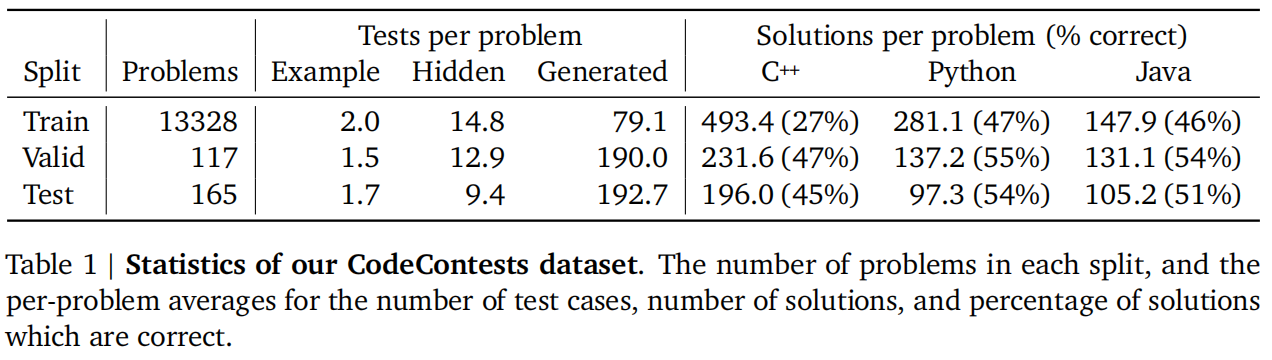
爬数据的时候有个问题就是如果把题目所有的测试样例都爬下来训练,那么模型可能会根据这些数据进行调整,导致拿到的结果分数是虚高的,泛化性差。如果不全爬下来那么可能就是模型生成的答案其实是错的,有些边边角角问题没有考虑到,但是给通过了。
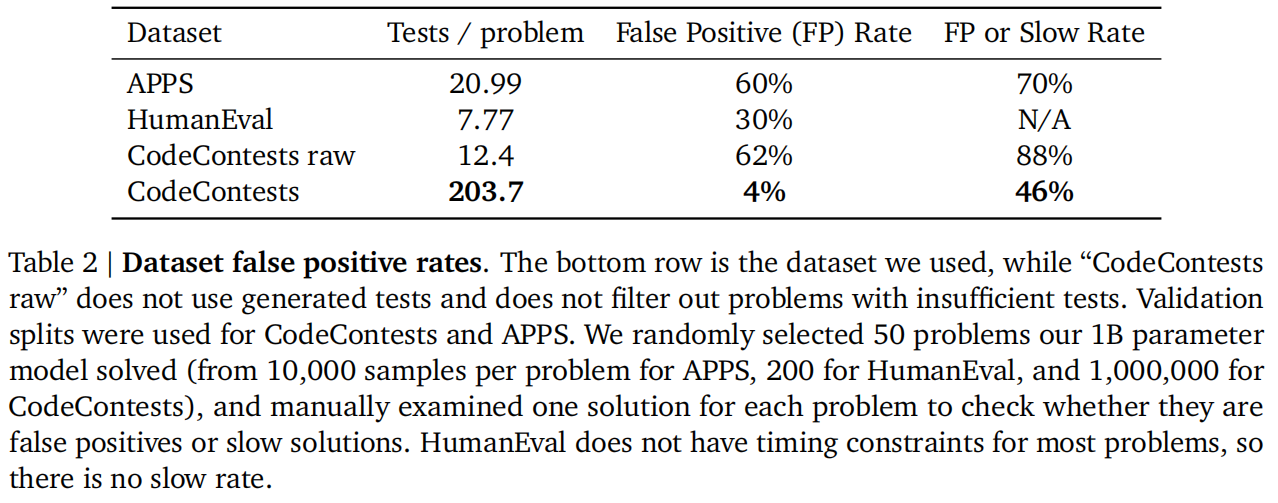
FP是指因为测试样例少,导致错判了模型的答案是正确的,Slow Rate指超时了。作者发现在增加了测试样例后两者都会有所下降。
Model
Architecture
使用的是Transformer完整的带编码器和解码器的结构,因为问题描述很长,只有解码器理解可能不够,只有编码器也不行,因为写得代码是很长的,解码器更适合这种生成。
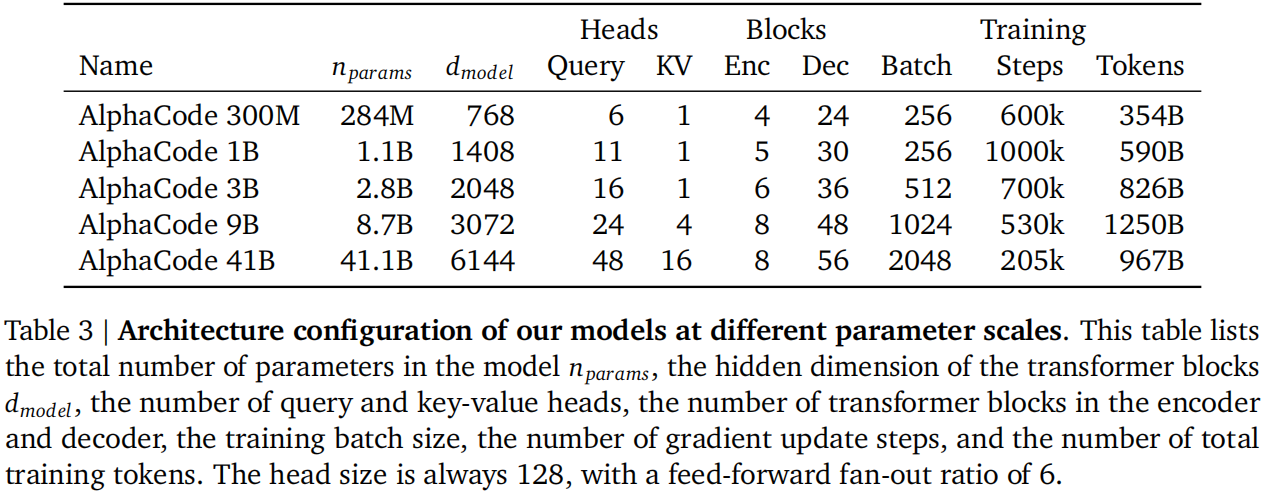
改进:
