论文地址:Beyond Short Snippets:Deep Networks for Video Classification
来自谷歌的工作
稍长的视频处理:池化和LSTM在视频理解的作用
Abstract
提出两种方法处理长的视频,一是尝试了不同的池化操作,二是采用LSTM链接CNN的输出
Apporach
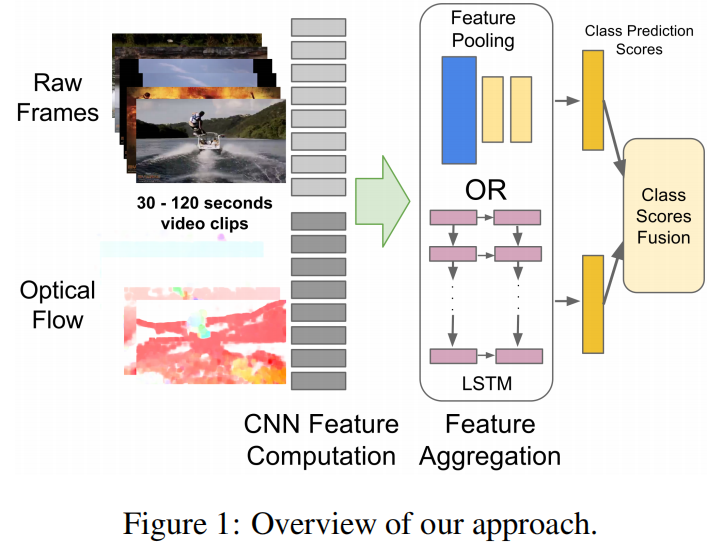
如果按照双流网络的思想去做,原始视频就几帧就太短了,如果有特别多的帧怎么办呢?
首先对于所有的帧肯定是要去抽特征,比如原始的手工或卷积神经网络,关键在于抽取到特征之后怎么去做pooling这个操作,可以简单的做一个max或average,这篇文章对这个做了很多的探索,最终的结论表示都差不多,ConvPooling最好。以及尝试了用LSTM去做特征融合,但实际上提升有限
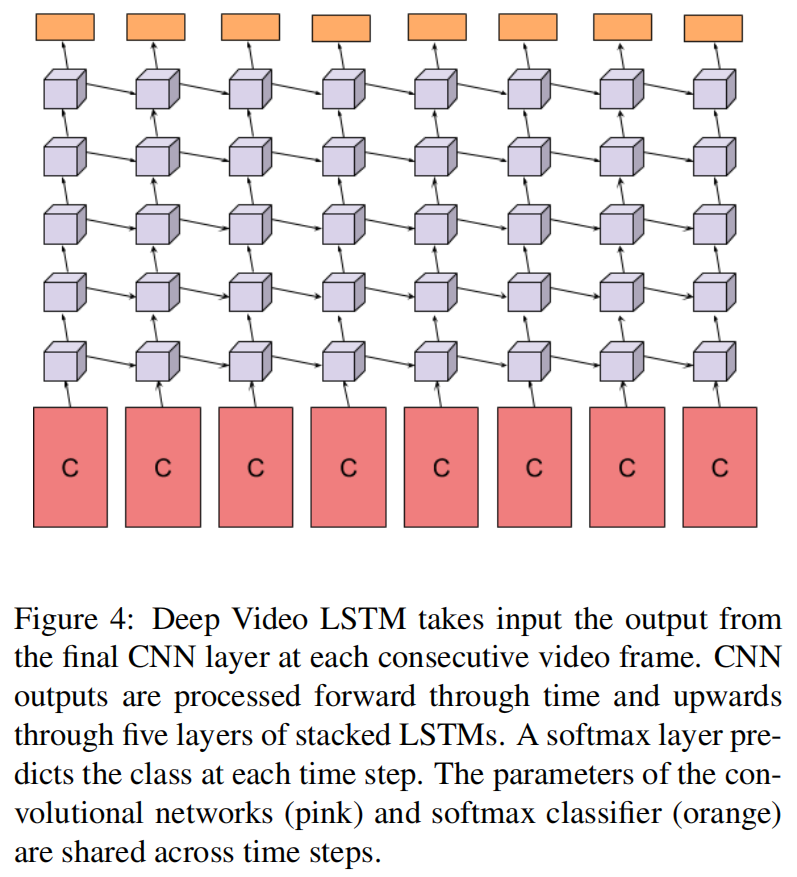
每个视频帧对应一个卷积网络(权值共享)去抽取特征,用了五层LSTM,最后softmax
Result

在Sorts-1M数据集上LSTM没有想象中那么有用,可能是因为LSTM学到的东西比较high-level,视频即使帧比较多还是比较短,在这种情况下实际上语义信息并没有太多改变,相当于传了一些差不多的内容给LSTM,说实话LSTM可能也学不到什么,最终也就带不来很大的提升。在变化比较剧烈的情况,或者长视频上,LSTM应该还是有一定意义的
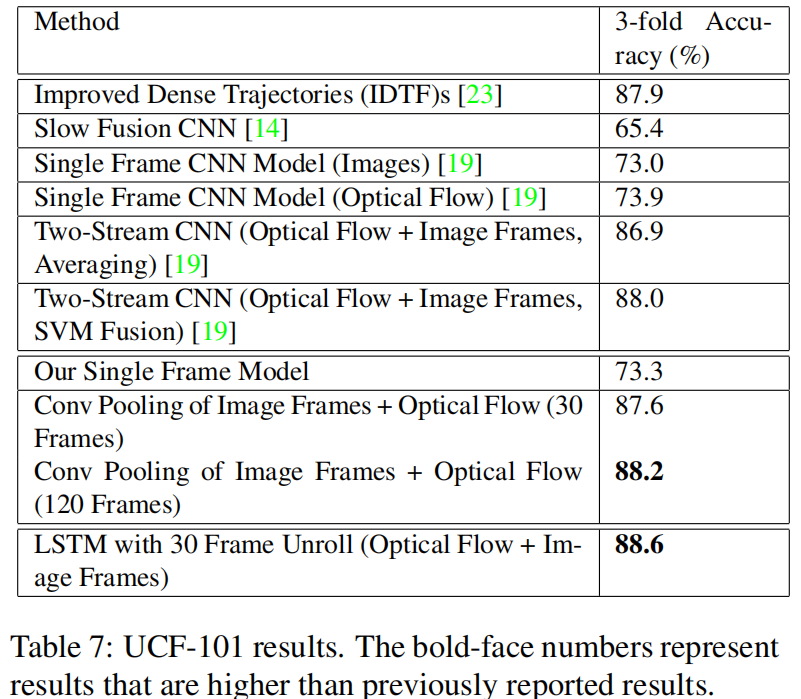
在UCF-101效果就都只是好了一点,提升非常有限

