ContraCode:基于MoCo的代码对比学习
Abstract
作者指出RoBERTa模型对于源代码的修改太敏感了,即使这种修改是保留了语义的,所以提出了ContraCode,是基于预训练的方法能够识别相似的变种。
Introduction
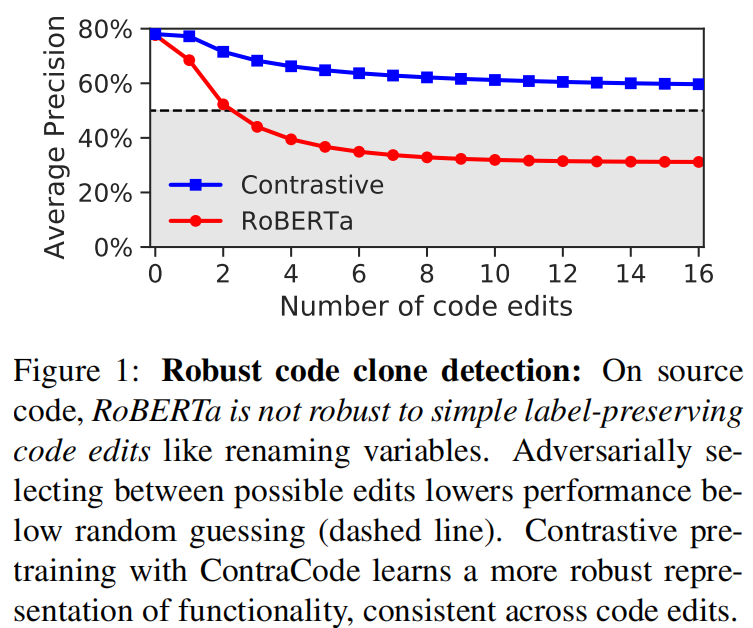
在不改变语义的对抗性修改下,RoBERTa表现甚至比随机分类还差。
作者采用一些源到源的基于编译器的转换技术,比如删除”死“代码:移除不改变代码输出结果的操作
Model
代码转换技术主要分为三类:
- 代码压缩:改变代码的语法结构,并执行修正构造转换,如预计算常数表达式
- 标识符识别:随机替代方法和变量名
- 正则化变换:通过减少具有高文本重叠的平凡正对的数量来改进模型的泛化
通过转换丢弃算法保证多样性,主要是为了保证变换后的代码是修改过的。作者发现再经过20个随机的序列转换方法后有89%的方法有不止一个替代产生。

