论文地址:GraphCodeBERT:Pre-training Code Representations with Data Flow
GraphCodeBERT:通过数据流做预测
Abstract
提出利用代码内在的语义结构的预训练模型GraphCodeBERT,不用AST,在预训练阶段用数据流(值从哪来),这种语义结构不复杂,也不会带来AST那种没必要的深层次结构,让模型更有效
两个预训练任务:数据流边预测、源代码和数据流的变量对齐。这种方法在4个下游任务上取得了SOTA
Introduction
没有语义光靠名字很难预测,比如 v=max_value-min_value,光靠v这个变量名,不依靠变量数据流很难猜它是什么意思
因此本文提出了GraphCodeBERT,用数据流做代码的表征,摈弃了AST的不必要复杂性,以及提出了两个与训练任务:
- 数据流边预测:通过预测数据流图的边,来学习代码的结构化表示
- 源代码和数据流的变量对齐:学习数据流图的节点来自源代码中的哪个token
本文将在4个下游任务上评估GraphCodeBert预训练模型,分别是:
- 代码搜索任务 code search
- 代码克隆检测任务 code clone detection
- 代码翻译任务 code translation
- 代码精炼任务 code refinement
Data Flow
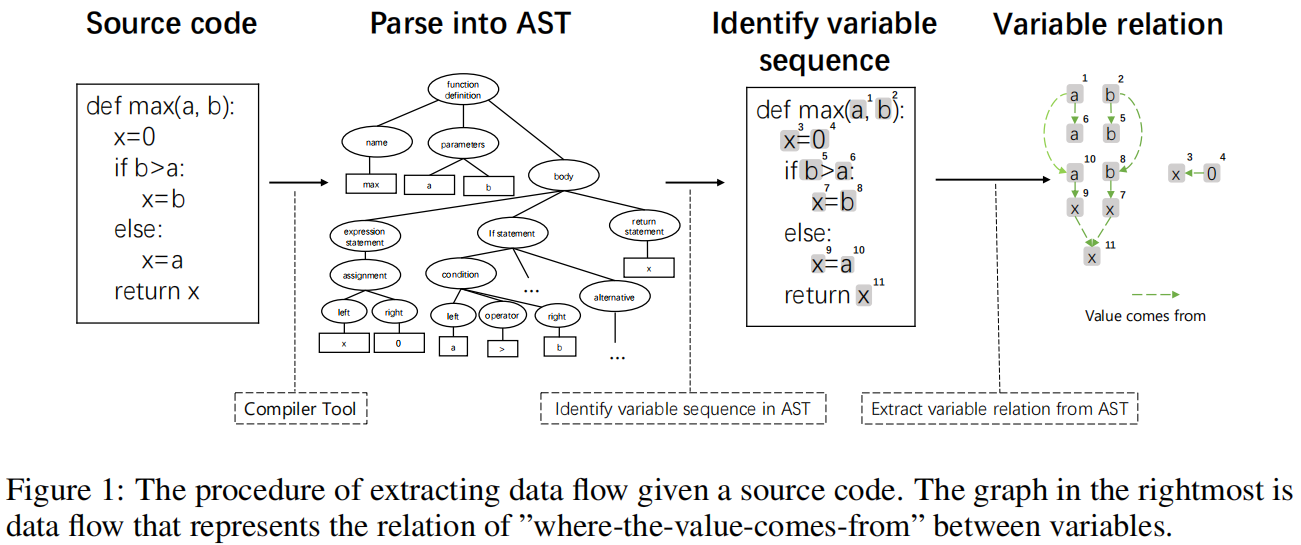
先生成AST,接下来,从生成的AST中提取出变量的序列,变量序列中的每一个元素都会成为数据流图中的一个结点。最后,基于变量序列和AST中提取出的变量之间的依赖关系,构建数据流图。所谓依赖关系指的是,对于"x=expr",x依赖于右侧表达式中的所有变量,以此类推。数据流图是有向图,指向“值流向”的方向,a指向b代表b依赖于a。
