SiT:多视角结构线索
Abstract
先前的工作多是使用SBT或非顺序模型比如Tree-LSTM、GNN来学习代码的结构化语义。但让人惊讶的是将SBT融入一些先进一些的编码器如Transformer而不是LSTM,但没有得到任何提升,这使得GNN成了仅有的有效建模代码的方法
为了缓解这种奇怪的现象,作者提出了结构感应的Transformer,根据一种新提出的自监督结构感应机制,通过多视角的结构线索编码序列代码的输入
Introduction
早期,代码摘要是信息检索的一个衍生问题,主要是通过匹配有注释的最相似代码块,这种方法泛化性差效果不满意
最近研究者将代码摘要问题视作自然语言生成的一项任务,常使用基于RNN的端到端模型,但是这种模型对长序列依赖进行建模时有瓶颈,特别是代码段一般都有几百个token
所以最近也有学者提出了基于transformer的方法来获取长序列信息,比基于RNN的方法好很多
另一方面,结构化线索能够大大增强代码摘要等编程语言相关的任务,比如AST可以更好的理解代码片段,这之前的相关工作可以分为两类:
- 使用非序列编码器直接建模结构化输入:TBCNN、Tree-LSTM、Tree-Transformer、GNN
- 预处理结构化输入使其应用到序列模型:SBT
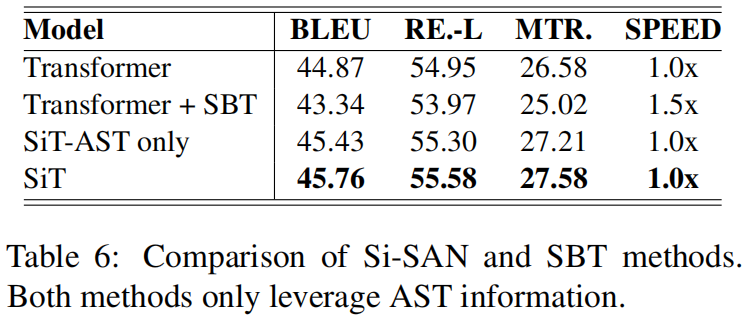
RNN、LSTM的方法对抓取长距离依赖有局限性,而GNN模型对局部信息又太敏感,SBT只在LSTM上起作用,对Transformer没用,作者将这种现象归为由于SBT和编码器形式导致的线性和非线性不一致性,也就是特征-模型匹配度

