论文地址:Temporal Segment Networks:Towards Good Practices for Deep Action Recognition
TSN+Practices:时空分割网络和视频学习的技巧
Abstract
提出了结合稀疏时间采样策略和视频级别的监督学习的TSN框架,在时空分割网络帮助下的一系列对于视频理解的技巧,包括数据增强、初始化、防止过拟合等等
Model
Temporal Segment Networks
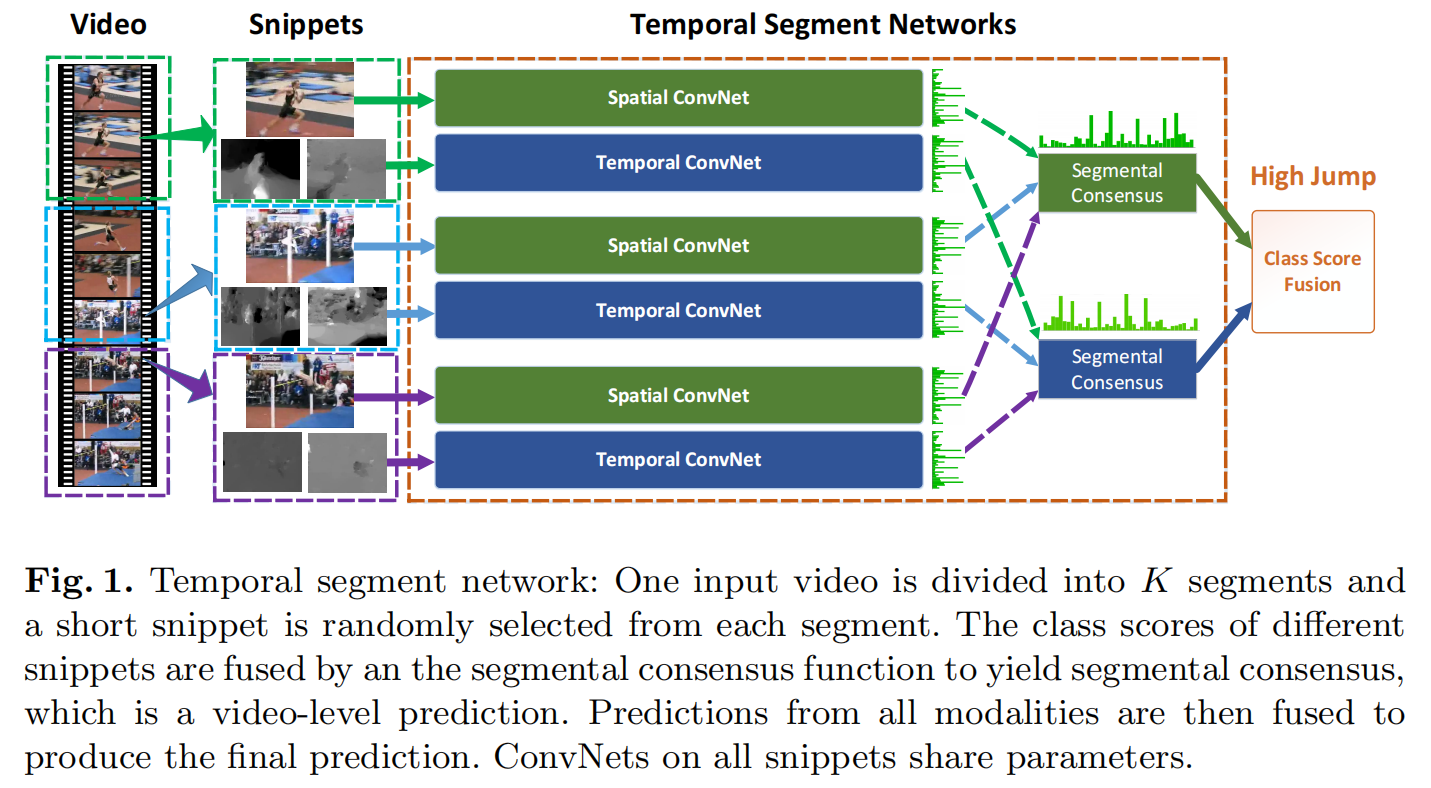
模型其实还是比较简单,主要就是视频分段+Segmental Consensus,但是效果非常好,也是非常有新意的一种体现。其实做很长的视频也是一样的道理,即使语义不同,就大不了不加Segmental Consensus(不做语义融合),加一个LSTM去学习也是一个想法
-
如果有一个原始的双流网络,每次能覆盖的图像最多也就是10帧,不到半秒
-
TSN想覆盖更长的时间就把视频分割成几段,比如上图的三段,每一段随机抽取一帧当作RGB图像,然后以这一帧为起点选几帧算光流图像,通过双流网络,最后生成两个logits,其他段同理
-
TSN的意思指即使抽出来的帧表面上看起来不一样,但高层的语义信息应该表示的是一个意思,然后把空间和时间上的语义做Segmental Consensus融合特征,最后做一个late fusion
Learning Temporal Segment Networks
Cross Modality Pre-training
