Non-local:自注意力算子
Abstract
无论是卷积操作还是递归操作都是在一个很局部的区域里进行处理的,作者就指出如果我们不是在局部或者说更多的上下文进行操作肯定对各种任务都有帮助,所以作者提出了一个non-local的算子,是一个即插即用的block,用来建模长距离信息
Method
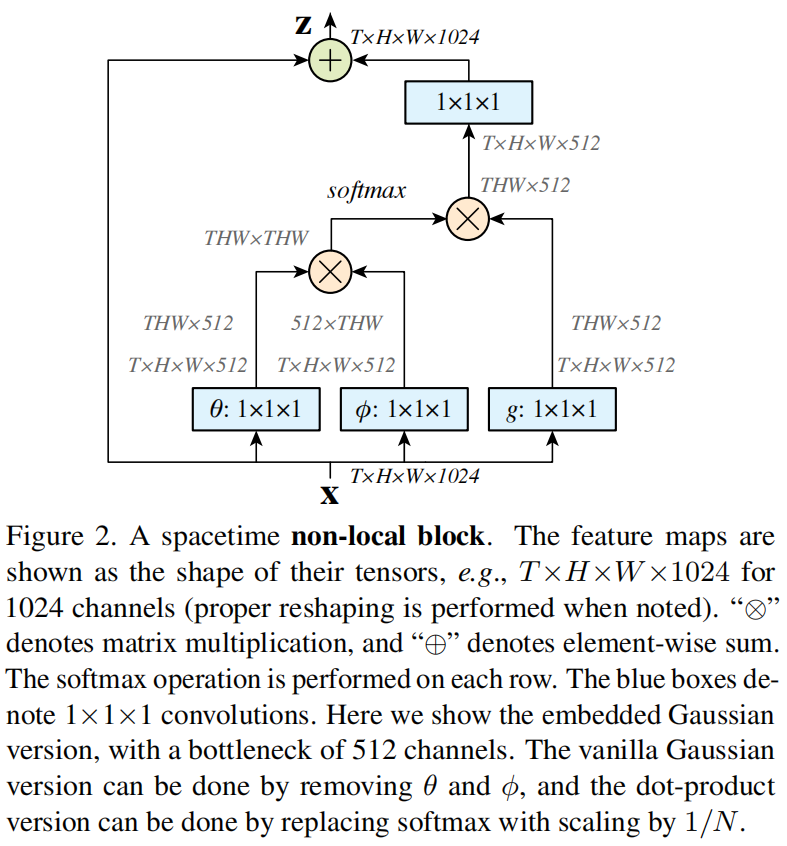
适配视频理解的标准自注意力模块,标准的key,query,value乘积
Experiment
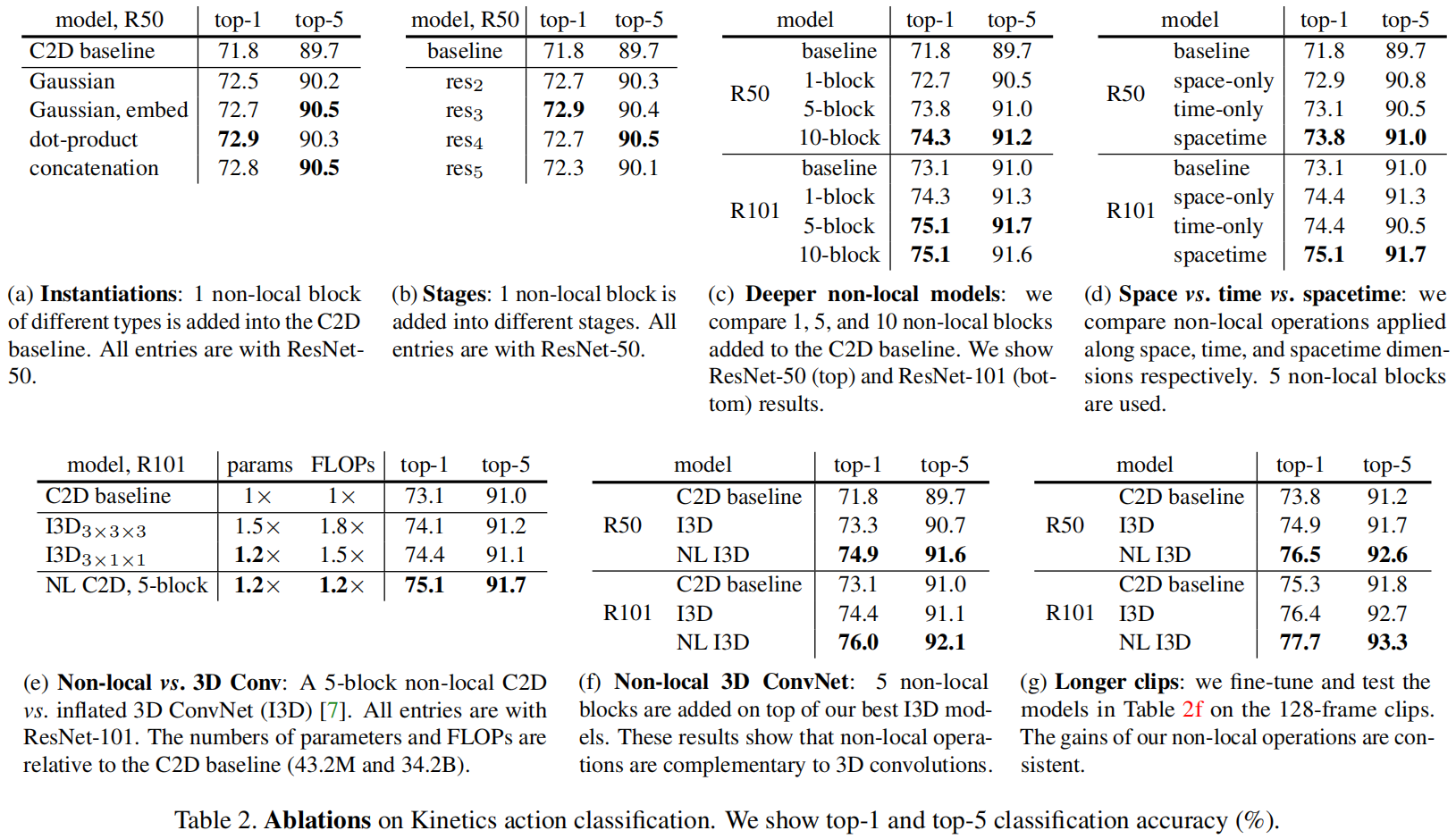
(a)使用dot-product做自注意力是最好的
