MTL DA:数据增强技术降低解码器前置信息量,更关注编码器
Abstract
神经机器翻译里,数据增强(DA)技术常被用于当并行数据稀少的时候做额外的训练样本,许多的这种方法都是为了生成一些罕见词的新句子,从而使经验分布更趋近于真实的数据分布
本文提出了一种多任务DA方法生成新的句子对,在训练过程中,这些增强的句子被用作多任务框架中的辅助任务,目的是在目标前置的信息不足以预测下一个单词时提供新的上下文,加强了编码器的同时使解码器更多关注编码器的表征
Introduction
有很多方法来解决低资源数据问题,比如从高资源数据上做迁移学习,使用语言注释,多语言系统和数据增强方法来生成额外的并行句子
数据增强方法被很多人视为是解决数据分布不匹配的解决方案,在增强后的数据集上进行训练既能得到更广泛的支持,同时也不会面对完全是分布外的数据情况
本文提出了一种完全不同的DA框架,生成了额外的平行句子,尽管在数据分布下完全不可能,但系统地提高了 NMT 系统的质量。此外,为了避免因分布外的数据生成有害的推理,还使用了一个简单的多任务学习方法,这种框架不需要详细阐述的处理步骤,也不需要训练额外的系统或是额外的数据
Multi-Task Learning apporach and auxiliary tasks

swap
