论文地址:Is Space-Time Attention All You Need for Video Understanding
Timesformer:详细实验迁移vit到视频理解
Abstract
把vision transformer迁移到视频理解领域来
Method
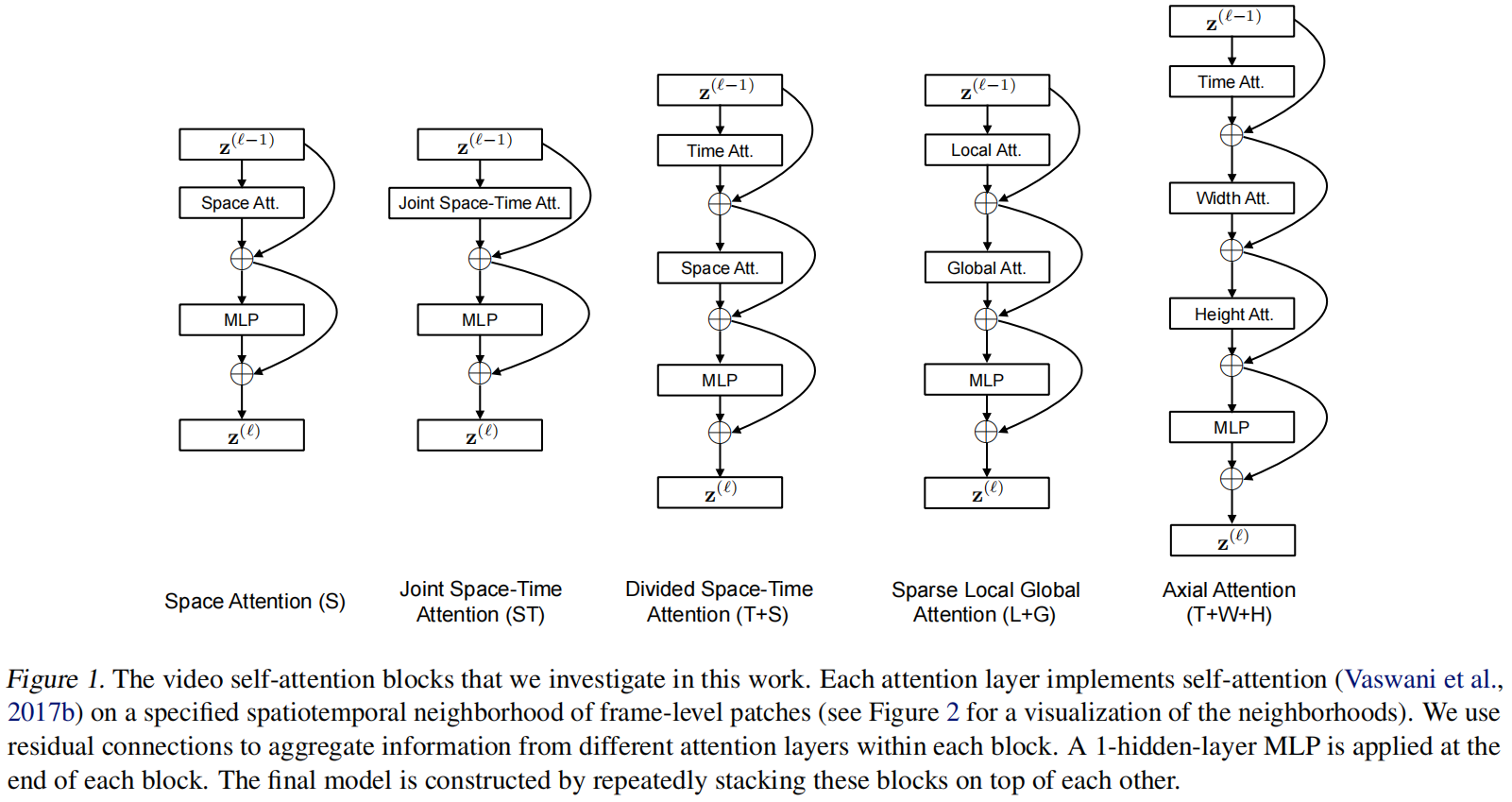
作者尝试了以上五种结构
-
S
- 只在空间特征图做自注意力,就是图像里vision transformer用的自注意力
-
ST
- 比较暴力做法,视频三个维度一起做自注意力,但太大了,GPU塞不下
-
T+S
- 本文的主要方法,拆分了3D,先做时间自注意力再做空间
-
L+G
- 先局部小窗口算,再全局,降低了复杂度
-
T+W+H
- 只沿着特定的轴去做自注意力,把三维变成了1+1+1维,复杂度也降低了

