论文地址:Scaling Distributed Machine Learning with the Parameter Server
参数服务器:分布式大规模机器学习
Abstract
数据和任务都分布在任务结点或工作结点上,有一个服务器结点来维护全局共享参数,表示为一个稠密或稀疏矩阵或向量
十亿级别的数据和参数在LR,LDA等算法上
Introduction
数据规模很大的情况下少数机器很难完成,但实现一个高性能的分布式算法很难,主要在于计算复杂度高,数据通讯量大
现实的大模型在10^9 到10^12个参数之间,这些复杂模型需要被全局共享,所有的计算结点访问这些参数,也带来了三个问题:
- 访问参数带来了大量的网络问题
- 机器学习算法是顺序的,需要大量全局同步
- 计算规模大的时候容灾就很重要了
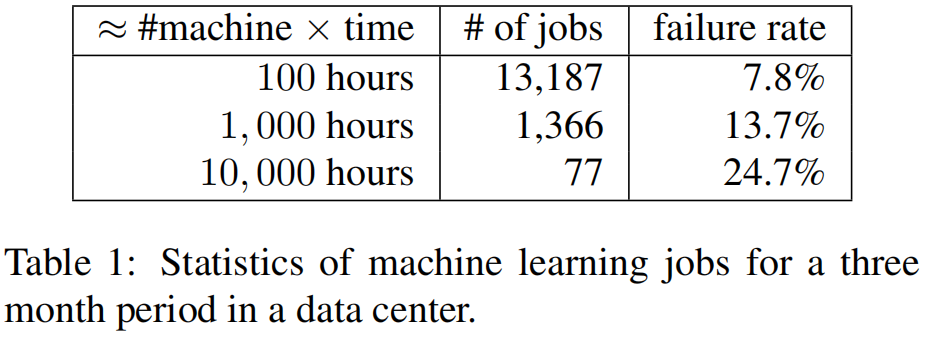
上表可以看到规模增长很大的时候失败率增长很快
Contribution
抽象共享模块去实现任务相关的代码就更简单,也就是能适配到各种机器学习算法
学术界往往就是把论文的机器学习算法盲目扩大了10倍、100倍这种,但在现实中其实不会这么盲目扩大。本文是根据真实的计算任务来进行系统级别的抽象,有以下五种关键特性:
- 有效通讯:异步通讯的方法,对机器学习算法做了大量压缩
- 灵活一致性模型:一致性指访问同一结点时,不同机器是访问到了完全一样的值,还是有一定的延后。弱一致性对系统更友好,但会牺牲部分机器学习算法的有效性
