论文地址:CodeBERT: A Pre-Trained Model for Programming and Natural Languages
CodeBERT:面向编程语言的预训练模型
Abstract
作者提出了面向编程语言PL和自然语言NL的双模态预训练模型CodeBERT,可以学习到通用的表征用在下游任务中
在代码搜索和代码文档生成取得了SOTA的结果,但是主要方向还是面向代码搜索
还收集了一个NL-PL probing数据集
Introduction
大规模的预训练模型如ELMo,GPT,BERT,XLNET和RoBERTa等几乎对NLP的所有任务都有着极大的提升,也衍生了很多双模态的工作,比如ViLBERT,VideoBERT从图片/视频和文本进行自监督学习
使用两种预训练任务:
- 标准的掩码语言模型(MLM):
- BERT中的任务,mask后预测
- 使用的是NL-PL数据对进行预训练
- 替换词元检测(RTD):
- 首先使用一个生成器预测句中被mask掉的token,接下来使用预测的token替代句中的[MASK]标记,然后使用一个判别器区分句中的每个token是原始的还是替换后的
- 单模态的代码用于RTD任务中学习出更好的生成器
主要贡献是:
- 第一个用于多语言的大规模的NL-PL预训练模型
- 实验性结果展示CodeBERT在代码搜索和注释生成任务的有效性
- 创建了一个数据集去用于研究基于代码的预训练模型的识别能力
Model
Model Architecture
