论文地址:A Closer Look at Spatiotemporal Convolutions for Action Recognition
R2+1D:拆分3D网络有助于训练
Abstract
作者发现如果就用2D的网络在视频上去一帧帧抽特征,在视频动作领域结果也不错,没有比3D弱多少,作者就想2D既然效果不错,如果用一下2D或部分使用2D卷积是否也是不错的(2D比3D便宜很多)
这篇文章在测试不同结构,是一篇实验性的文章,先2D再3D还是把3D拆分成1D加2D的结构,作者发现把3D拆分成空间上的2D和时间上的1D能得到更好的效果,而且训练更简单
在Sports-1M,k-400,UCF101,HMDB51上都取得了不错结果
Method
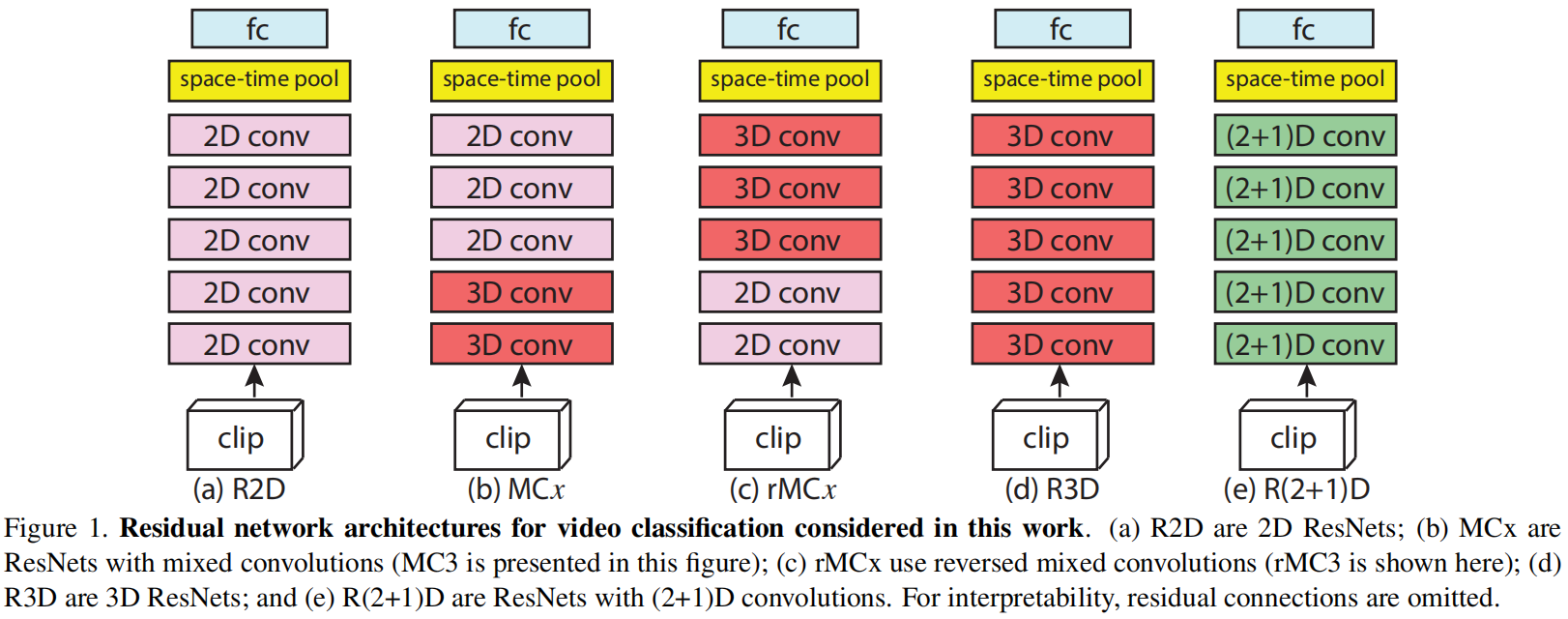