- 弹性可扩展性:新结点加进来不会让任务停掉
- 容灾:花多少时间恢复
- 便于使用:全局参数可以抽象成向量和矩阵,因为当时主要是C++写得,很难用
主要的新意度在于找到了合适的东西链接机器学习和系统
Engineering Challenge
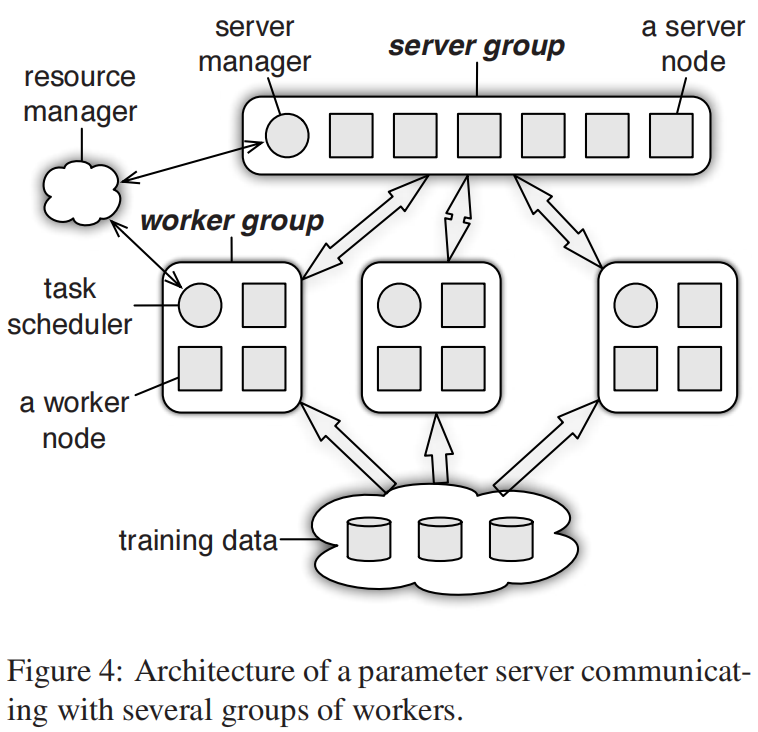
如果要处理分布式的问题就需要不断地去读和写全局的参数,参数服务器就是很好的统计和汇聚了这些计算结点和统计信息,每个参数的服务结点去维护全局共享参数的一部分,有很多机器一起维护。每个work node会取部分参数来进行计算,这就带来了以下问题
- 通讯:市面上的key-value的datastore对于机器学习提供的抽象不够,每次发一个key带上一个浮点运算这样开销太大了。而机器学习的算法主要是一些结构化的数学物体,向量、张量,所以每次要发一段的东西,比如一层网络,向量的一段。这样就可以做到批量更新
- 容灾:对每个服务器结点做一个实时复制
Architectrue
(Key, Value)Vectors
key工业界一般是哈希出来的特别长的向量,或int64,int128的整型,value是浮点数、向量或神经网络里面的一个w,这样的好处就是可以直接使用计算的一些库,而不是原始的C++的写法
Range Push and Pull
支持两个通信方法,来源于git
允许把一段区间的key和value发送出去,避免了零散不断的信息通信
User-Defined Functions on the Server