目标文字对被随机交换,只有 $(1-\alpha)\cdot t$ 的单词保留原来的位置,主要是迫使系统去预测时不那么依赖目标前置信息
token
$\alpha\cdot t$ 的随机单词被替换为UNK,当生成新单词的时候降低目标前置信息的信息量,使系统去更多关注于编码器,这是防止防止自分编码器后向崩溃时的有效设想
source
目标句子变成源句子的复制。这种方法生成正确输出的方法应该是检查编码器的表示来从源数据中复制,一些作者认为这种方法有害于训练,只有反向复制是有效的,但MTL框架可以允许利用这种合成的数据
reverse
目标句子反向,还是希望编码器可以学到更多信息
mono
对目标词进行重新排序,使源词和目标词之间单调对齐,还是希望更专注编码器
replace
$\alpha\cdot t$ 的随机选择源-目标对齐的词汇,并用从训练语料库中获得的双语词汇中的随机条目替换。这种转换很可能会引入那些由于仅依赖于目标语言的前缀而难以产生的单词,从而迫使系统注意到源词
Experiment
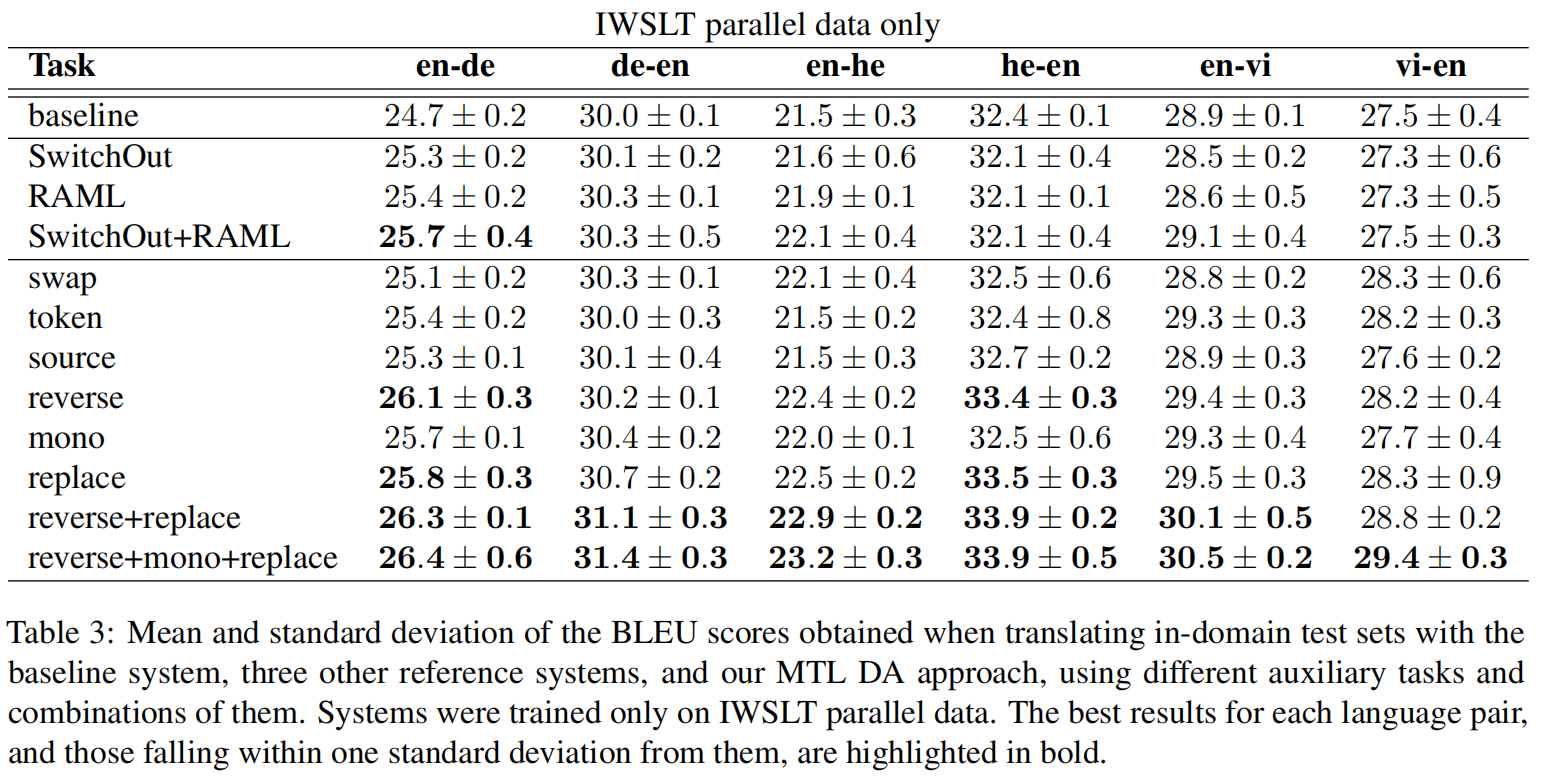
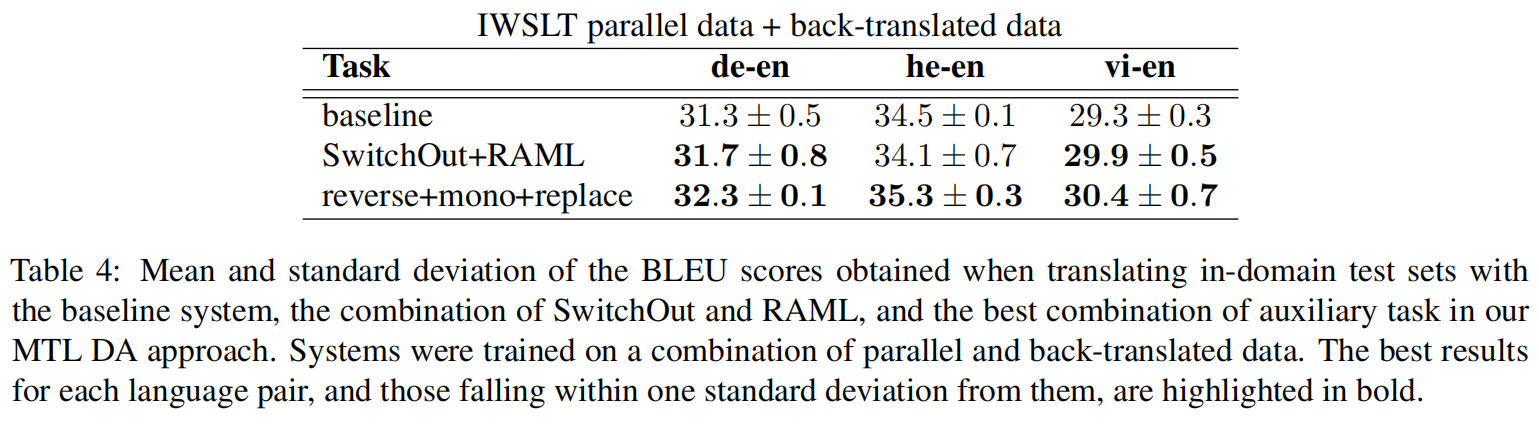
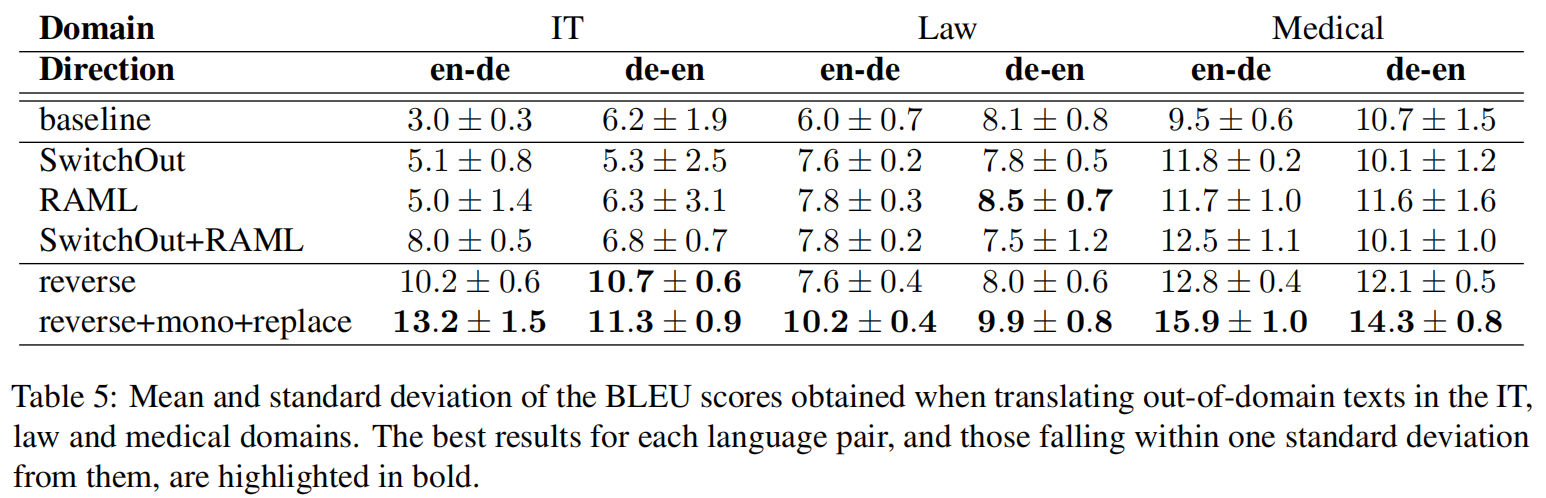
在领域文本的效果提升比较大,说明对于专有词汇还是有相当不错的效果