- 对于query用了不同的投影矩阵,但是对key和value用得是同一个投影矩阵,计算量小一些。
- 解码器的层数是编码器的六倍,编码器比较浅,只要理解一下文本就行,主要还是要生成代码
- 非对称机制:编码器序列长度是1536,解码器序列长度是768,因为transformer的计算复杂度与序列长度呈平方关系,再加上解码器又比较深,所以要尽量对解码器的序列长度进行优化
- 分词器使用“SentencePiece tokenzier”,词库大小是8000
Fine-tuning
- Tempering:用的温度是T=0.2
- Value conditioning & prediction:假设这个问题是正确的,那在输入的问题前那就加入“Correct Solution”,这就是前置;预测就是增加一个损失函数,表示当前解是正确还是不正确的二分类损失
- GOLD:问题有多个解,但算法应该关心只生成一个正确的解,而不是让算法去把正确的和不正确的解全部你和出来。所以在每一个样本前放一个权重,对于某一个问题预测正确的解已经够好时就把权重调高一点,而其他的解就尽量不去看。这种调整的方法细节叫做GOLD,是一种离线的强化学习算法。
Large scale sampling

大范围采样,用了三种方法来生成多样的解:
- 生成一半的python,一半的C++
- 随机化上图提示里面的标签,比如RATING改成100,这样再拼上题目后能得到不一样的输出
- 用高一点的温度,T=0.25
Filtering
对每个题目只把输出预测正确的才留下来,这样能过滤99%模型的输出,还是有10%的问题没有一个答案过不了样例,对其他问题过滤了99%还是有很多答案。
Clustering
训练了一个额外的模型,预测新的测试样例,之前生成的新的测试样例主要是通过一些变异的方法,这里预测的新的测试样例是要用于泛化到没有见过的问题上。