允许在服务器端有用户自定义的函数,更加灵活
Asynchronous Tasks and Dependency
任务叫做远端任务执行(RPC)
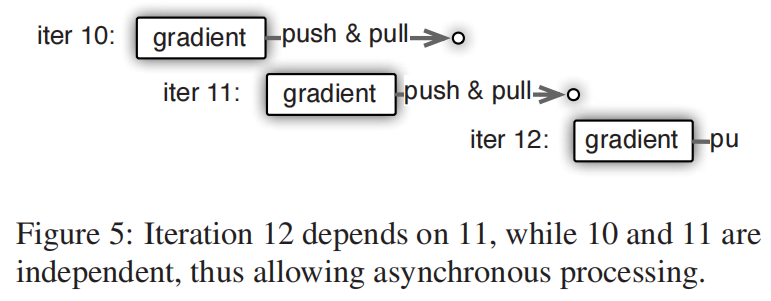
为了优化性能,这里的所有任务是可以异步执行的,比如调度器有4个调度节点,在每一轮迭代可以向这4个结点逐一发送,不用等work0计算完,而是继续在work1后面接着执行
当然也有设置服务器任务完成后才接着跑下一个任务的这种依赖
Flexible Consistency
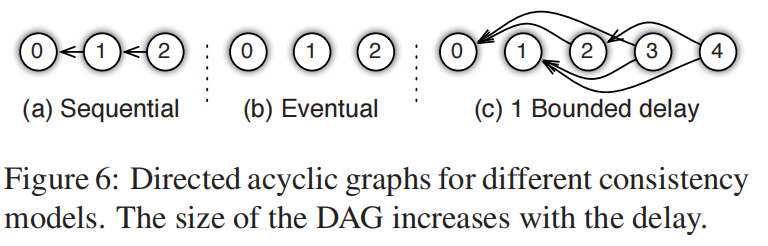
上图是一些常用的一致性机器学习模型
a)必须等上一个任务完了再开始下一个
b)任务一直往下算,网速赶得上就顺便更新了,但是收敛可能不是最快的
c)允许有一定延迟,不允许延迟太多。这个延迟可以当作超参数来调
User-defined Filters
有些数据不一定总是必要发送出去的,通过过滤器来少发一些东西,例如假设一个权重W在上一轮没有改变很多的情况下就不发了
Implementation
Vector Clock
假设有很多计算结点,要访问数据W,但是他们时间不一样,在服务端需要维护哪一个结点现在用的W结点是哪个时刻的,这件事的计算代价很大,等价于把权重要复制到计算结点个数次