组合不同消融实验看看哪种最好
a)R2D
- 纯2D网络,视频里面每一帧,一帧帧的过去抽特征做训练
b)MCx
- 头重脚轻
- 先有一个视频clip进来在3D网络底层学一学时空特征,上层换2D降一下复杂度
c)rMCx
- 头轻脚重
- 把一个视频clip拆分成每一帧,2Dconv出特征后用3D融合
d)R3D
- 全部都是3D网络
e)R(2+1)D
- 把3D卷积拆分成两个卷积
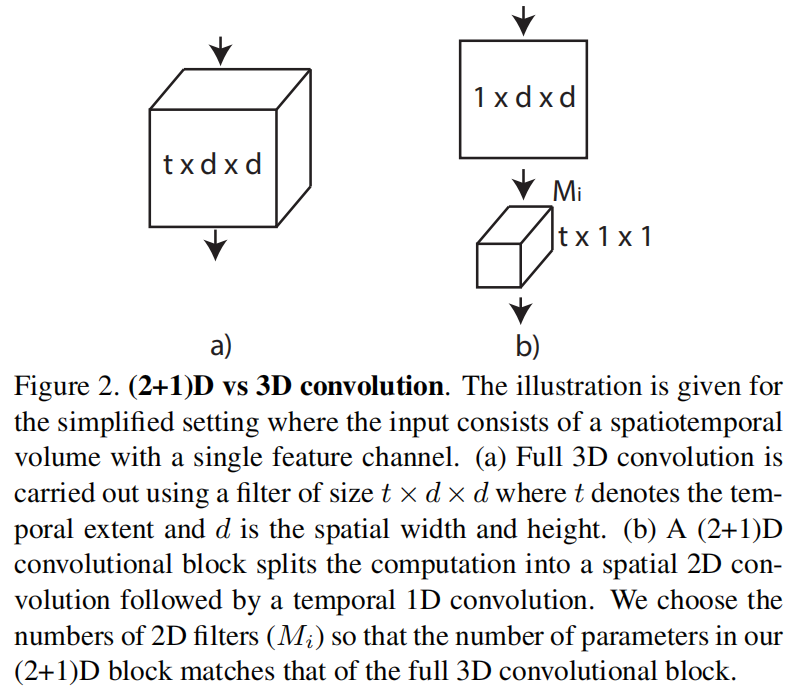
先做一次空间上的2D卷积,然后投射保持参数不变,再做时间上的1D卷积
好处:
-
这样有两次非线性变换,加强了模型的非线性能力
图3
-
直接学3D是不太好学的,拆分之后更好优化
Experiment