Model
Model Architecture
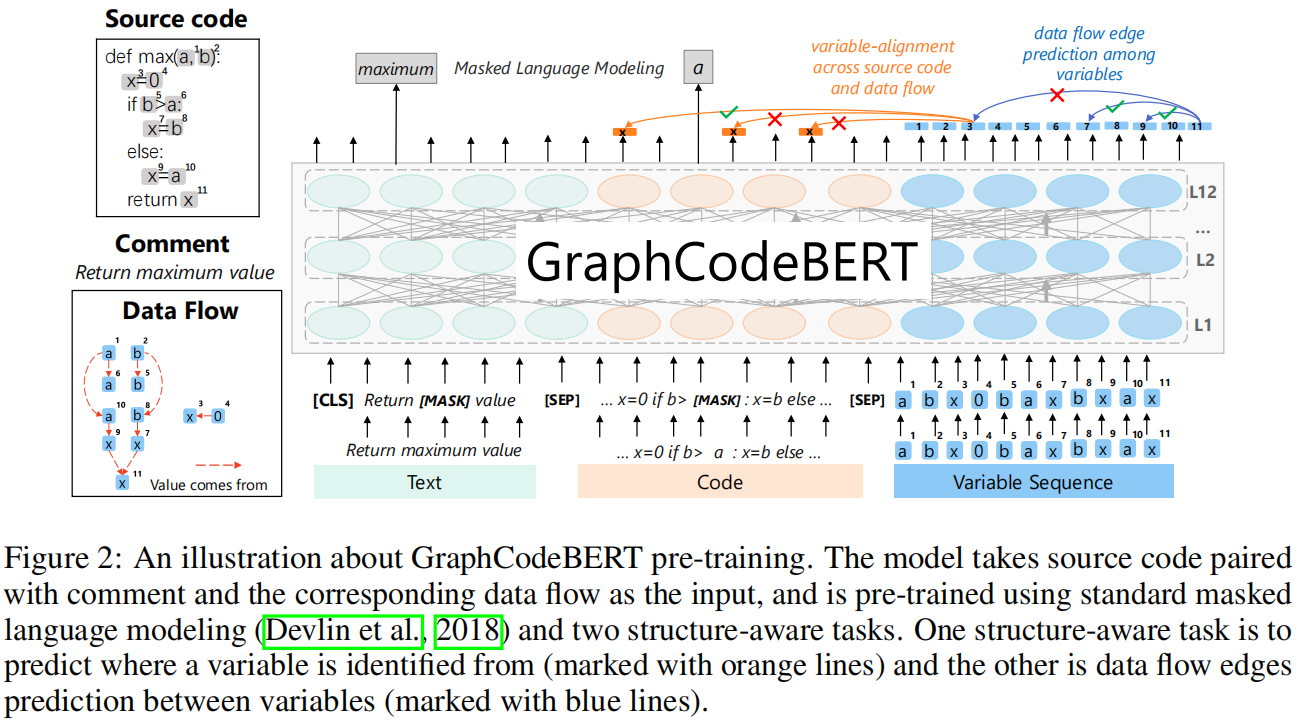
模型用BERT做backbone,输入包含:源码C、注释W、数据流图G包含了变量V和边E。最终的输入序列为:X={[CLS,W,[SEP],C,[SEP],V}
输入的向量还是由token embedding和position embedding求和构建得到的
GraphCodeBert模型使用了12个transformer encoder层来组成核心网络结构,采用12个attention head的多头注意力机制,包含Feed Forward层和Layer Normalization层等等,与我们熟知的transformer不同的是,本文中增加了一个Graph-Guided Masked Attention层,这个层与传统的Attention层的区别是在softmax计算权重之前需要增加一个参数M,功能是用来过滤无效的元素(在softmax之前加上负无穷)。模型的公式如下,设transfomer第n层的输出为 $H^n$,有
$$
H^n=transformer(H^{n-1})
$$
每一层transformer网络有
$$
G^n=LN(MultiAttn(H^{n-1})+H^{n-1})
$$
$$
H^n=LN(FFN(G^n)+G^n)
$$
每个多头注意力机制有
$$
Q_i=H^{n-1}W^Q_i,K_i=H^{n-1}W^K_i,V_i=H^{n-1}W^V_i