因为API的设计每次不是发一个单独的Key,而是一个区间段的key,所以可以放松到在每一个段来计算哪个结点在什么地方,比如深度学习模型有几百亿参数,但是每一次都只是对每一层的那些权重发送出去,所以在做vector clock时只用计算每一个层每一个结点用的是哪一个时间算好的值,这就减少了存储量
Message
每次通讯的是一个区间,里面就要有key和value,但实际上服务端关心的是value,最好不发key或者少发key。所以在数据没有变化,权重没有加新东西的情况下发一次key,后面就不发了
具体就是把这些key重新哈希一遍,把哈希值发过去,server端看到哈希值是一样得情况下就省掉了key的开销,可以通过一个filter实现
Consistent Hash
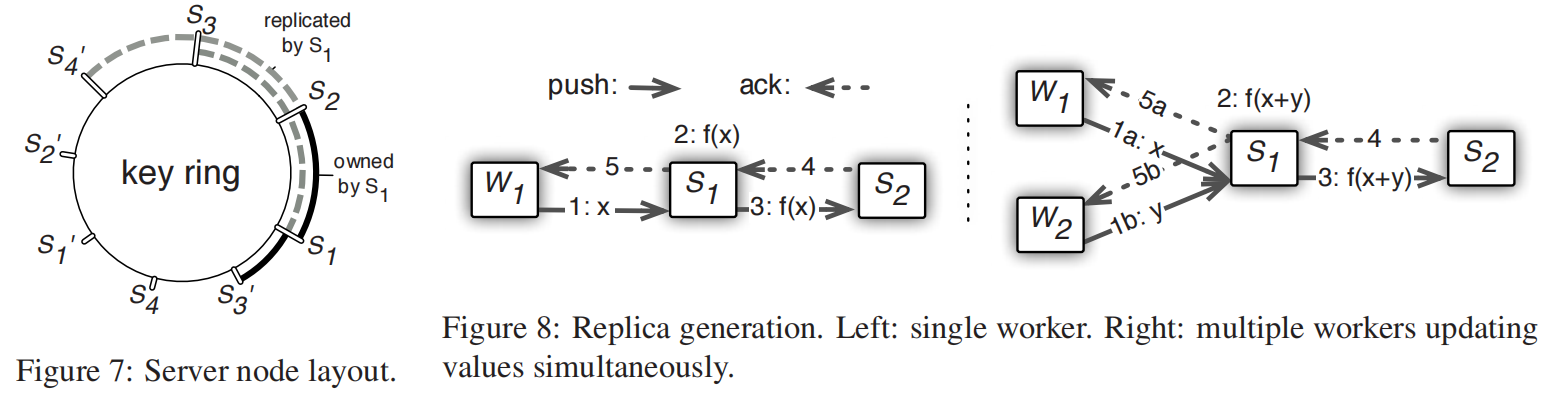
一致性哈希环表示了server端怎么存权重的,分成很多段,每一段有一个服务器结点来维护,同时也会存下两段来备份
加结点就把区间分裂成两个,原始的结点就把其中一段发给新结点,备份同步进行
Worker Management
调度器一直查看(ping)worker的情况,如果任务没完成或挂了,就把任务发给别的worker或者向系统申请新的worker等等来实现容灾
Evaluation
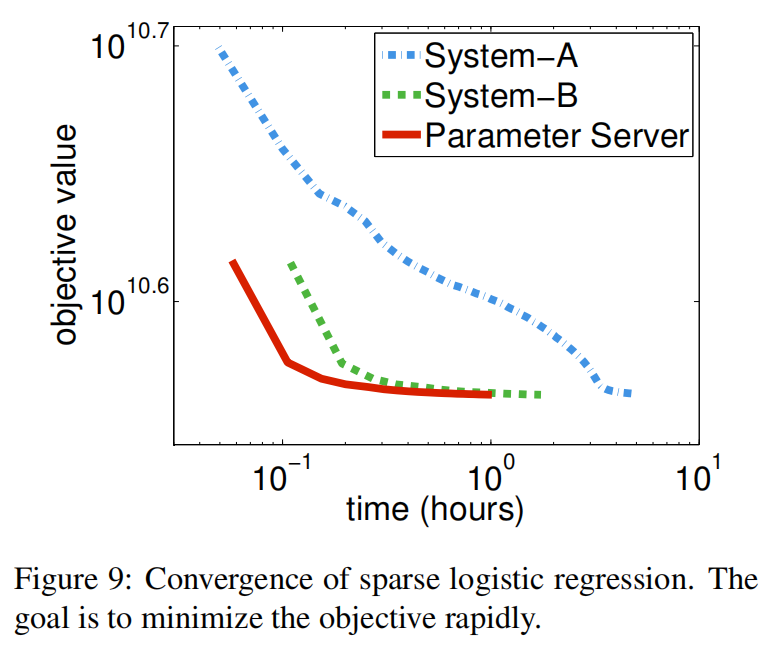
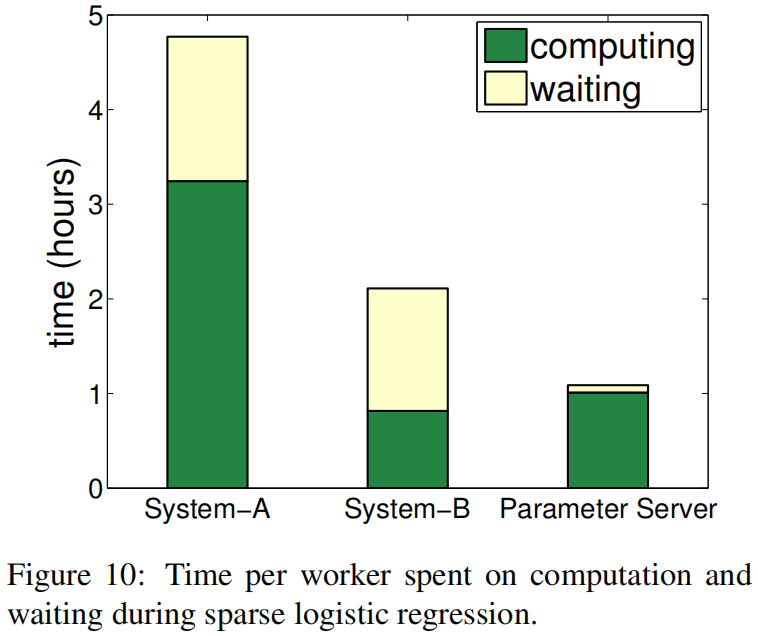
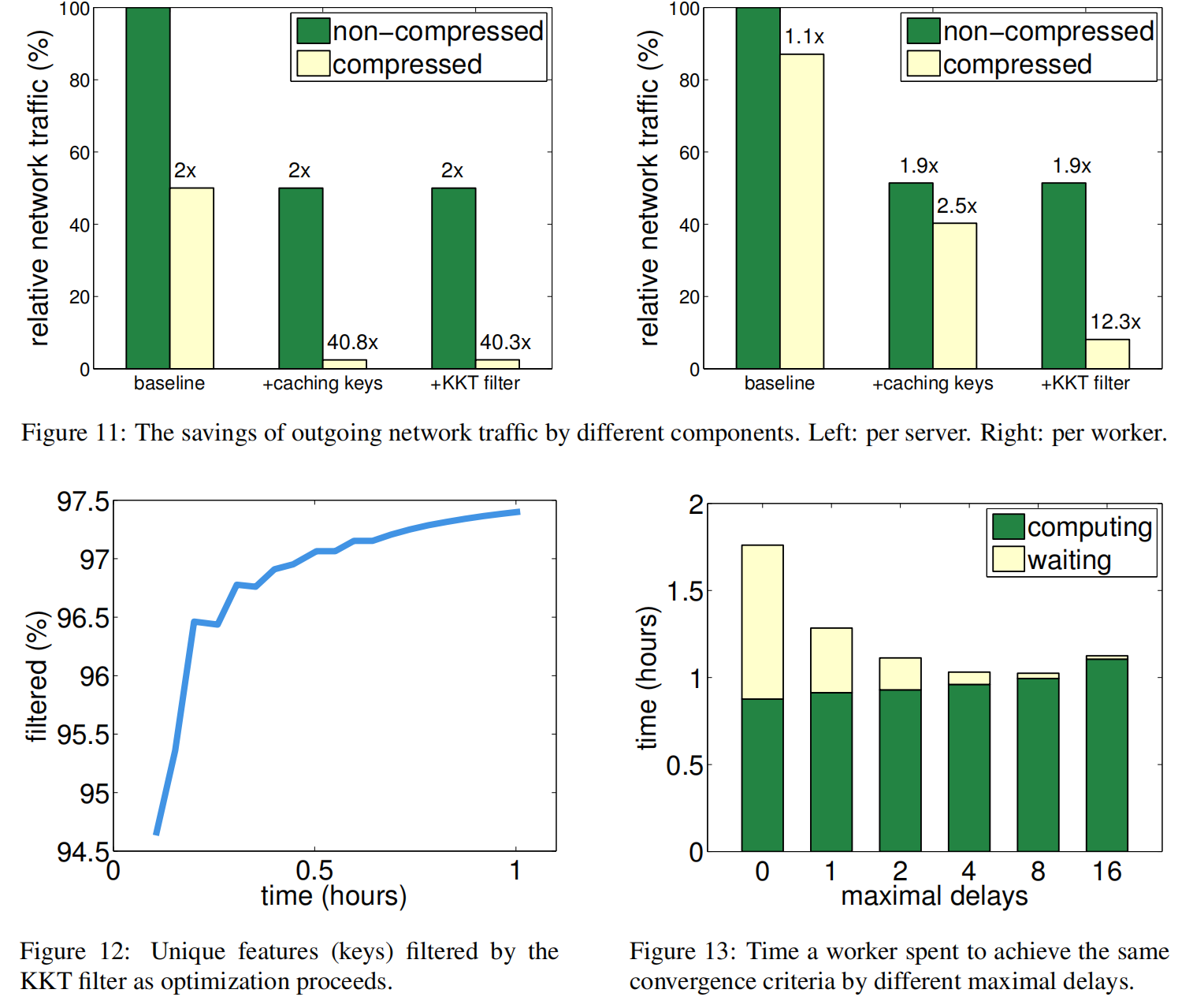
做了异步减少了wait时间,但增加了收敛时间