这图画的非常好,蓝色的patch表示基准,然后和其他的patch做注意力,绿色表示时间注意力,黄色是局部和轴,紫色是全局和轴
Experiment
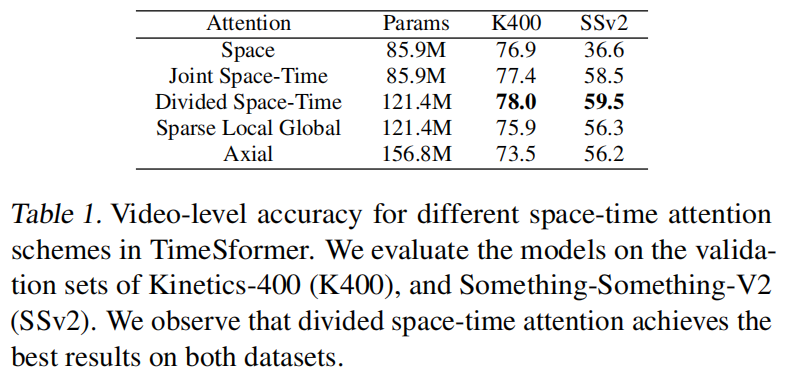
光用2D的在k400效果比较好是因为这个数据集本身偏向静态的,换在ssv2效果就不好了,还是要考虑时间维度的
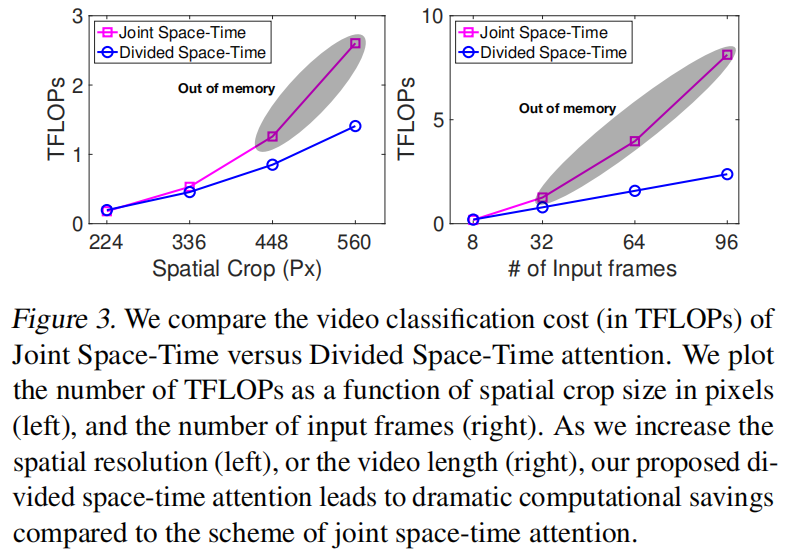
joint的方法虽然好,但是随着视频帧变多开销非常大,灰色是爆显存了,没法训练了
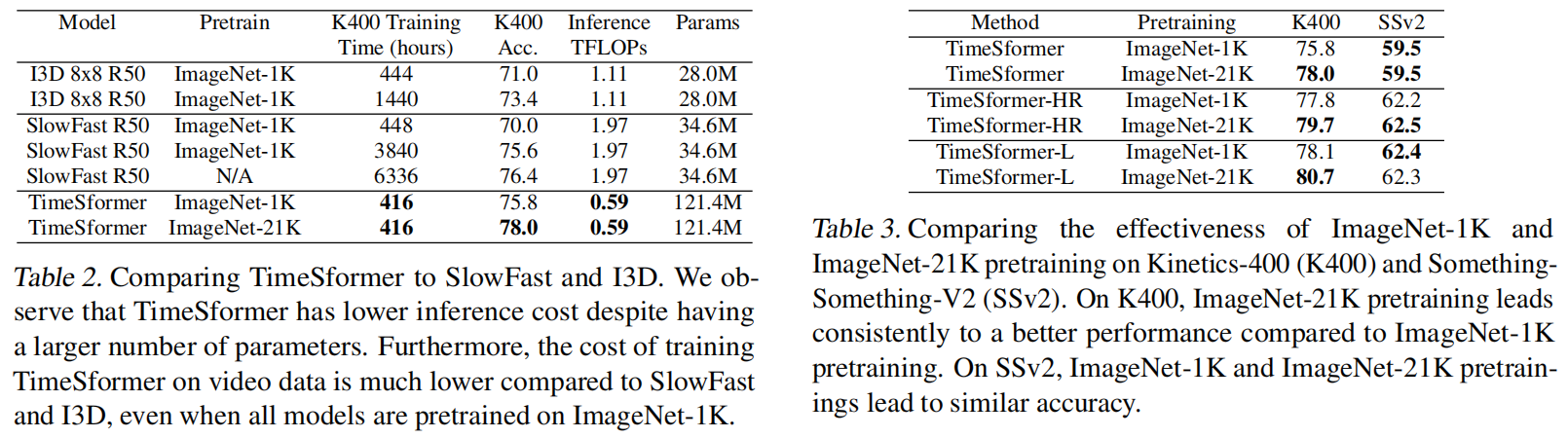
训练时间少,推理速度快,但效果实际上不算是最好的,slowfast如果换res101在k400可以达到80以上
把Timesformer变大也达到了SOTA
Conclusion
四个好处
- 想法简单
- 效果在几个动作识别都达到了SOTA
- 训练推理开销小
- 可以处理超过1分钟的视频