$$
$$
head_i=softmax(\frac{Q_iK_i^T}{\sqrt{d_k}}+M)V_i
$$
$$
\hat{G}^m=[head_1,…,head_u]W_n^O
$$
Graph-guided Masked Attention
主要作用是过滤不相关元素,就是一对结点的query和key必须要有一条边连起来才行,或者query使[CLS]、[SEP],否则就加上一个负无穷使softmax出来的值为0
Pre-Training Tasks
Masked Language Modeling
和BERT一样的,随机从代码和配对的注释中采样15%,其中80%换成[MASK],10%随机token,剩下10%不变
Edge Prediction
该预训练任务的目的是让模型学习“值从哪里来”的信息,对应了模型架构图中的蓝色部分。预训练时随机采样20%的结点,通过mask矩阵(如果采样结点中有2个结点之间有边相连,就设为负无穷)来实现边的mask,然后让模型预测被mask的边。
Node Alignment

该预训练任务的目的是让模型学习数据流图与源代码之间的对应关系,对应模型架构图中的橙色部分。与边预测不同的是,边预测任务学习的是变量序列V中两个结点之间的联系,而变量对齐任务学习的是源代码序列C和变量序列V之间的联系,也就是结点 $v_i$ 和单词 $c_j$ 之间的对应关系。
Experiment
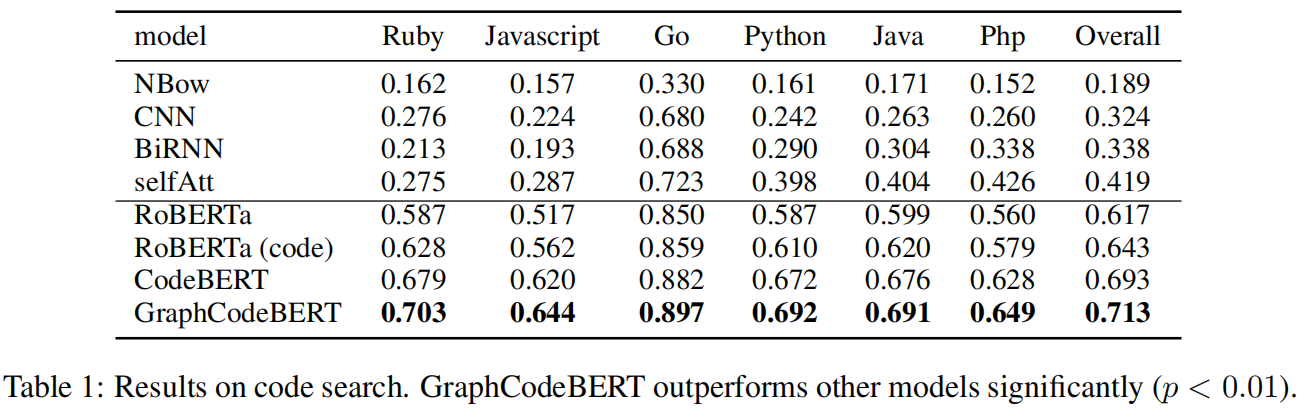