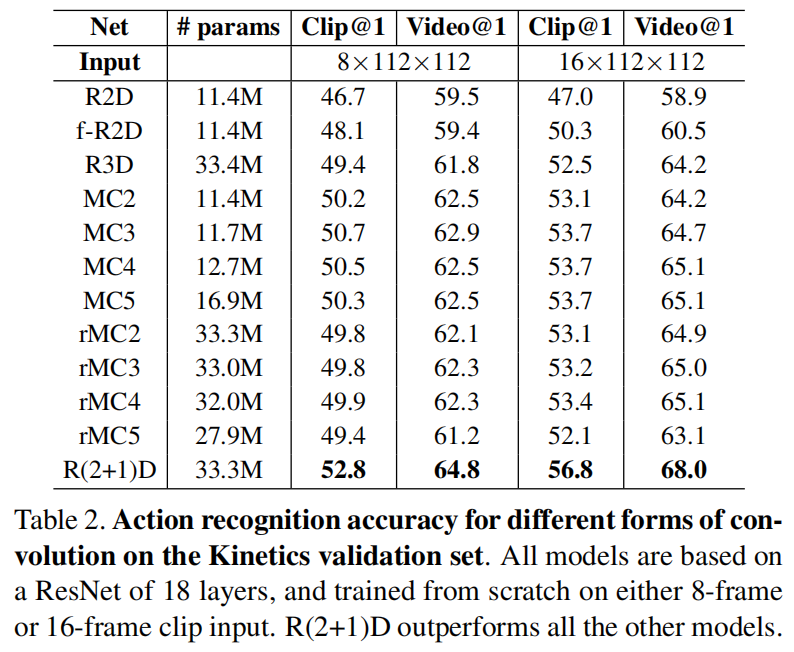
消融实验,纯用2D更便宜,用了3D就变贵,但是混和效果更好
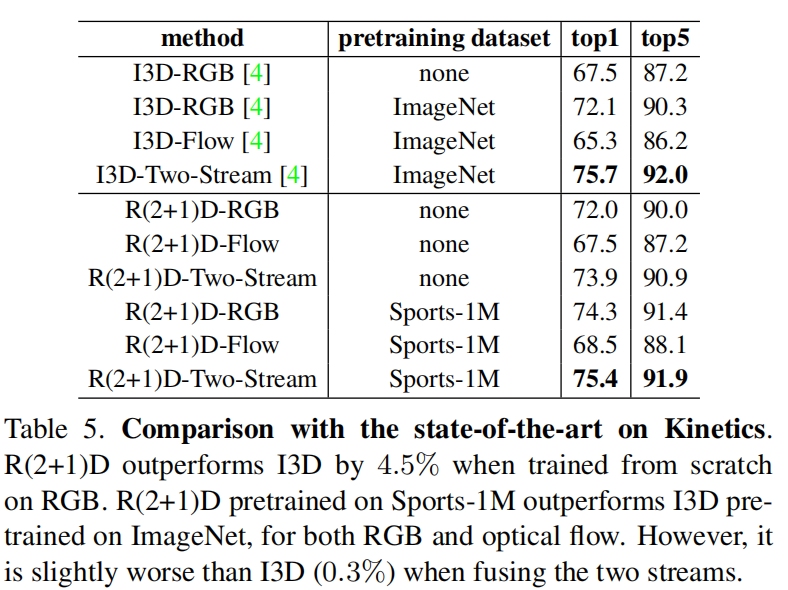
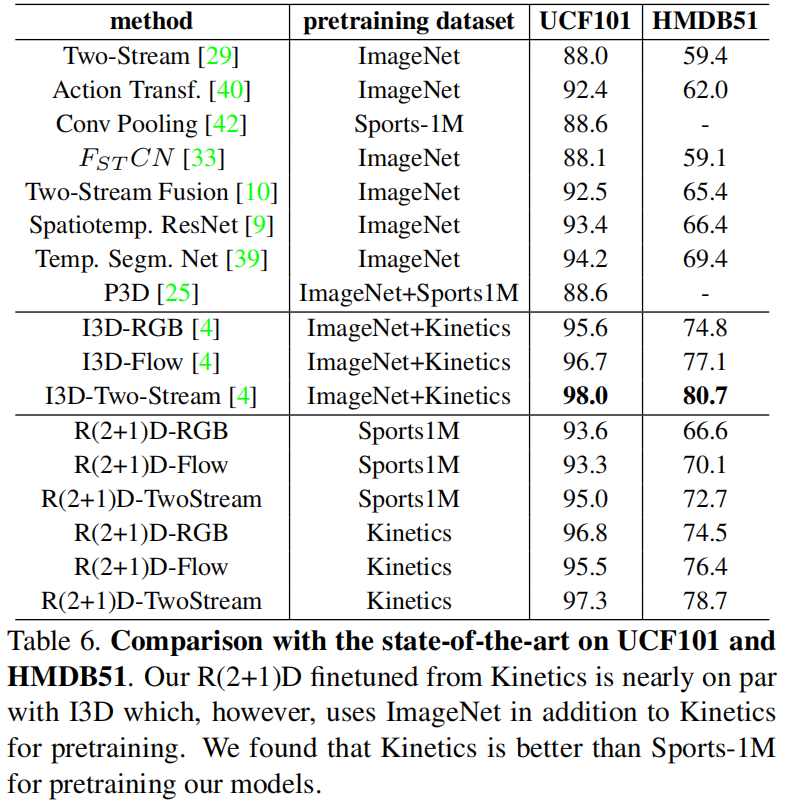
k-400上实验,发现在RGB和Flow上单独都比I3D要好,但是结合起来反而不如了
在UCF101和HMDB51上一样的结果,甚至flow上也比I3D要低了,这就很难解释了,所以作者另辟蹊径解释说I3D用的是imageNet+kinetics,而本文只用了kinetics,但事实上I3D论文里也做了了单独用kinetics预训练的结果,还是更好
但R(2+1)D最好的地方就在于好优化,而且输入是112x112,对GPU也很友好