CodeBert基于多层双向transformer网络,一共12层,每层12个Attention head,与RoBERTa的模型基本一致,有125M个参数
Input/Output Representations
输入是自然语言和代码片段用特殊符连起来,例如 $[CLS],w_1,w_2,\cdots,w_n,[SEP],c_1,c_2,\cdots,c_m,[EOS]$
输出包括每个词元的上下文向量表示和用于分类的[CLS]的表征
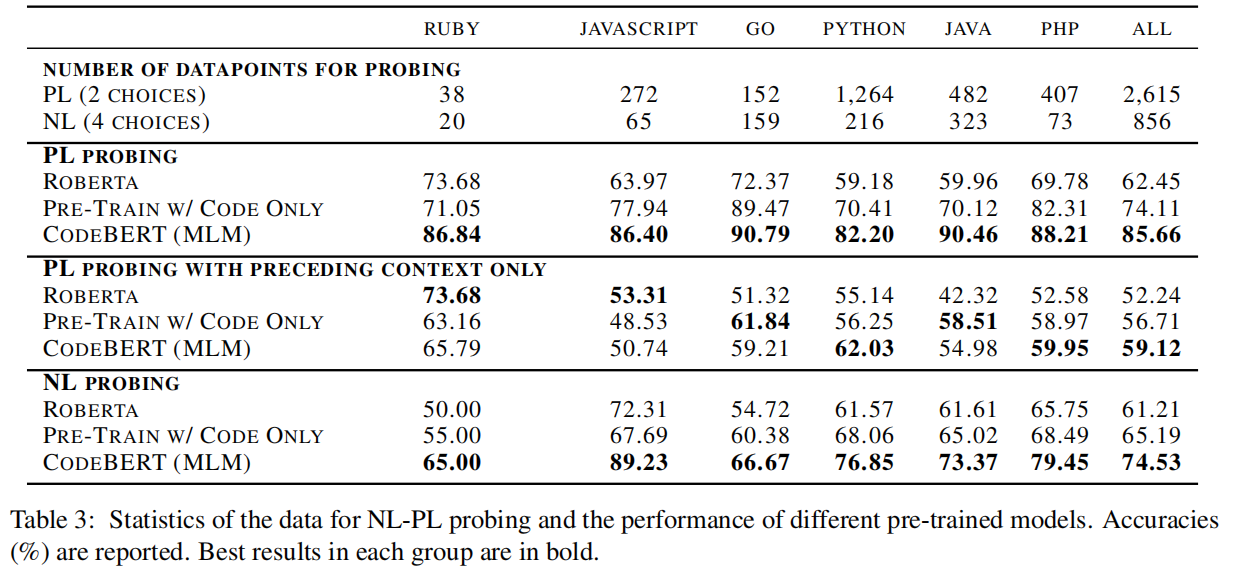
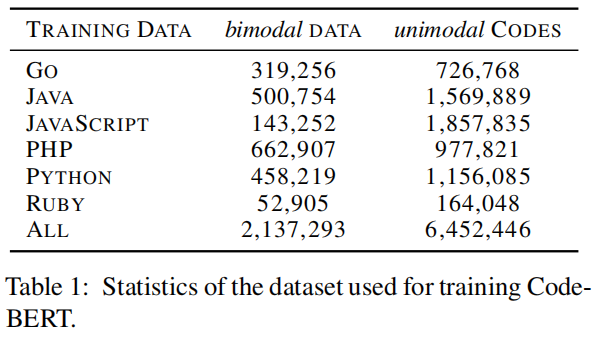
Pre-Training Data

数据样例如上图所示,同时作者做了一系列约束:① 每个项目至少被一个其他项目使用;② 每个文档都被截断成一段;③ 文档小于3个词元的移除;④ 代码少于3行的被移除;⑤ 带有子字符串“test”的函数名被移除。
Pre-Training CodeBERT
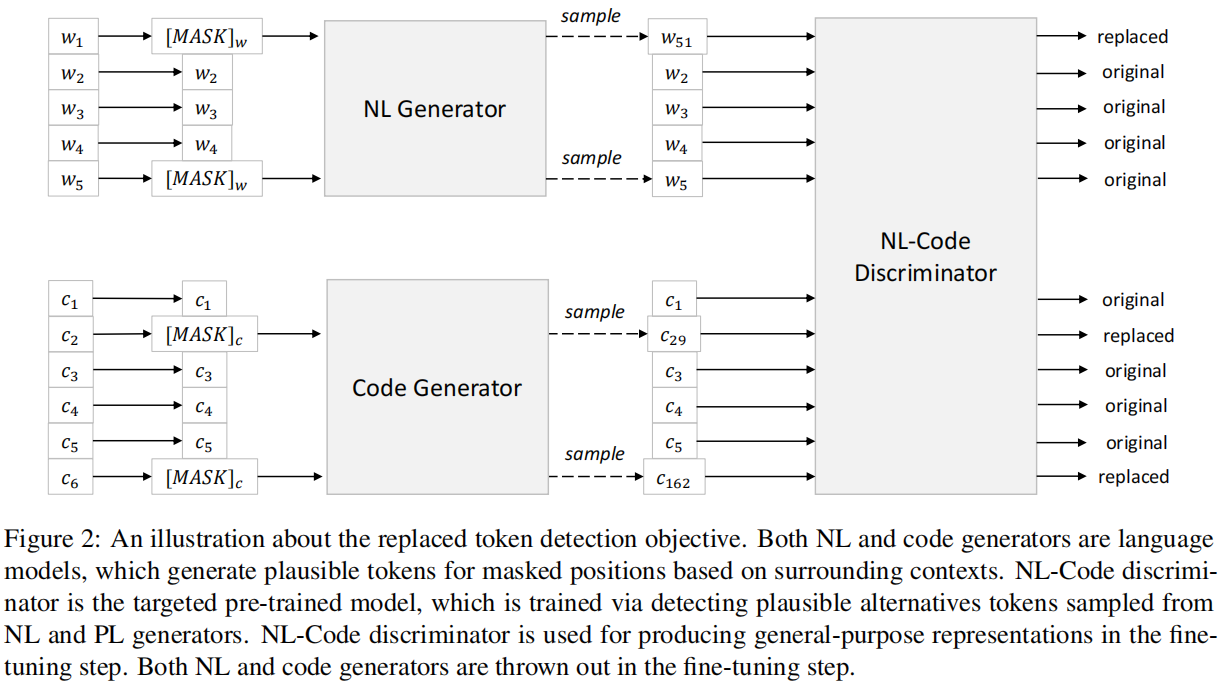
作者在本文中使用了两个预训练任务
- 一个是MLM的BERT的掩码语言模型,随机选取单词mask掉,然后进行预测,这个任务中是使用NL-PL对来预训练
- 随机选择15%的token,其中80%被[MASK]替换,10%随机替换,10%保持不变,随后将替换后的句子输入到BERT中用于预测那些被替换的token
- RTD任务用的是PL和NL单模态数据
