论文地址:Learning Spatiotemporal Features with 3D Convolutional Networks
抽取光流的方法不适合实时处理,因为每换一个数据集,就要重新处理光流,而且抽取光流时间还很长,此外在做推理的时候也需要抽取光流,这就导致了实时性非常差。如果有方法可以不单独对时间信息进行建模,直接从数据中学习到时序信息那自然是更好的了
C3D:3D网络抽特征
Abstract
用了一个更深的3D卷积网络在一个更大的数据集(sports 1M)上,设计比较简单直观
Model

相当于把VGG网络里面每一个block减少了一层conv,再把所有的conv kernel从3x3变成3x3x3
作者每次都从最后4096里面抽取特征,拿出来训练一个SVM分类器去做分类任务,效果快又好
Experiment
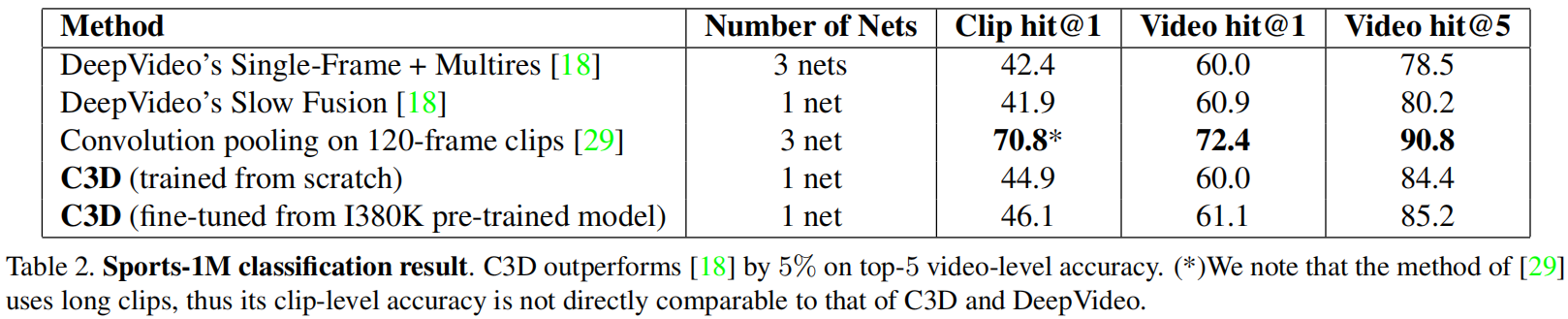
从头到尾都是在做时空学习的操作,所以作者认为3D网络比2D网络更适合视频理解的任务
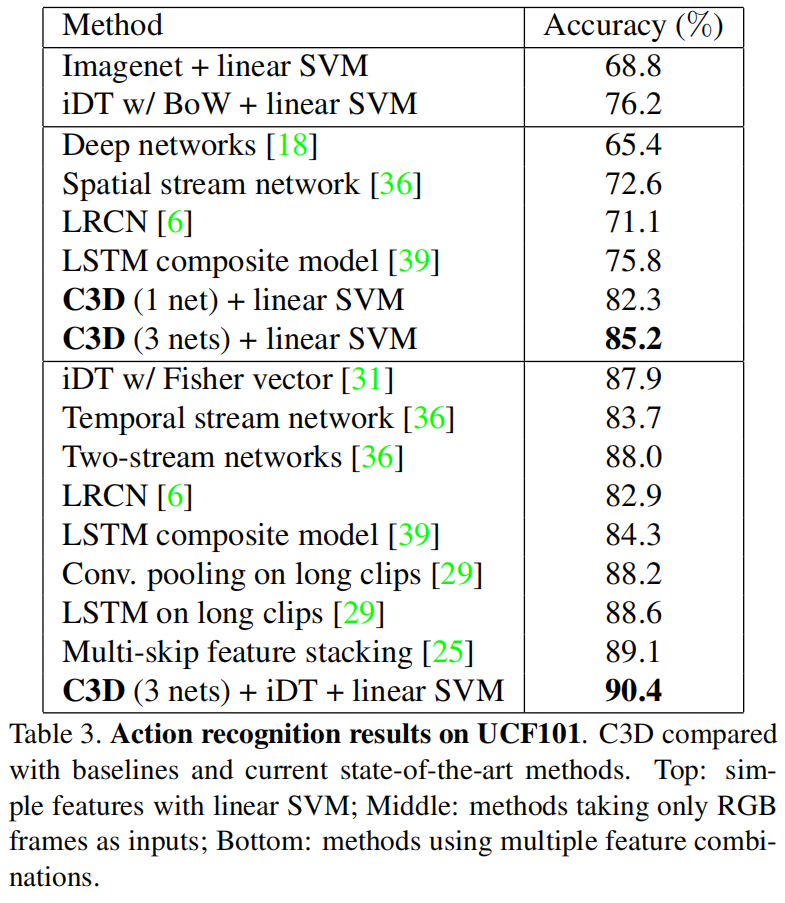
UCF101数据集上表现和其他工作比一般,ensemble起来都还是并不突出。但这篇工作训练时间很长,在facebook都得训练一个月,所以这种工作fine-tune是不友好的,最好还是抽特征,所以作者提供了python还有matlab接口,给一个视频然后返回一个4096的特征去做其他下游任务

