论文地址:Large-scale Video Classification with Convolutional Neural Networks
DeepVideo:使用深度学习处理视频理解的最早期工作之一
Abstract
把卷积网络应用到视频分类上
Model
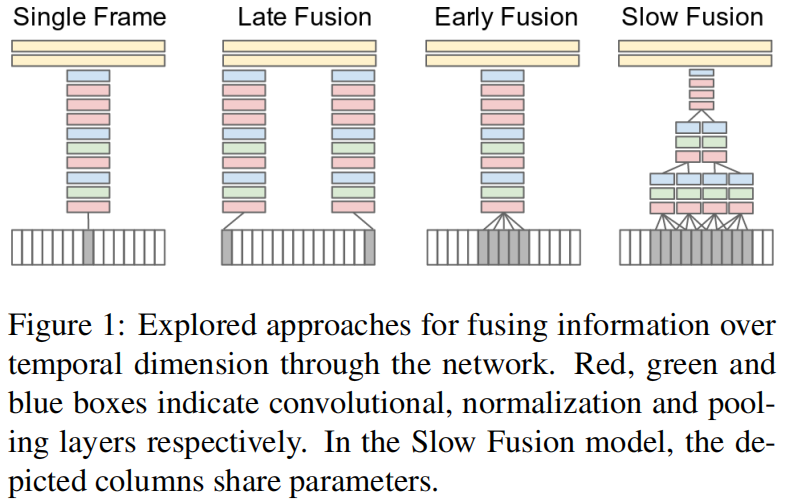
- Single Frame:就是一个图片任务,通过神经网络,2层FC得到结果
- Late Fusion:网络输出层做结合,特征权值共享最终结合
- Early Fusion:在输入层面融合,五个帧合起来
- Slow Fusion:抽出开始的特征后慢慢合并,再做卷积操作合并特征
但实际上以上效果差别不大,而且即使在100万个视频上做预训练之后,在UCF-101那个小数据上做迁移的时候还比不上手工特征,所以作者开始尝试下面这条路