- 来源于ICLR2020的文章ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators,由于在BERT中传统的MLM任务只学习15%的token有点浪费算力,而且[MASK]是不会出现在真实的环境与测试环境中,导致了一定的不一致问题
- 首先使用一个生成器预测句中被mask掉的token,接下来使用预测的token替代句中的[MASK]标记,然后使用一个判别器区分句中的每个token是原始的还是替换后的
Fine-Tuning CodeBERT
本文在自然语言代码搜索、代码文本生成这两个下游任务上进行fine-tuning,对于自然语言代码搜索任务,使用[CLS]的表示来衡量自然语言查询与代码之间的语义相关性,对于代码文本生成任务,使用encoder-decoder框架,CodeBert模型用来初始化encoder部分。
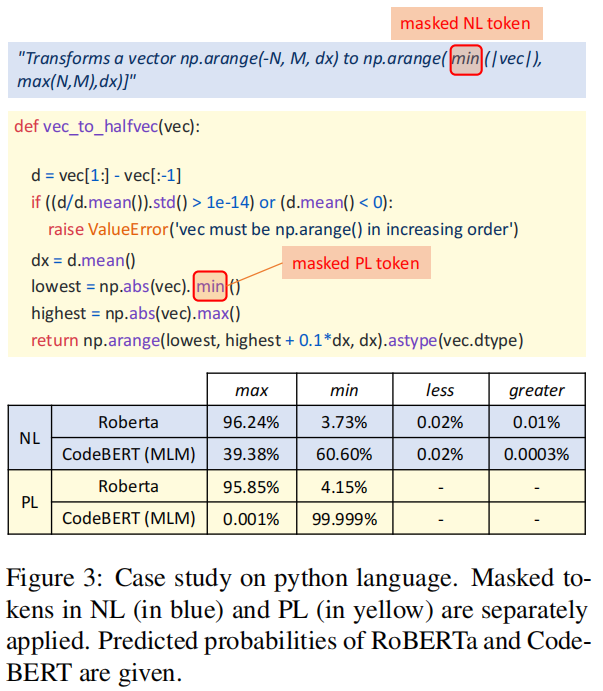
Experiment
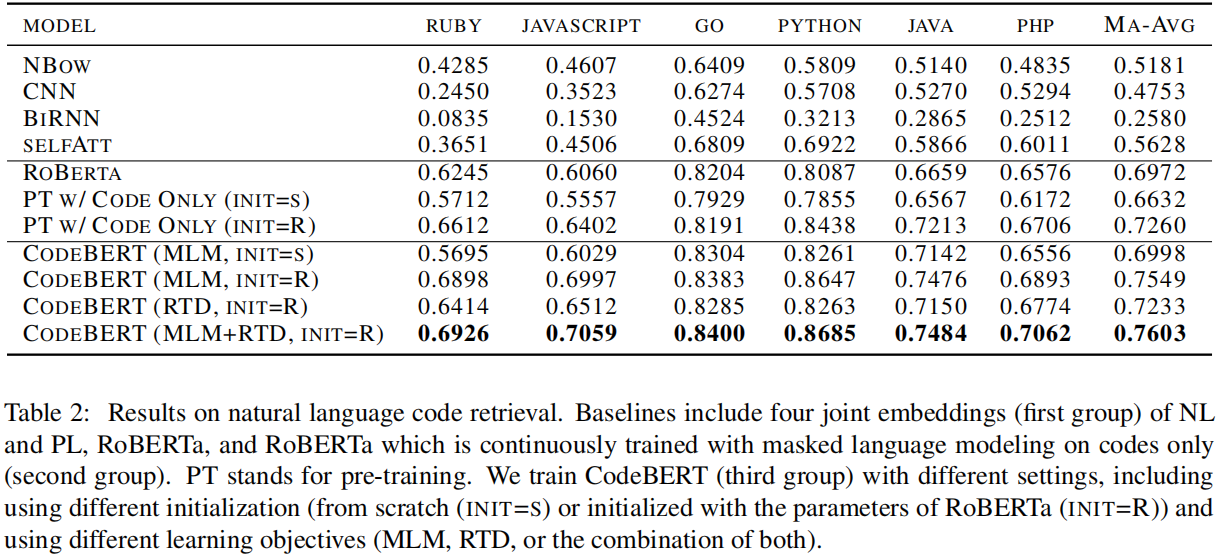
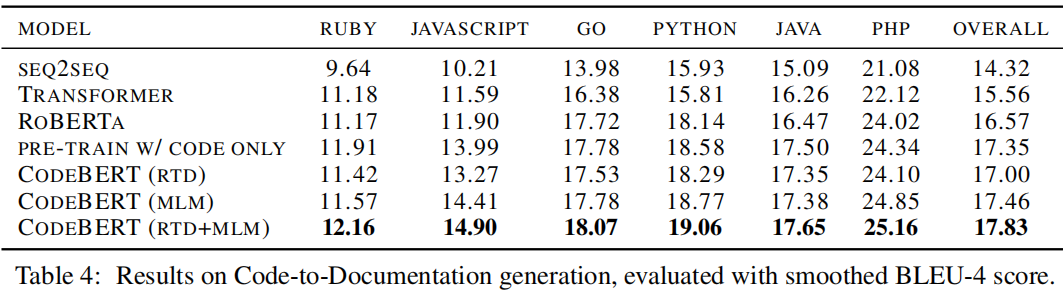
本文除了在2个fine-tuning任务上进行验证外,还探究了CodeBert模型具体学习到了哪些类型的知识,给定一个NL-PL对,Probing实验的目标是在一些干扰选项之间选择正确的masked token,具体是设定一些cloze-style的问题,即使用[MASK]替代某个token,然后让模型选择正确的选项,其中干扰项是根据专业知识选取出来的。