这种生成的样例不一定要正确,接下来把模型样例放进模型生成的代码里面得到输出,根据输出把模型进行聚类。每个类里面代码相似或语义相似,挑出一个就行,其他不用了。
按类大小排序,顺序提交,作者发现这样效果比较好
Result
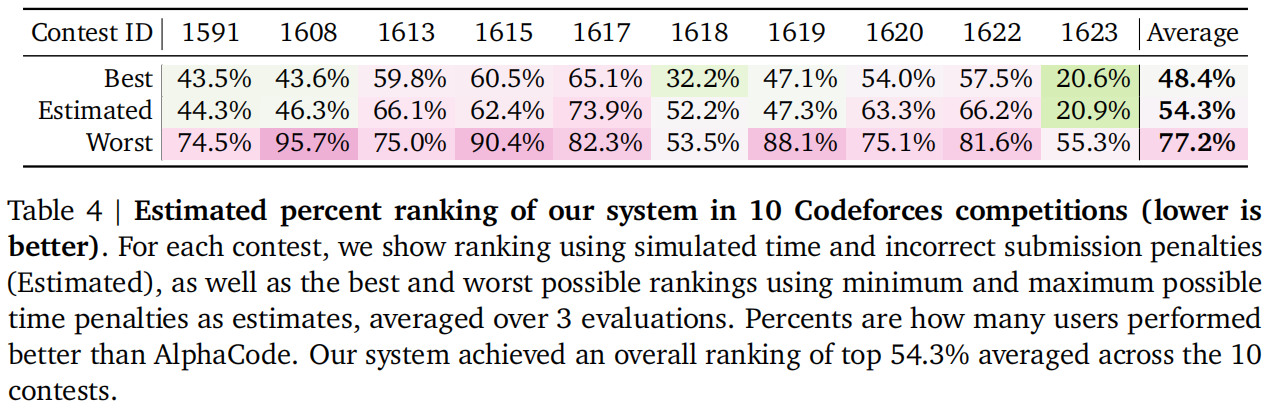
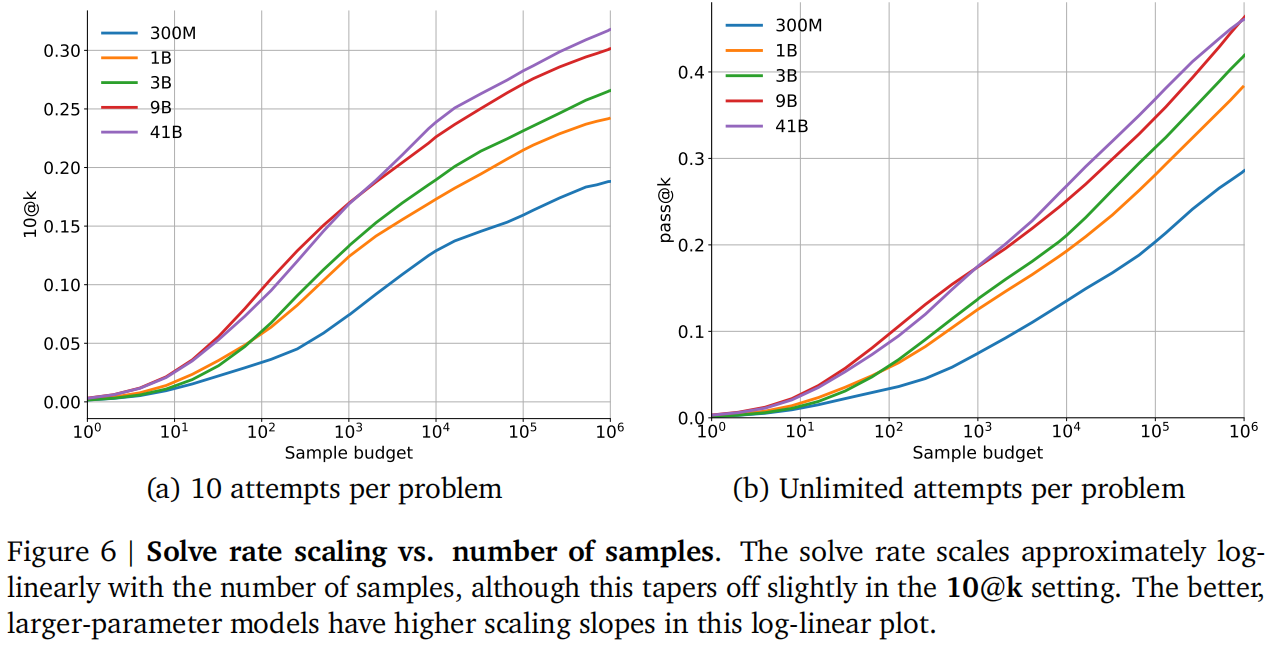
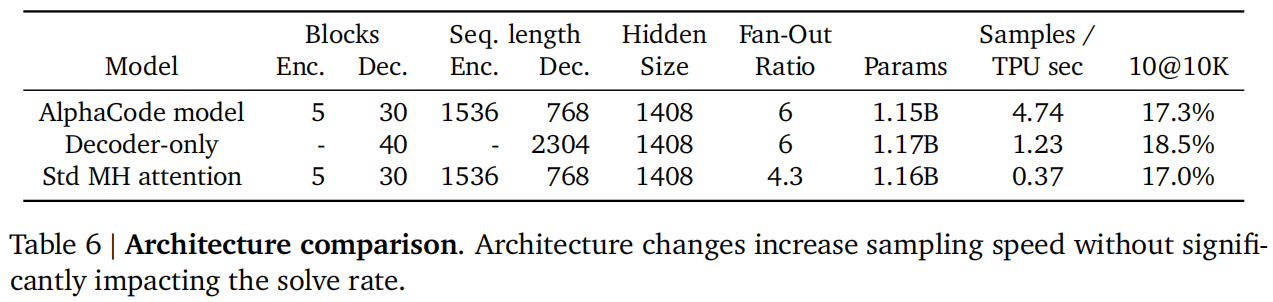
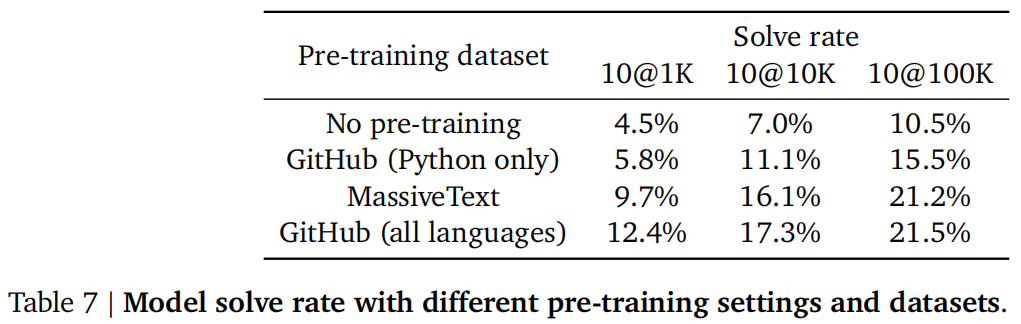
多语言确实有效
Capabilities & limitations
- 模型是否会从训练数据直接复制代码?新问题很难复制粘贴
- 生成的是否有无用代码,比如注释不删等?转AST剪掉没用的枝再生成干净代码
- 简化问题能够提升准确率
- 验证损失不一定越低越好,可能因为一个问题有多个解,所以验证损失不是很有用

