论文地址:Convolutional Two-Stream Network Fusion for Video Action Recognition
双流如何做Fusion:用Early稍好
Abstract
研究了一系列如果融合光流和空间流的方法,使用temporal fusion还是spatial fusion,决定后在哪一层做fusion,最终得到一个比较好的fusion结构
Approach
Spatial fusion
有时间流和空间流后如何保证在同一像素位置通道的response能联系起来:
- Max fusion,两个同样位置取最大
- Concatenation fusion:链接起来
- Conv fusion:两个图堆叠起来再做一个卷积操作
- Sum fusion:加法
- Bilinear fusion:做矩阵的outer product,在所有维度上做加权平均
Where to fuse the networks
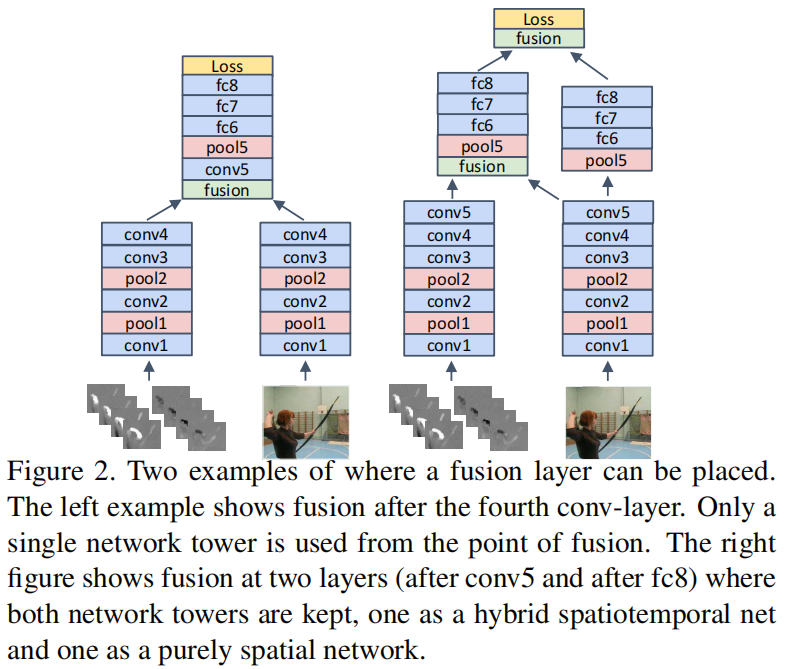
- 空间流和时间流分别做,在Conv4做fuse
- 先分别做,把空间流拿过来合并,同时保持空间流完整性,最后再做合并
Temporal fusion
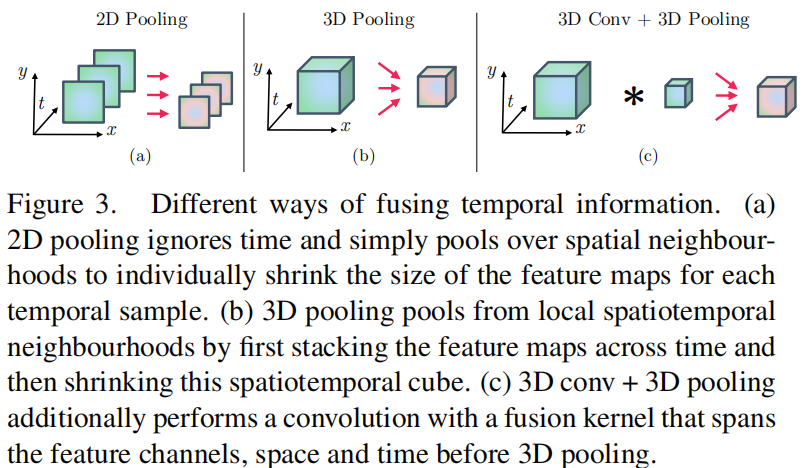
- 2D pooling
- 3D pooling
- 3D conv + 3D pooling
Proposed architecture
时空学习+时间学习
两个最终分类头加权平均一下得到最终结果
Evaluation
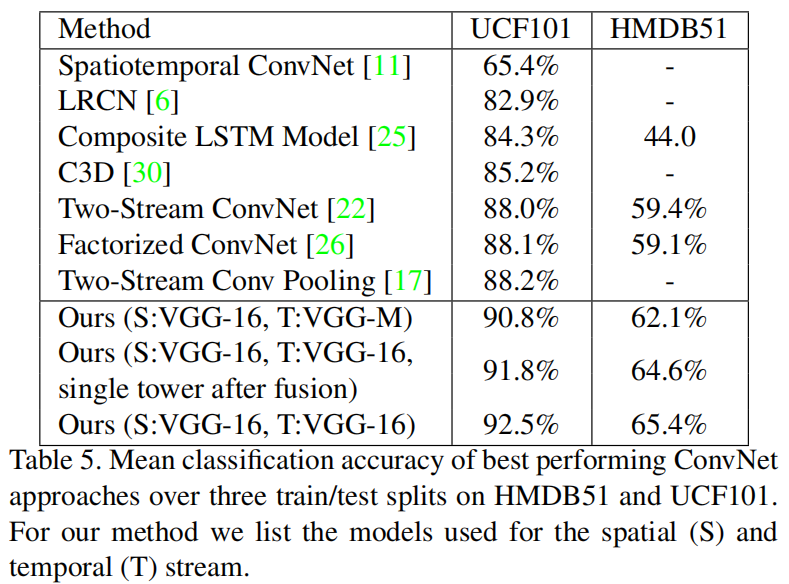
数据集特别小的情况用特别深的网络容易过拟合。改成early fusion方法在HMDB51上提升很明显