代码搜索任务的含义是给定一种自然语言输入,要求从一组候选代码中找到语义最相关的代码,使用的数据集是CodeSearchNet的数据集,使用代码文档的第一段作为query,以MRR(Mean Reciprocal Rank)作为评价指标,由上图可见,GraphCodeBert模型在每个语言的数据集上都表现优异。
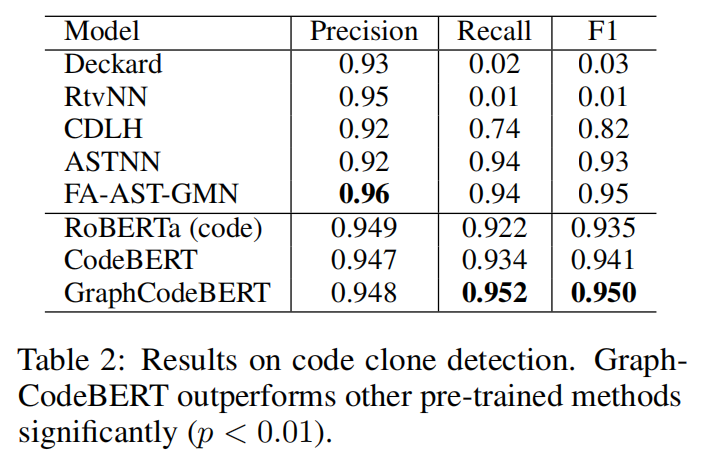
代码克隆检测任务的含义是给定两个代码片段,要求度量其相似性,输出相似度,使用的数据集是BigCloneBench数据集,实验结果如上图所示,可见GraphCodeBert模型的准确率和召回率都很高。
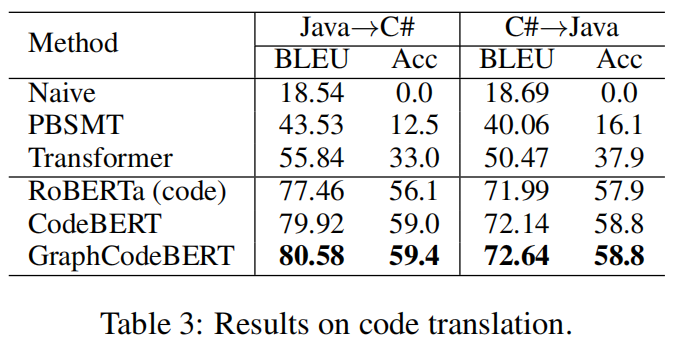
代码翻译任务的含义是将一种编程语言范围为另一种编程语言,其主要用途是将遗留软件从平台的一种编程语言迁移到另一种编程语言,以Lucene、POI等开源项目为数据集,这些项目都有Java和C#的实现,任务中模型输入Java(C#)代码,输出与之对应的C#(Java)代码。实验结果如上图所示,GraphCodeBert模型的翻译准确率和BLEU得分都高于之前的模型。
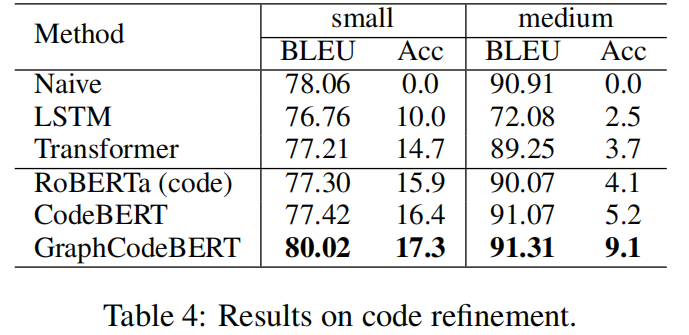
代码精炼任务也叫代码优化任务,旨在自动化的修复代码中的bug,使用Java数据集来实现,模型输入Java代码,输出修复bug之后的代码。实验结果如上图所示,GraphCodeBert模型优化的准确率和BLEU得分都高于之前的模型。
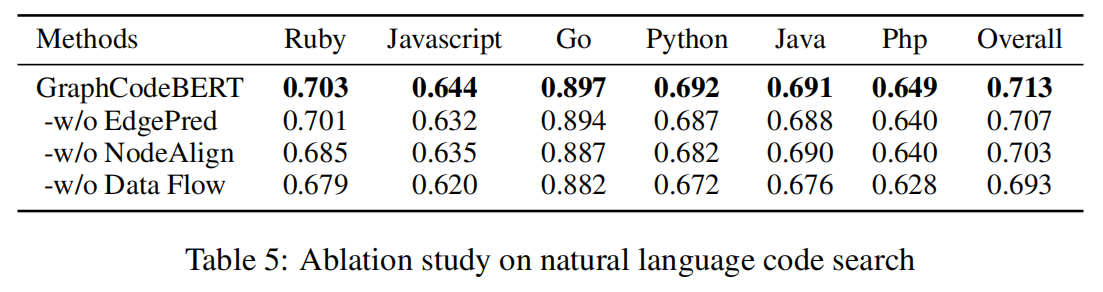
消融实验,两个预训练任务Edge Prediction和Node Alignment都有效的提升了模型效果,当然,数据流的引进对模型的提升效果是最大的