上表可以看出作者提出的SiT模型能避免上述缺陷
Stucture-based Code Summarization
Structure Representation of Code
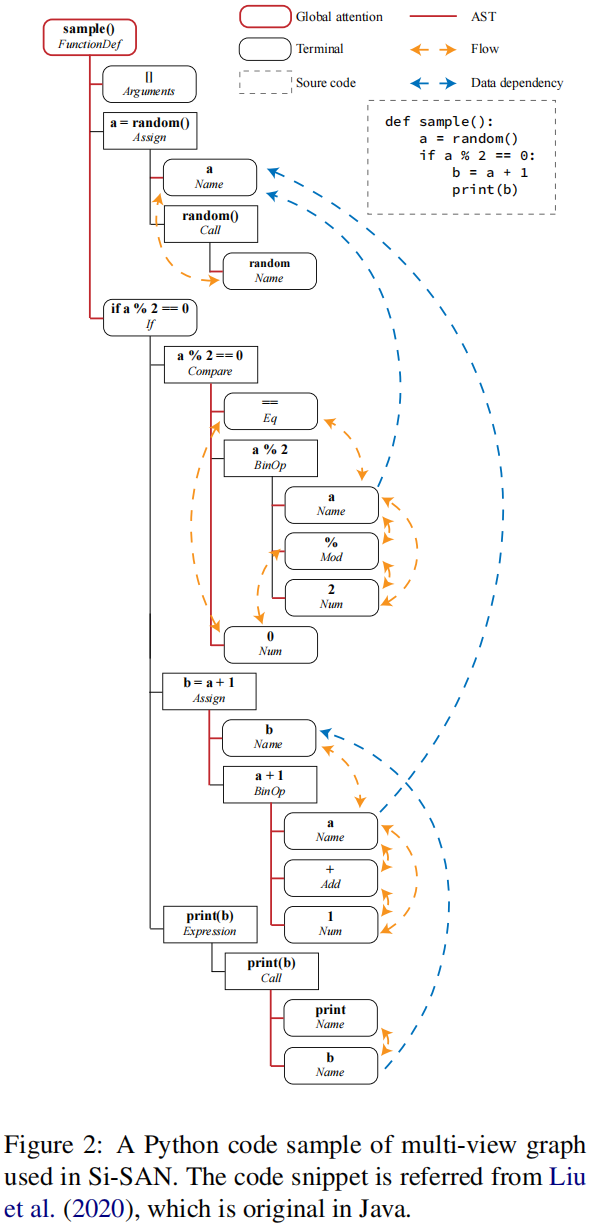
上图是一个标准的AST以及作者采用的三种视角
在模型实现中使用邻接矩阵A来表示AST,而不是基于结构遍历或是顺序形式表示树,然后通过key-query的点乘出一个 $l\times l$ 的注意力矩阵,再position-wise乘起来
作者还扩展了AST到一种多视角网络(MVN or multi-view graph),每一个视角对应一种结构关系,同时所有的视角共享同一组结点,本文构建了三视角图,基于抽象语法,控制流和数据依赖,从而获得了三个邻接矩阵,还在根节点添加了全局注意力
Structure-induced Transformer
Vanilla Self-Attention
自注意力机制
$$
SAN(X)=Softmax(\frac{QK^T}{\sqrt{d_k}})V
$$
如果把每个子单词视作顶点n,key-value的内积视作边e,公式改写为
$$
SAN(X)=E\cdot N
$$
Structure-induced Self-Attention
为了展示结构信息的必要性,提出了结构感应的自主意网络
$$
