cpt:文本和代码的对比学习预训练出嵌入表示
Abstract
作者展示了对比学习在大规模未标注数据上做无监督可以得到高质量的代码表示,通过线性分类头后在7个任务上可以得到SOTA的结果
Introduction
输入经过Transformer的编码器,同时使用对文本数据,其中网络上的相邻文本片段被视为是正样本对
对比学习的训练信号本身是不足以学习到有用的表示的,所以作者通过其他预训练的模型来初始化,这里引用的是Codex和GPT3
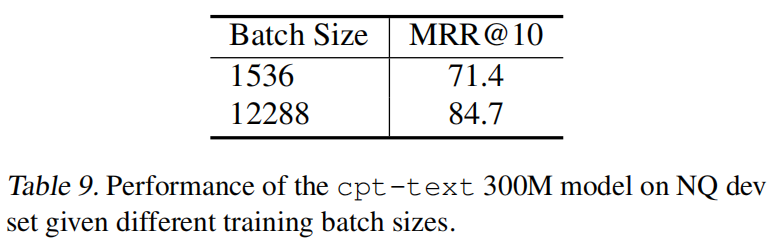
以及作者发现需要一个很大的batch_size来实现优化,采用这种简单的组合大batch_size和预训练模型初始化的对比学习方法能够使文本和代码的embedding适用性更广
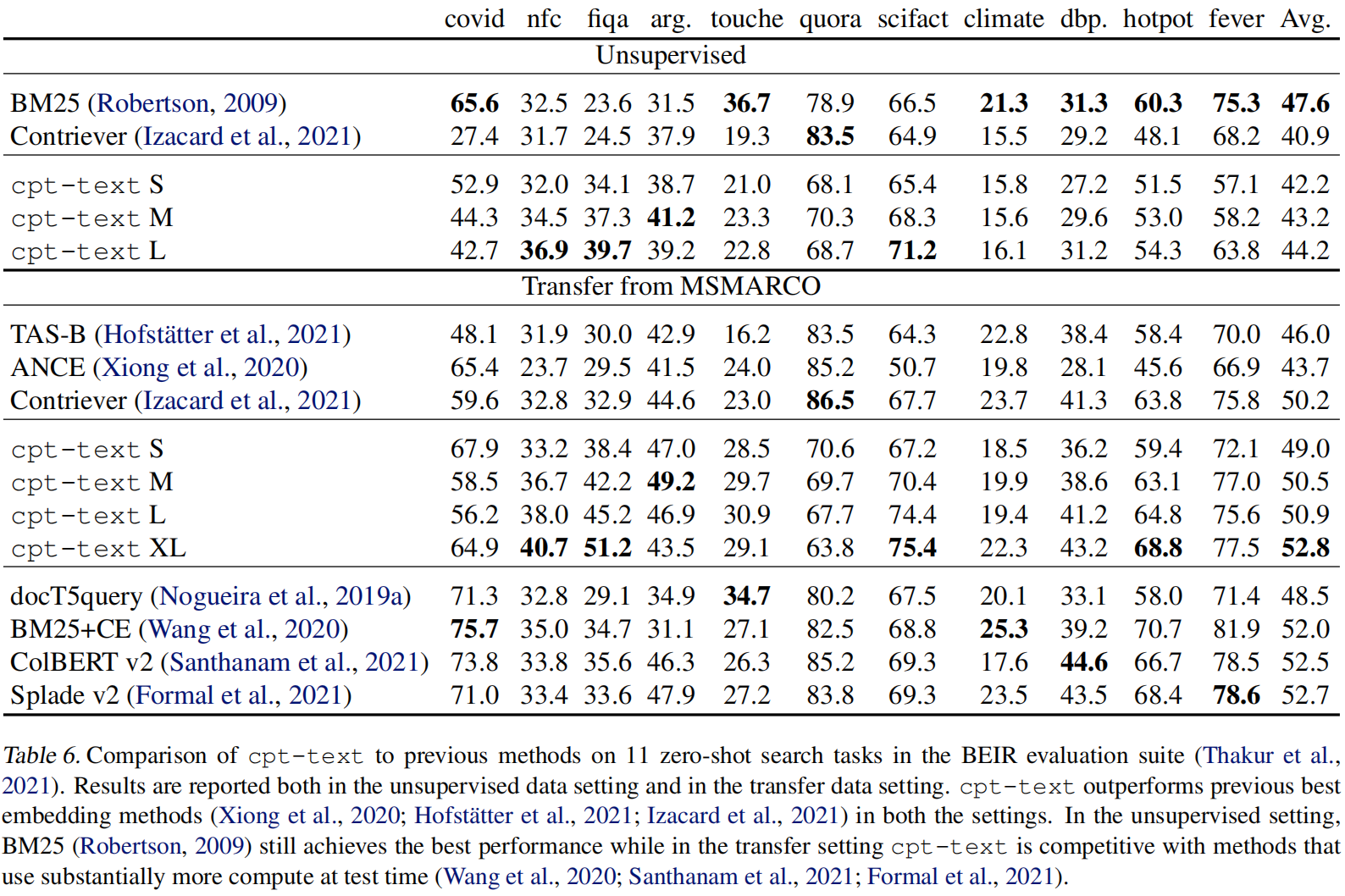
- 先训练了一系列无监督文本嵌入表示的模型
cpt-text,参数从300M到175B,发现模型越大效果越好 - 又使用(text, code)对训练了一个
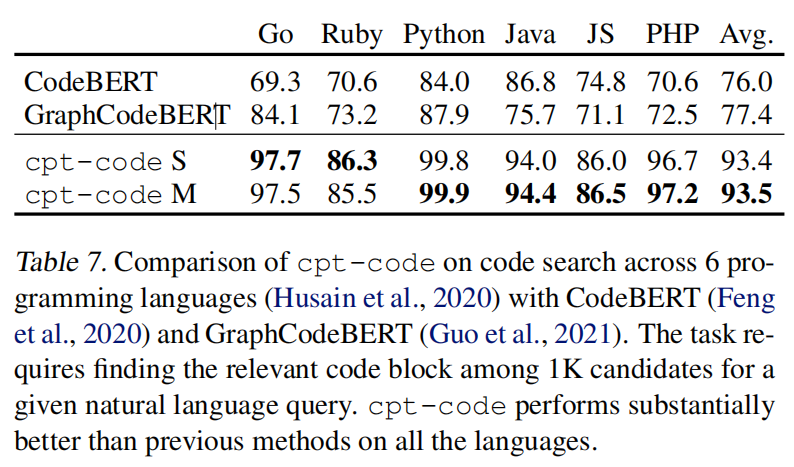
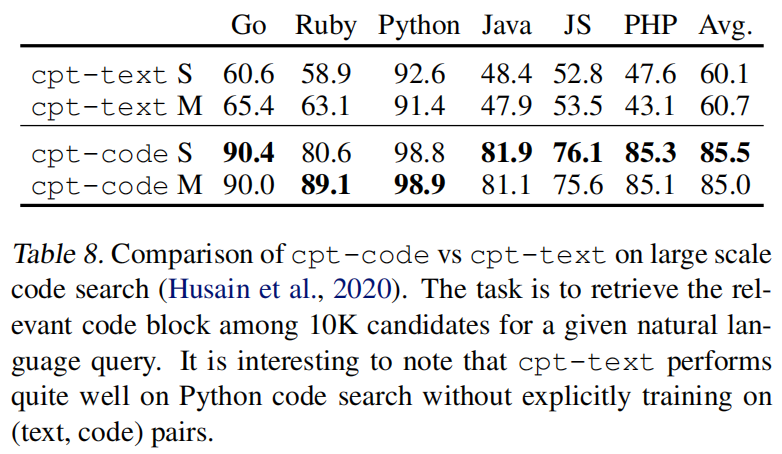
