Pathways:解决在tpu训练多个pod问题
Abstract
在云上面有很多计算,把他们映射到下面的计算资源上,这种操作是针对加速器用的。Pathways这个系统是用来去探索新的机器学习研究的方法和新系统,同时达到很好的性能。
Introduction
近几年机器学习的模型都是跟系统和硬件一起演进的,具体来说就是软件系统可能太依赖于当前任务进行优化,但不能很好的适用未来的需求。本文讲的是Pathways用的分布式机器学习,作者相信这个系统能被未来的机器学习所需要。
现在的机器学习任务都是用单程序多数据SPMD(来自于MPI),在一些简单的目前分布式计算上或许没什么问题,但是在未来会引入新的问题,比如现在的模型都非常大,可能在一个加速器上可能就放不下了,这时候坐纯粹的并行就不行了,需要用一个pipline的操作对并行任务进行切割。还有就是现在有些模型在探索稀疏性,也就是里面不全是全连接而是稀疏连接,导致优化又不一样了。
最近机器学习的硬件变得越来越异构,指的是里面有一些“岛”,“岛”有一些类似的加速器,通过一些高带宽连接在一起。可能在另外的地方还有一个“岛”,也是类似的连接了,但是“岛”与“岛”之间连接可能就不那么紧密了。这个“岛”可能是很多加速器耦合在一起,也可以就理解成一个塞了很多GPU的机器。但这个问题可能是Google的TPU特有的,其他的架构可能没这个问题。因为这种异构性存在大家可能去追求多程序多数据MPMD的执行,每台机器拿到的任务可能不一样,优化不一样。
这些transformer的模型比如BERT,GPT啥的都叫做foundation模型,做得都很大,而且推理和训练可能同时进行,一个模型被多个服务同时使用
Design Motivation
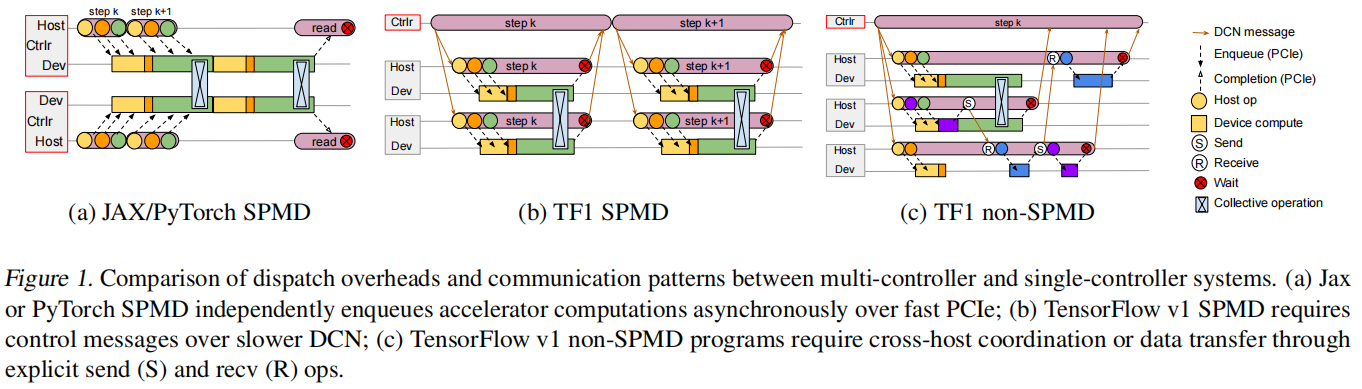
a)JAX/PyTorch SPMD
- 假设跑两台机器的分布式情况下,上下两条线是两台机器的cpu进程,两台机器用的同样代码,要跑gpu运算时,cpu就把指令通过pcie发到gpu上面做计算,如果要做通讯的时候,机器就同时停在一个地方,对这个t做一次allreduce,回去之后继续算下一个,差不多的时候把损失打印出来
b)TF1 SPMD
- 两台机器去跑分布式的情况下,并不需要登录到这两台机器去把程序启动起来,而是在一个controler的机器把程序编译一次,然后把任务派送到各个机器上去完成,在做优化的时候会方便一些
c)TF1 non-SPMD