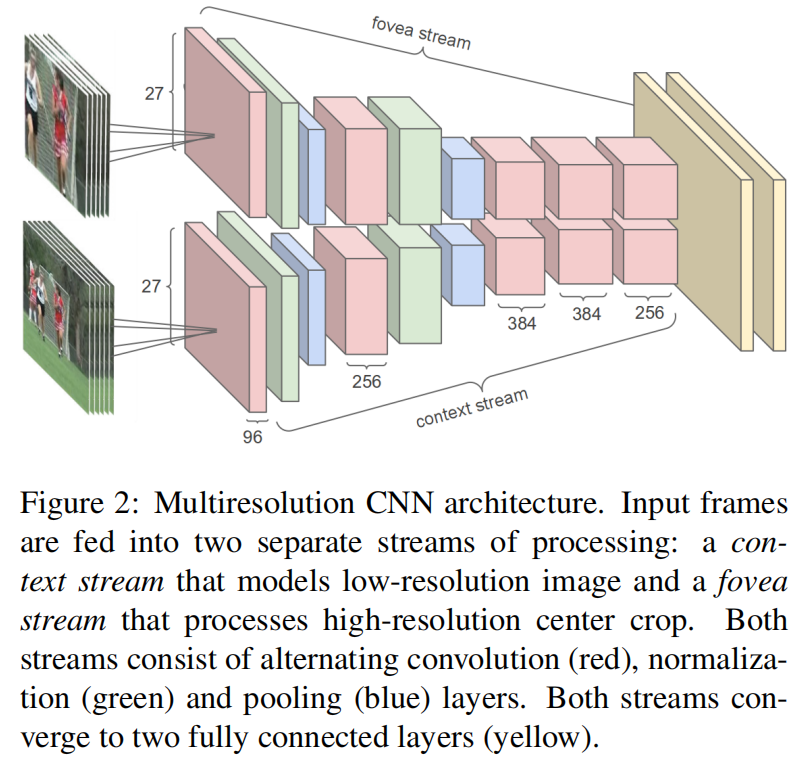
既然2D卷积网络学时序特征很难,不好学,那就先不学了,把图像那边一些好用的trick拿过来看看是否也能工作得很好,也就是多分辨率卷积神经网络,原图+抠出来的图,两个网络权值共享
Experiment
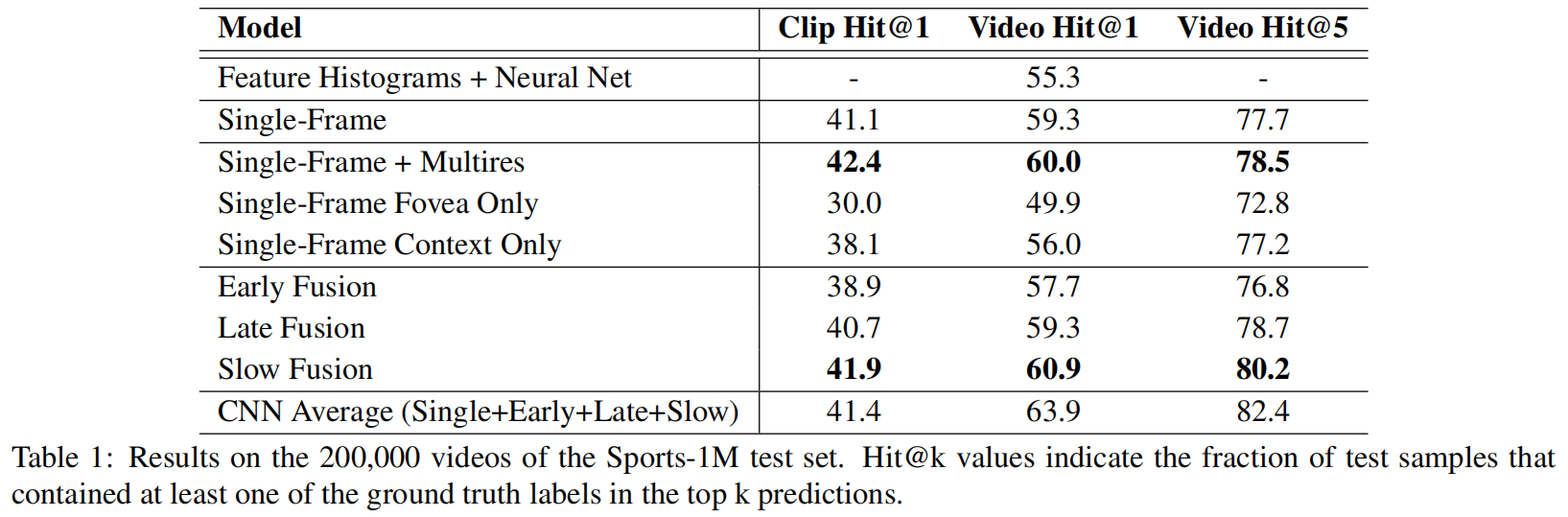
有提升但还是比较小,Early Fusion确实太Early了,效果还不如baseline,Late Fusion一样也不咋地
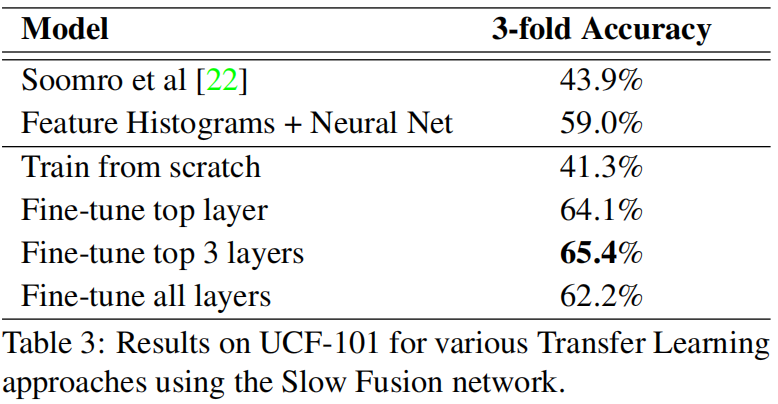
换到UCF-101数据集最好的变体效果也一般65.4%,手工方法都已经87%了