cpt-code,但是与文本模型不同,这次发现参数从300M扩大到1.2B时在代码搜索方面没什么提升
最后的最后是作者做了一系列微调和迁移学习,发现表示确实足够好,即使丢一个K-NN也能媲美神经网络的分类头
Approach
Model
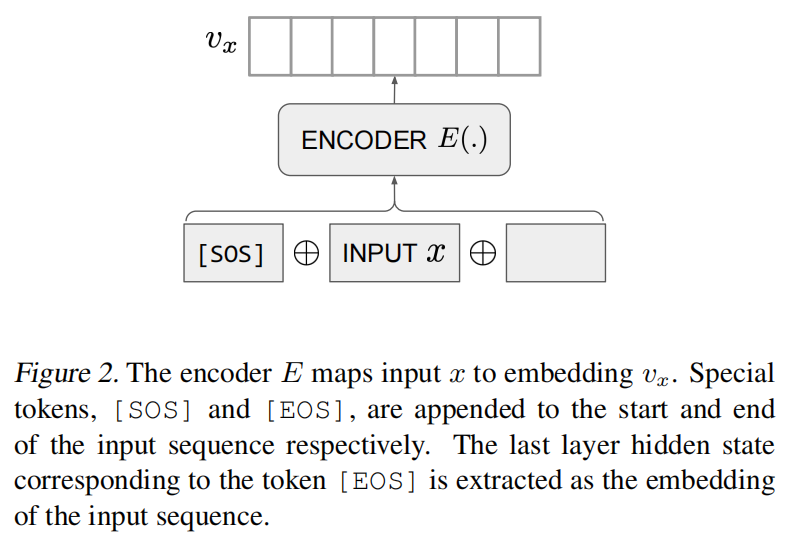
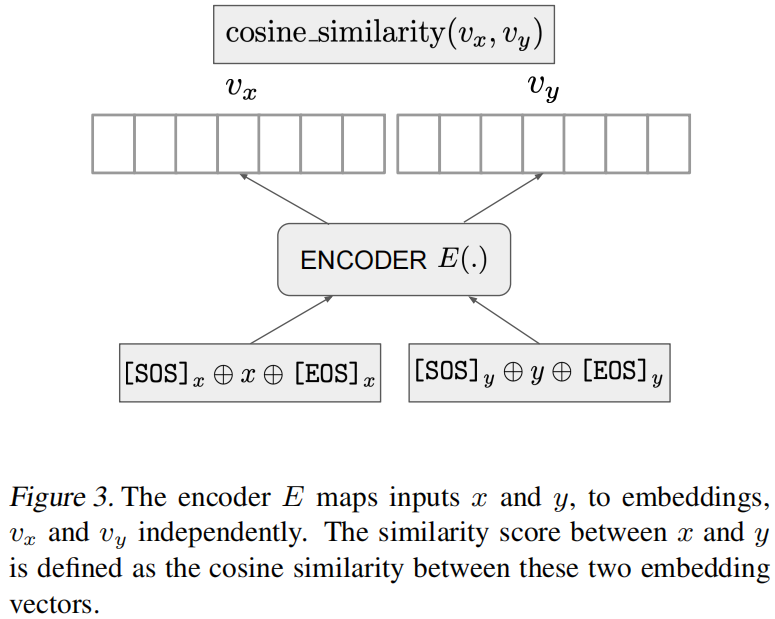
给定一个训练对(x, y)和Transformer编码器E,E去分别处理x和y,用余弦计算相似度
$$
v_x=E([SOS]_x\oplus x\oplus [EOS]_x)