(b)先测试了一下加一个non-local block,发现加在res2,3,4效果都是不错的,加在res5效果比较差可能是因为到后面特征图比较小了,这时候做自注意力也没什么东西可以学了,而且提前做这种操作又比较贵,所以放在3,4比较好
(c)测试加几个block好,发现还是越多越好
(d)时间和空间做自注意力一样重要,都做是很好的
(g)既然non-local本身是为了更多的上下文信息,于是发现把时间序列输入变得更长也会持续提升性能
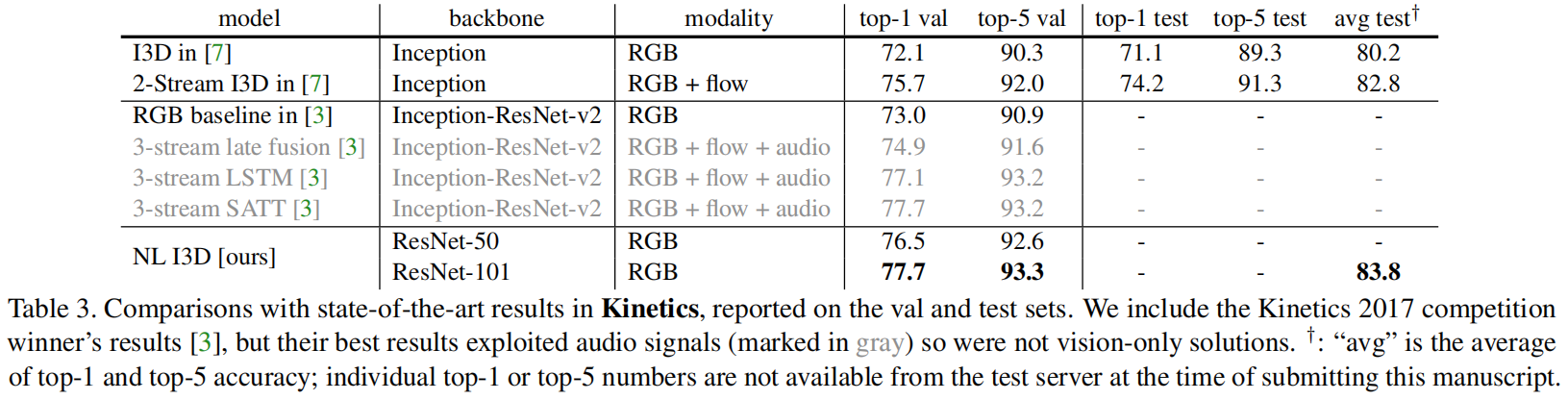
把网络换成res,non-local是真的有效