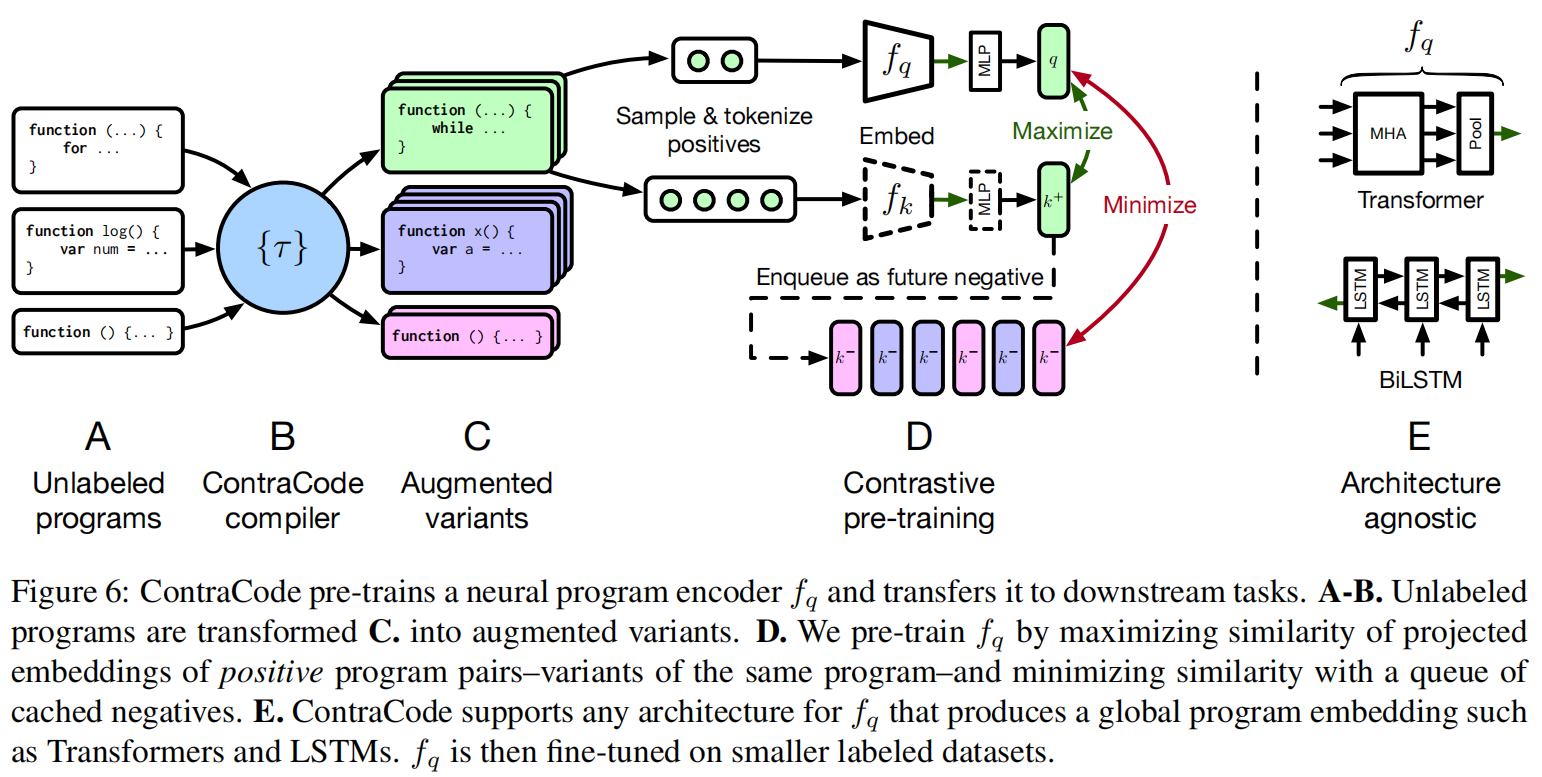
预训练对比学习:
- 扩展了MoCo,从同一程序中生成正样本对,从不同程序中生成负样本
- 一样采用了队列来存储负样本
- 大负样本集,超过10万
ContraCode对于编码器架构是无所谓的,作者试验了双层双向LSTM和六层Transformer
Evaluation
作者做了三个角度的实验,zero-shot推理的克隆检测,基于微调的类型推断。简略代码总结生成
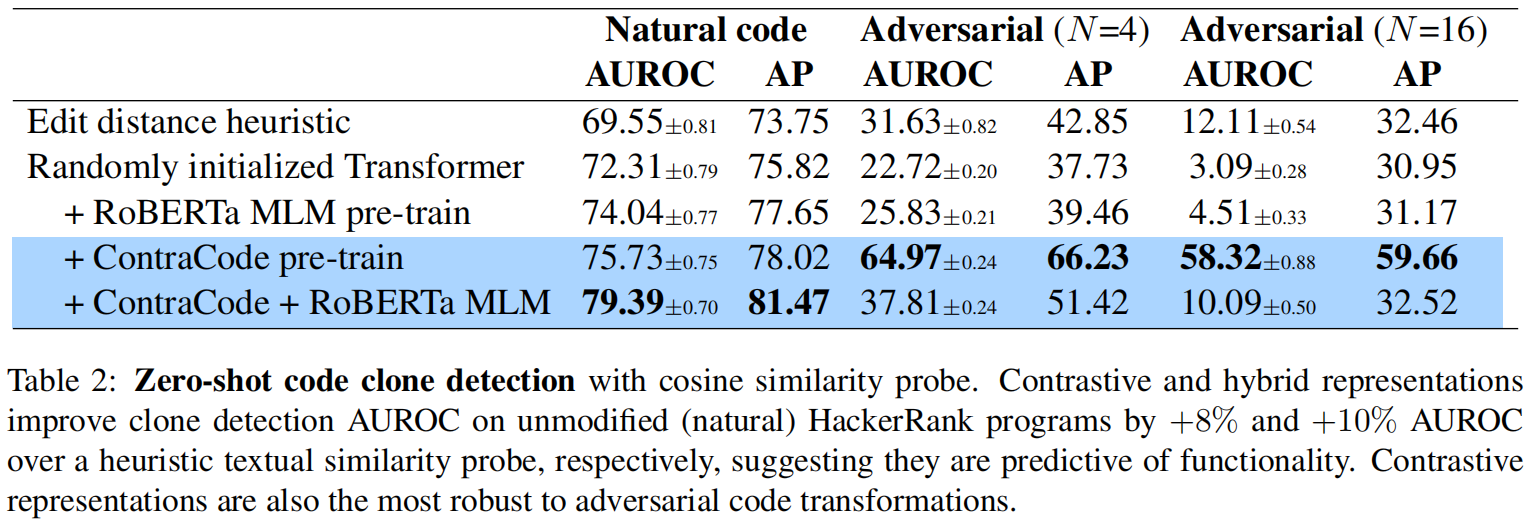
zero-shot Code Clone Detection

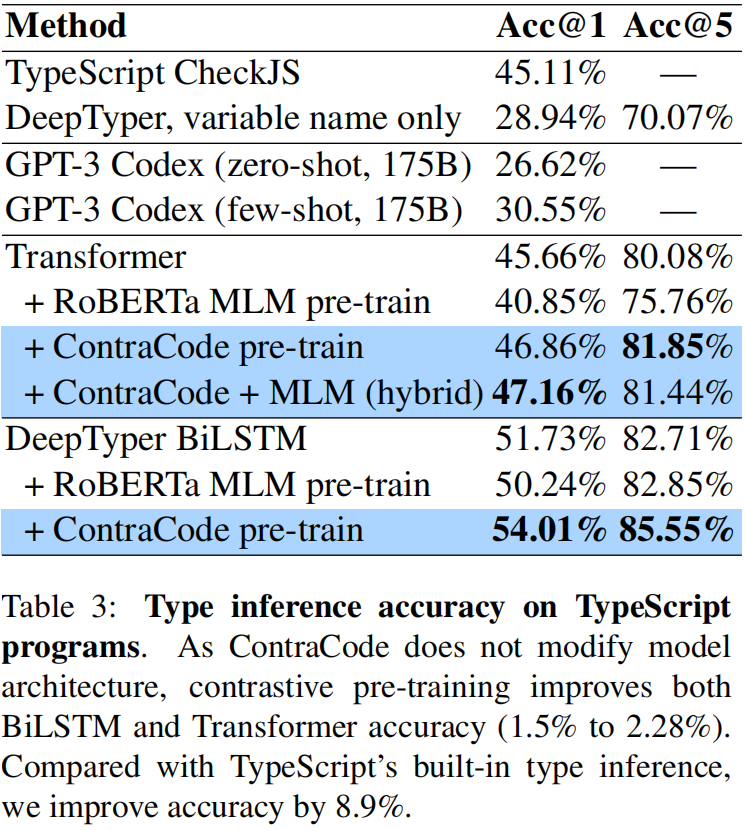
Fine-tuning for Type Inference

Extreme Code Summarization
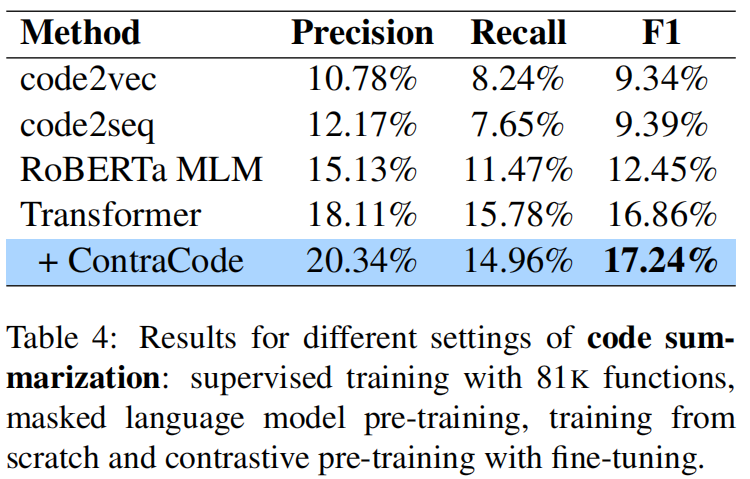

Understanding augumentation importance
对于序列到序列的总结,使用了以下增强技术
- Line subsampling(LS):随机从方法中采用部分行(P=0.9),这种方法没有保留语义,属于正则的一种
- Subword regularization(SW):将文本分词成不同形式,单个词或subtoken
- Variable renaming(VR),identifier managling(IM):改变量名,改标识符
- Dead-code insertion(DCI):插入空指令或log指令
对于类型推断,使用了 LS和SW
还有一些代码增强技术:
- Dead-code elimination(DCE):删除无用代码
- Type upconversion(T):把
&换成and或把true换成1之类的 - Constant folding(CF):预计算变量结果,比如把
(2+3) * 4换成20