SiSAN(X)=Softmax(\frac{A_{mv}\cdot QK^T}{\sqrt{d_k}})V
$$
其中 $A_{mv}$ 是代码的多视角表示,但Si-SAN并不会改变输入代码,而是通过改变其注意模式,将代码结构适当地合并到SAN中,可以更准确地计算结构信息
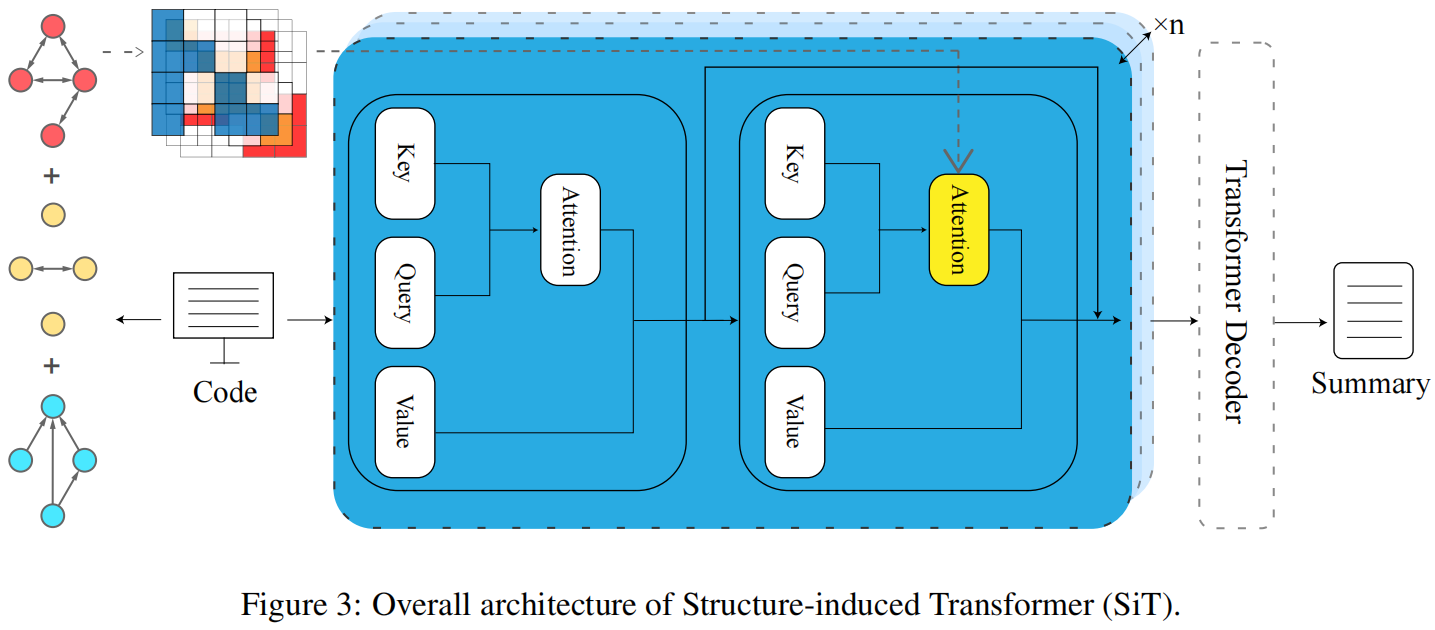
Structure-induced Module
为了提高鲁棒性和避免过拟合,提出了结构感应模块,是SAN和Si-SAN堆叠起来
先通过SAN层获得隐向量表示
$$
H=Concat(SAN_1(X),\cdots,SAN_h(X))
$$
其中h是多头注意力的头数目
然后通过Si-SAN层
$$
H’=Concat(SiSAN_1(H),\cdots,SiSAN_h(H))
$$
最终融合特征
$$
\tilde{H}=Aggr(H,H’)
$$
本文采用的聚合方法是同位求和
SiT-based Code Summarization
把输入的代码变形为邻接矩阵后加权求和
$$
A_{mv}=\alpha A_{ast}+\beta A_{fl}+\gamma A_{dp}
$$
把代码序列和对应的邻接矩阵丢入编码器,即3层Si-SAN,解码器用的就是原始的transformer解码器
Experiment
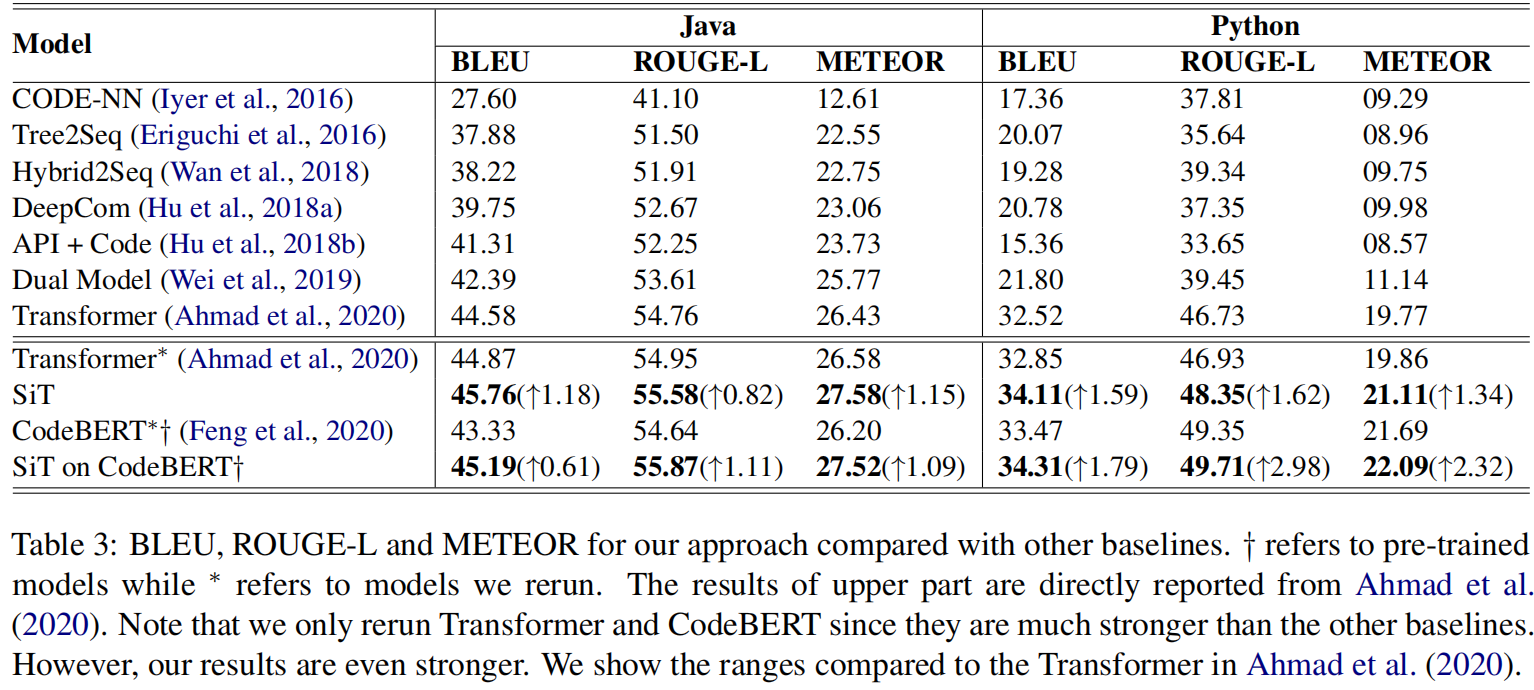
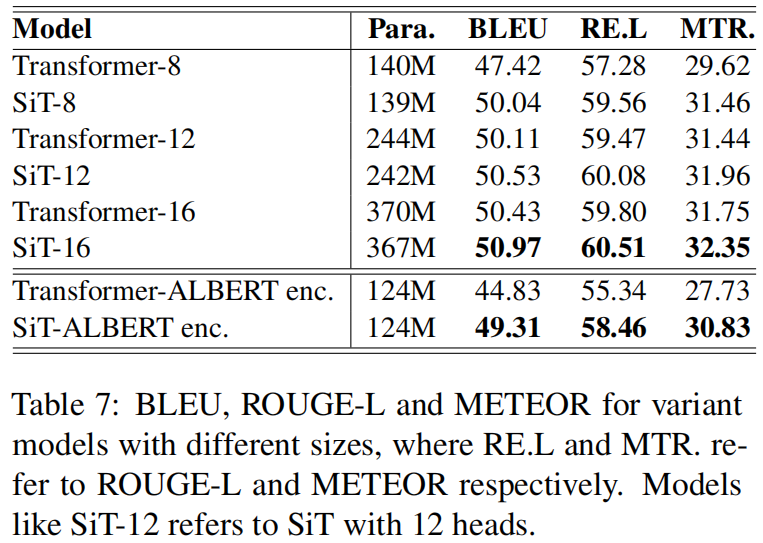
相较于传统的transformer有提升