$$
$$
v_y=E([SOS]_y\oplus y\oplus [EOS]_y)
$$
$$
sim(x,y)=\frac{v_x \cdot v_y}{|v_x|\cdot|v_y|}
$$
Training Objective
一个batch中只有一个是正样本,其他都是负样本。logits 是一个MxM的矩阵,每个logit就是 $(x_i,y_j)$。
$$
logit(x_i,y_j)=sim(x_i,y_j)\cdot exp(\tau), \forall(i,j),i,j\in {1,2,\cdots,M}
$$
计算损失
1 | labels = np.arange(M) |
cpt-text 使用GPT模型初始化的, cpt-code 是用Codex初始化的
Results
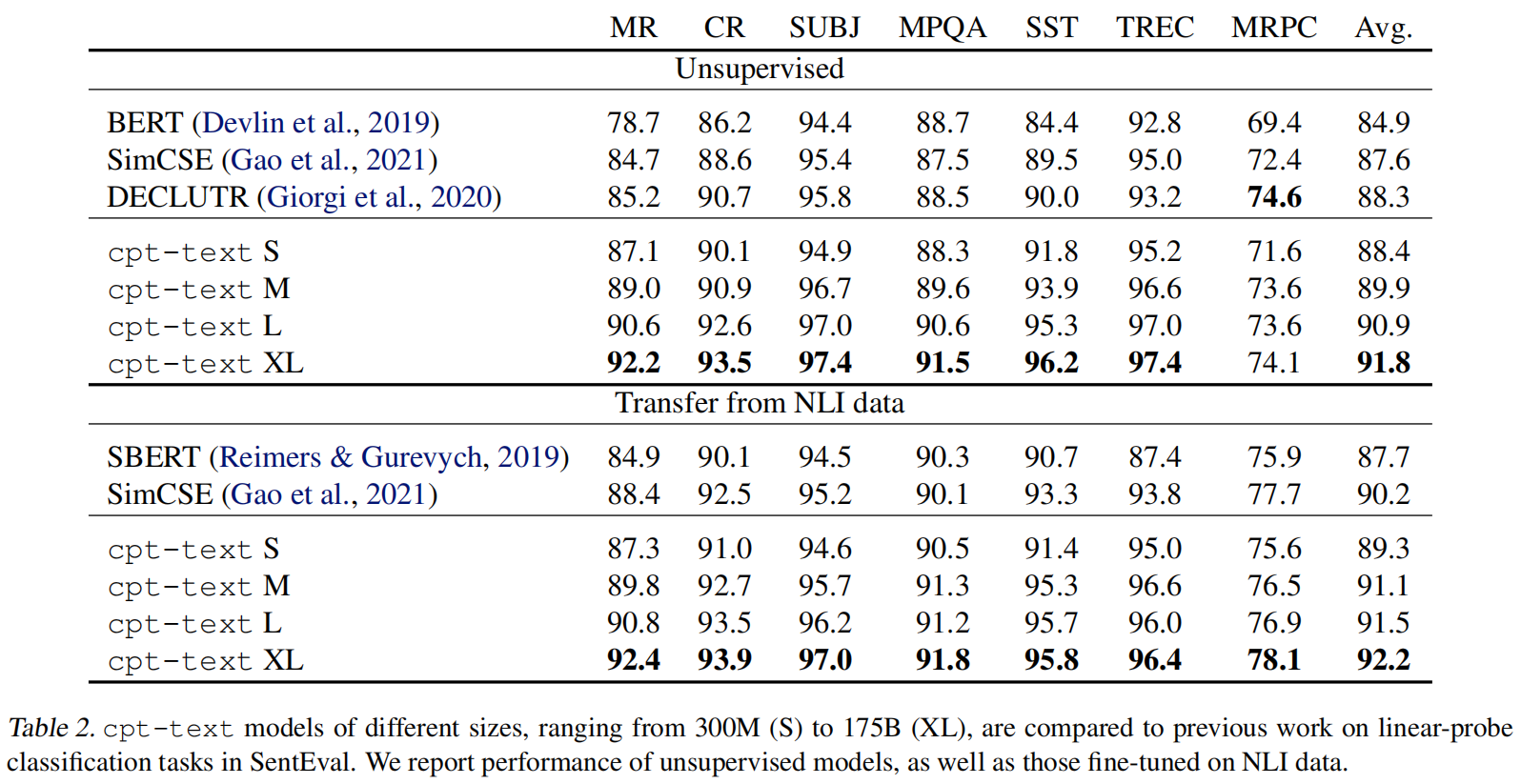
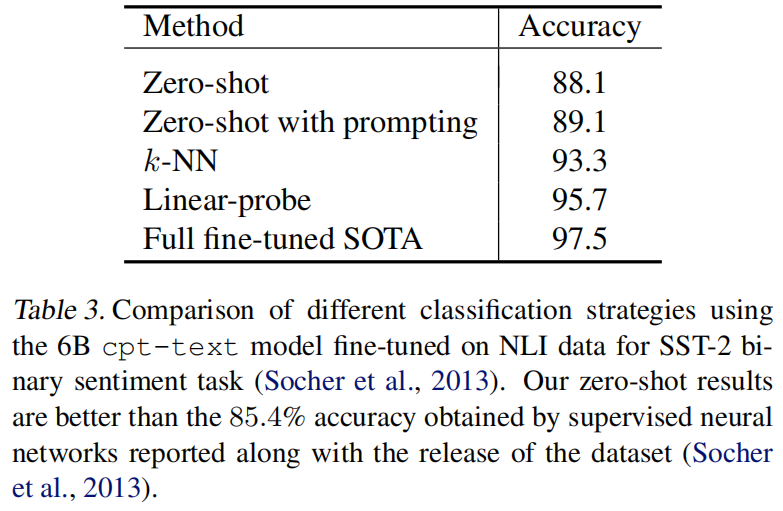
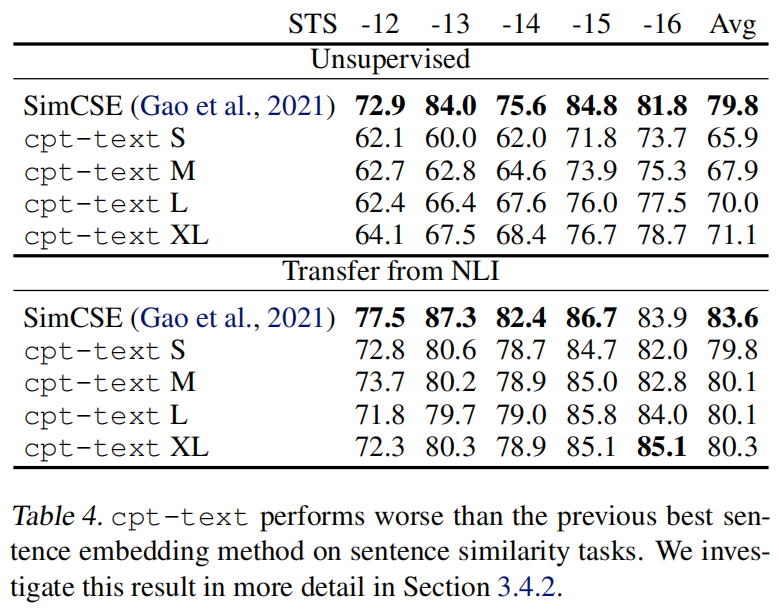
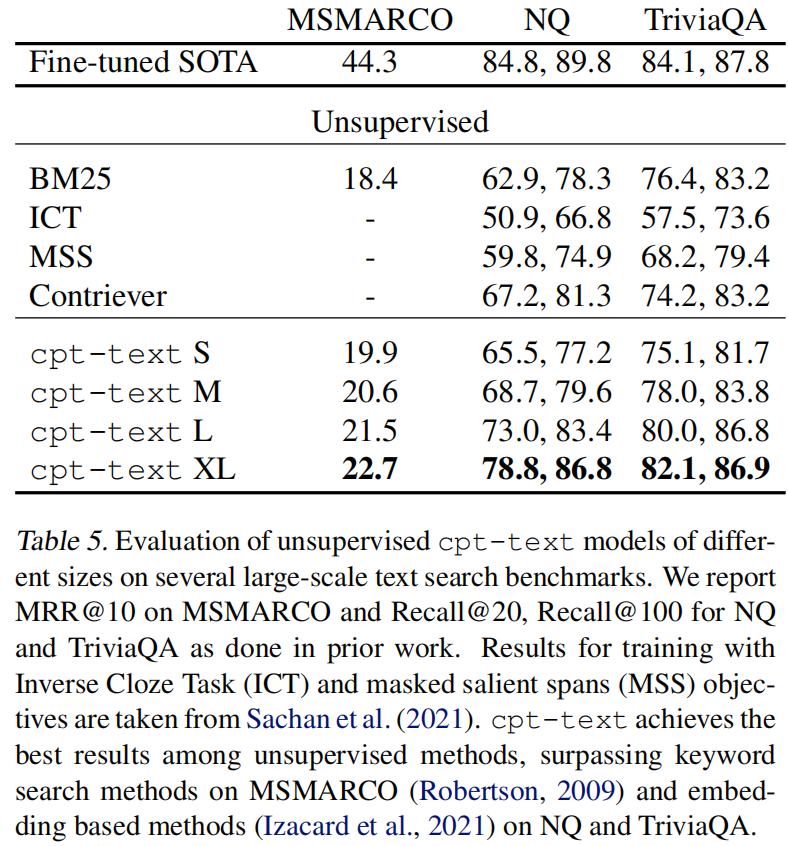
从这里可以看出一个K-NN的分类头能媲美线性分类头