这里的多模态就是图像和光流
图像这边可以用imageNet的预训练来微调,但是光流这边如果用小数据从头训练的话可能效果不太好,所以作者表示把imageNet预训练好的直接给光流用效果也非常好
但这里主要的问题是imageNet输入是RGB通道的图像,光流的输入是10张光流图,和x,y两个位移的channel,作者就把RGB模型的第一层卷积的权重拿出来平均,这下三个通道变一个通道了,然后把这个通道复制20遍,这种初始化方式是非常有用的
Regularization Techniques
Batch Normalization虽然能让训练加速,但是也带来了过拟合问题,于是就提出了partial BN
- 本来的动机是说如果BN层可以微调的话,因为数据集比较小,一调就过拟合了,所以其实是不想调,最好是冻起来。但是如果全冻起来迁移学习的效果就不太好,毕竟之前的数据集是图像的不是视频动作识别了
- partial BN就是把第一层BN打开,其他冻住,因为输入变了,所以第一层必须学一学才适应新的数据集,但是后面就不用开了,不然容易过拟合
Data Augmentation
- corner cropping:
- 作者发现如果做random cropping经常是图像正中间或中间附近,很难裁剪到边边角角,作者就强制让能裁剪到边角
- scale-jittering:
- 改变图片长宽比,先把图片缩放到256x340,然后从{256,224,192,168}中选长宽组合做裁剪
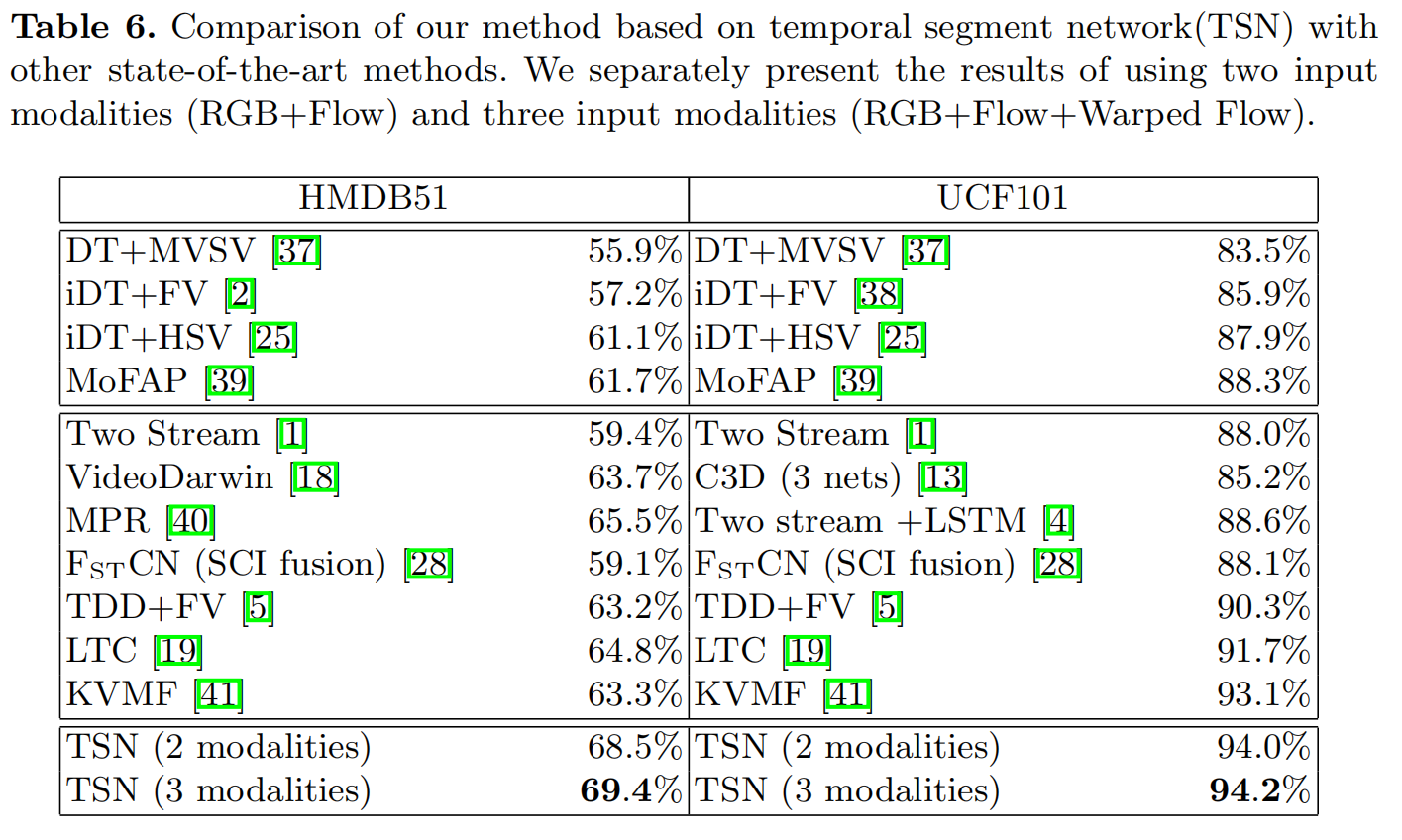
Experiment