- tf1来跑每个机器可能执行不一样代码的情况,这种有controler的方法使得它能知道全局的信息,能够做很复杂的逻辑控制等等。但坏处也是有的,因为有controler这种调度器来帮忙优化,所以可能会做很多的图编译优化之类的操作,如果报错了就会出现很长的错误信息,很难溯源,不像(a)那种逐条执行的,能够直接定位到错误代码甚至单机调试。而且有这种controler来先构建了一个图编译,导致debug不能一条条来,得先把图建立起来,非常麻烦
- 但作者表示这种有中央控制器的情况还是最好的,也就是有dataflow的方法,这种设计方法是没错的,但是受限于当时的时代考虑的是比较小的图,现在结点可能上千,还有异构,所以要更新设计来服务现在的场景
整个Pathways就是为了解决怎么把数据流的模式做到异构的上千个加速器,非常大的transformer上面
Pathways Programming Model

tf1出来后google开始研究自己的tpu,还开发了自己的编译器xla,就是拿到tensorflow的一个图然后做编译优化,然后在tpu上运行,后面xla又不仅支持cpu也支持gpu了,成了tensorflow的一个默认后端
jax是类似于xla的前端,干的时事情就是把类似numpy的任务映射到xla上面,同时为了好用提供了很类似python的体验,就是按行运行。做了一个叫“延后执行”的优化,只要不是要马上打印马上需要的话,其实并没有去执行它,而是不断地在后面构建这个图,当发现不能再构造图的时候就停下来做编译优化再执行。但从用户角度来说跟numpy差不多
图2的jax.pmap做得事情就是把函数映射到两个tpu上面,但其实这每个小函数都是很好算的,如果每次都编译优化发送代加就太大了,所以又加了一个 @pw.program,每次都编译和发送一个大函数
Architecture
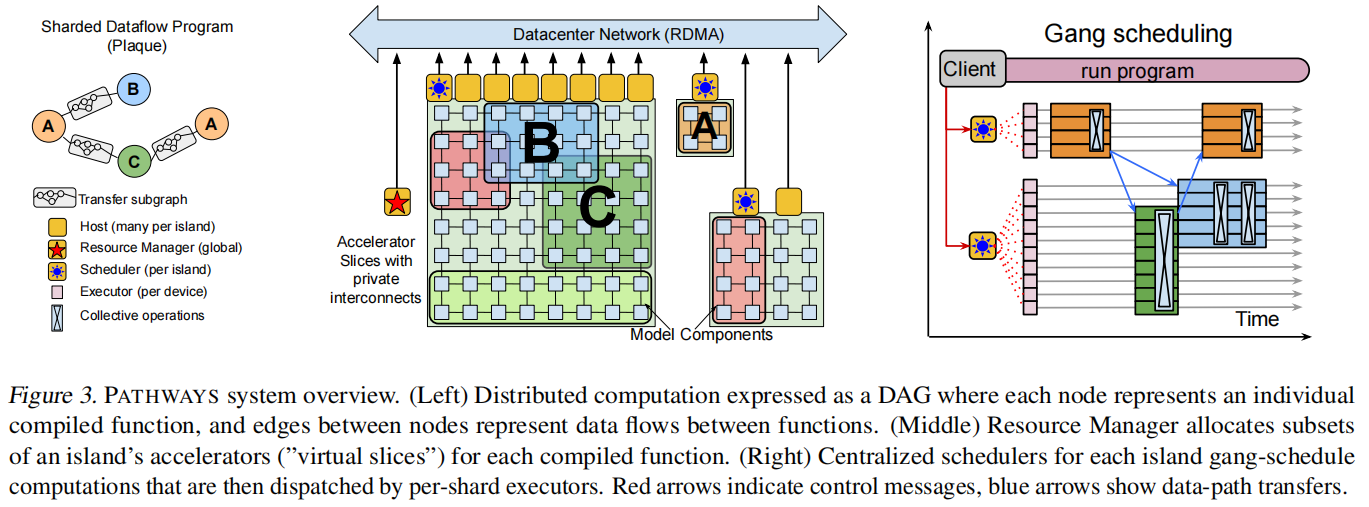
tpu核间有高带宽的连接,将信息发给相邻很快
整体大的叫一个pod,有2048个核,中间tpu连接非常快。但是pod和pod之间用的是网络中心连接,因为所有的应用程序都共享这些带宽所以相对速度会低一些。可以将一个pod理解为一张卡,那么tensorflow就是只支持单机多卡的训练,Pathways就想去支持这种pod级别的多机多卡
图3的ABC都可以理解为一个“岛”
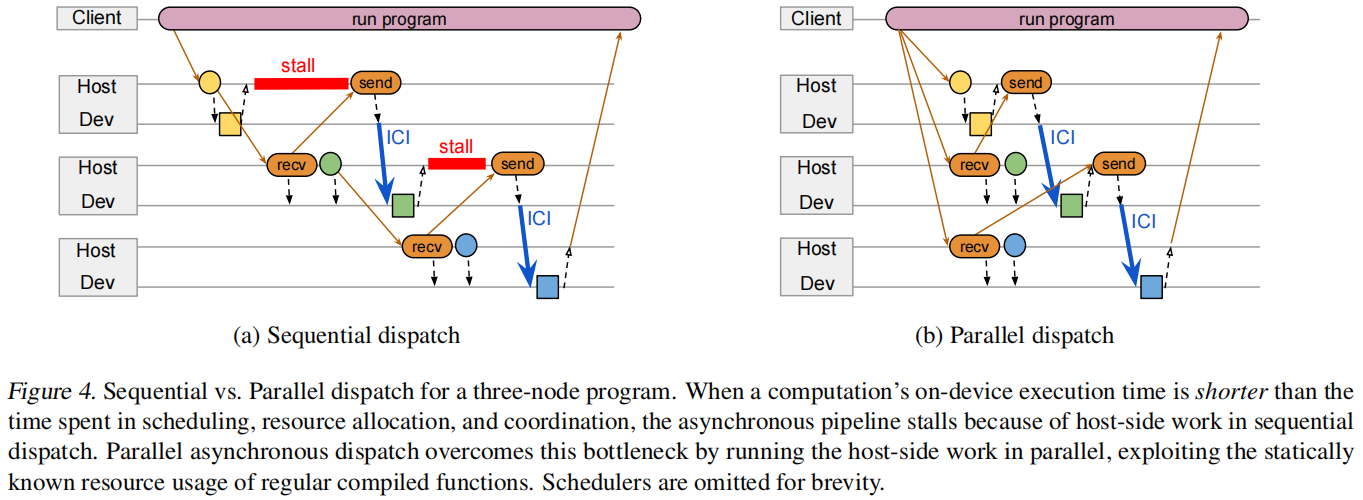
当知道后面的任务是什么的时候有些任务可以先完成避免任务很小导致调度协商等待很长

