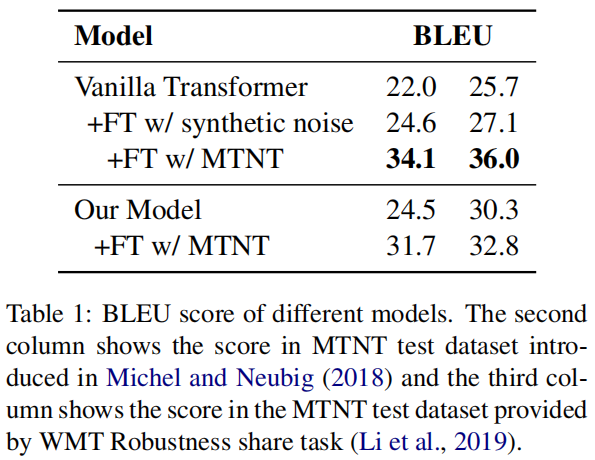
论文地址:Improving Robustness of Neural Machine Translation with Multi-task Learning
Multi-task Transformer:噪音编码器和干净、目标解码器
Abstract
神经机器翻译在干净的领域文本里面表现很好,但是当文本充斥大量语法错误、打字错误或其他错误的时候效果锐减,所以作者提出了基于transformer的多任务学习算法来抵抗噪音
Introduction
现实世界的数据,特别是在社交媒体领域,通常包含噪音,如拼写错误、语法错误或词汇变化等,但对人而言识别出来没什么难度,对神经机器翻译就很难了,所以有必要建立一个健壮的NMT系统
本文用了两个解码器,每个解码器都有不同的学习目标
-
第一个解码器:
- 读入编码器的输出
- 去噪解码器,将噪音语句生成对应的干净语句
-
第二个解码器:
- 读入编码器和第一个解码器的输出
- 翻译解码器,给定噪音语句和干净语句生成翻译的目标语句
这种框架应该会从两个角度受益
- 由于该模型是用有噪声的文本训练的,它应该更好地推广到有噪声的文本
- 翻译译码器可以潜在地利用恢复的干净句子,同时通过引用原来的噪声句子保持特定种类的噪声(例如表情符号)
Multi-task Transformer
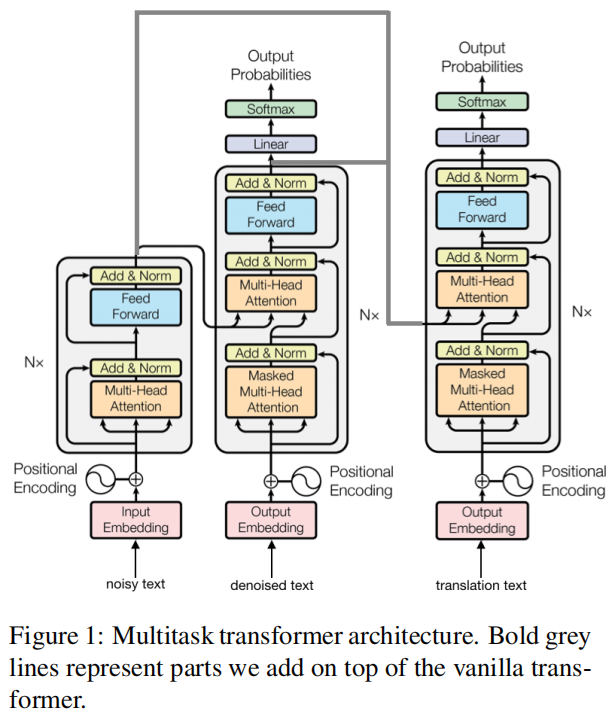
Detailed Architecture
数据集是三元组:$T={t_n,t_c,t_t}$,其中 $t_n$ 是噪音语句, $t_c$ 是干净语句, $t_t$ 是目标翻译
收到编码器注意力分数和降噪解码器注意力分数后得到最后的注意力上下文为
$$
A_t=W[A_n:A_c]+b
$$
Two Phase Beam Search
用了两个阶段分别的束搜索过程来解码最终的翻译
给一个语句 $t_n$ ,降噪解码器产生一个 $N_{beam}$ 的输出每个输出由一个降噪假设 $\hat{t}_c$,假设概率 $P(\hat{t}c|x_n;\theta)$ 和对应的隐藏矩阵 $M_c$,对于从第一个解码器产生的每个假设,第二个解码器也产生了 $N{beam}$ 元组,每个元组包括一个翻译假设 $\hat{t}_c$ 和它的概率 $P(\hat{t}_t|t_n,\hat{t}_c;\theta)$
在第二阶段结束时,会有 $N_{beam}\times N_{beam}$ 的翻译假设,根据下述公式定义的分数对假设排序
$$
\mathcal{L}(\theta)=\lambda \log P(t_c|t_n;\theta)+(1-\lambda)\log P(t_t|t_n,t_c;\theta)
$$
Training Triple Generation
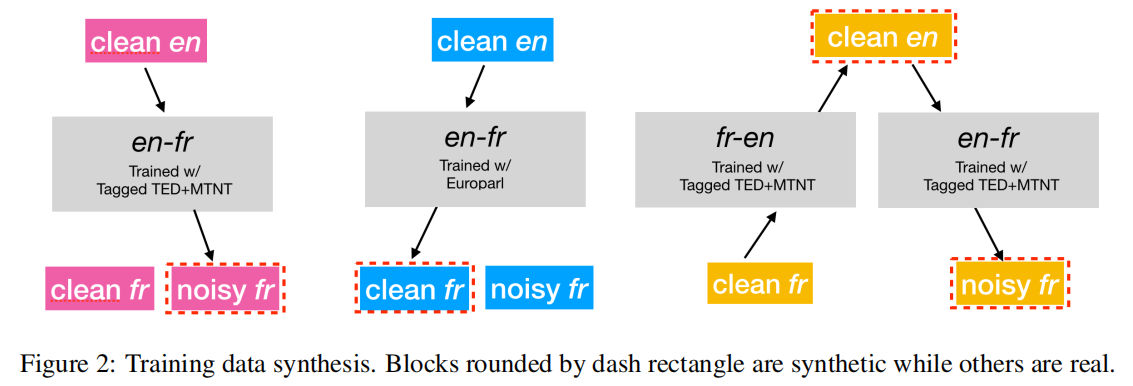
这种训练需要的三元组数据很少,可用的数据量不足以支持训练这种大参数模型,所以用反向翻译策略来合成三元组,作者提出的这种方法只有三元组里面有一个存在就行,作者主要关注的是从法语到英语的翻译,现在语料库最缺的就是有噪音的文本
Clean fr & Clean en
这是最常见的并行语料库,通过TED和MTNT训练数据训练的NMT模型来生成噪音文本。在每个句子的开头添加一个MTNT标签,并将它们输入到这个NMT模型中。理想情况下,除了不完全翻译所产生的固有噪声外,翻译后的法语句子也可以具有与MTNT相似的噪声分布。
Noisy fr & Clean en
这种并行文本可以在MTNT训练数据中找到。即使手动翻译的英语句子包含某种程度的“噪音”(例如表情符号),也将它们视为干净的英语文本。
Clean fr
设计了一个管道来利用单语数据来使反向翻译策略更适用。先将这些句子翻译成英语,然后再翻译回法语。如我们上面所述,这两个NMT模型都是用TED和MTNT数据进行训练的。在这两个方向上,在句子的开头添加了MTNT标签。也可以使用现成的NMT模型来生成干净的英语文本。
Experiments