Model Validation
一个在给定数据集下训练好的模型,用合适的评估指标来衡量模型在新数据上的效果好坏,检验模型的泛化能力
Model Metrics
-
在监督学习,我们训练模型来最小化损失
- 损失值是广泛使用的指标来衡量模型的质量
-
这里有很多其他指标
- 模型特有:分类准确率
- 商业特有:收入,推理时间
-
我们选择模型通过多种指标
- 就像是选车要考虑安全、舒适、外观、性能等等
Case Study:Displaying Ads
-
广告是很多互联网公司的主要收入源
-
搜索网页 -> 取回相应广告 -> 通过CTR评估点击率(简单二分类问题,点还是不点) -> 通过CTR x price排序展示广告
-
其实对于广告而言,用户点击概率很小,顶多百分之几,所以样本中正例是很小的,更多是负例
Metrics for Classification
-
准确率:正确预测/总样本
1
sum(y == y_hat) / y.size
-
精确率:正确被预测为i类 / 预测为i类的样本
很多时候我们并不关心对负类的预测,更关心对正类的预测,因为负类预测对了对业务往往也没有多大的好处
1
sum((y_hat == 1) & (y == 1)) / sum(y_hat == 1)
-
召回率:正确预测为i类 / 样本中i类的个数
1
sum((y_hat == 1) & (y == 1)) / sum(y == 1)
-
F1:平衡精确率和召回率
- 2pr/(p+r)
AUC & ROC
-
AUC,在ROC下面覆盖的区域面积,衡量模型区分类别的概率
-
选择一个变量 $\theta$ 为置信率,如果 $\hat{y}>\theta$ 救预测为正类,否则预测为负类
-
比如正负样本平衡的时候取个0.5
-
实际生成过程中会根据实际情况来选择
-
x轴是错误预测为正类的样本/负样本,y轴是正确预测为正类的样本/正样本,取不同的 $\theta$ 值可以得到不同的曲线,是精度和召回的一个权衡
-
AUC=0.5最糟糕,完全不能区分分布
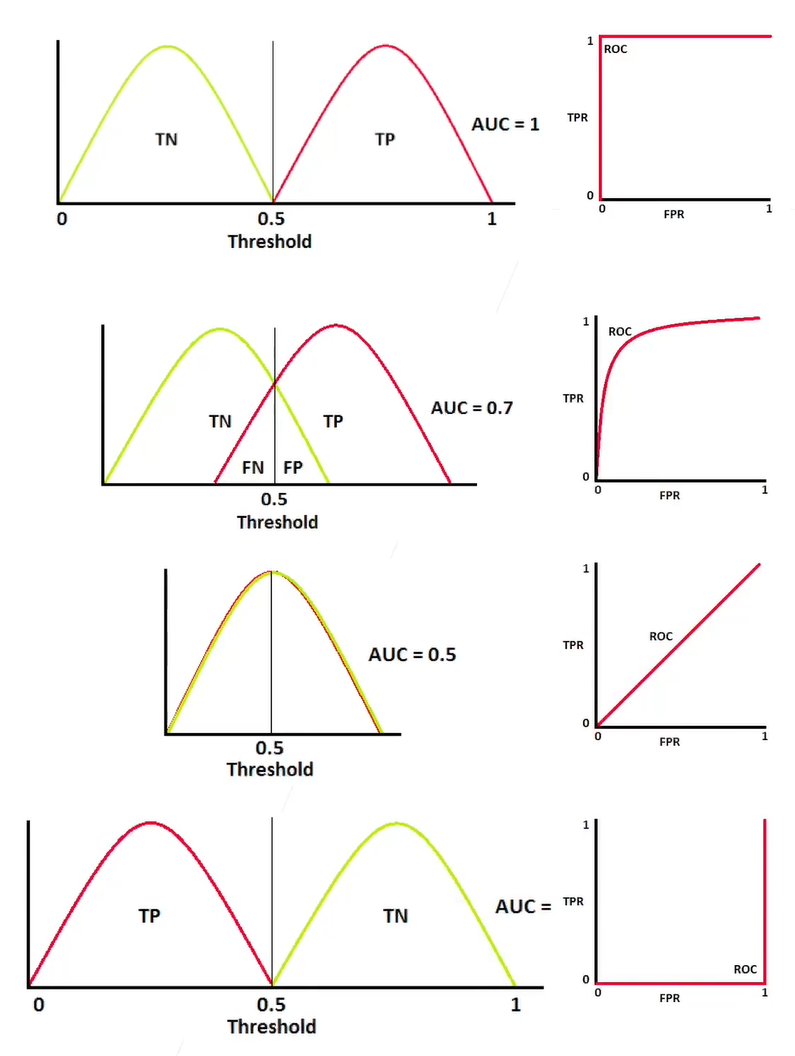
-
Business Metrics for Displaying Ads
- 优化收入和用户体验
- 延迟:广告在同一时间给多少用户展示,模型抽取特征、预测等等一般要在300或500ms以内
- ASN:平均每个页面多少广告
- CTR:用户点击率
- ACP:广告商给每次点击平均付多少钱
- 收入 = 流量 x ASN x CTR x ACR
Displaying Ads: Model -> Business Metrics
- 模型的关键指标AUC
- 一个模型提升了AUC但可能有害于商业指标
- 选择了不同的广告来展示,这些广告可能有
- 更低的预测CTR-> 更少的广告展示
- 更低的真实CTR,可能因为只评估了过去的数据,新数据下用户行为发生了变化
- 更低的价格
- 选择了不同的广告来展示,这些广告可能有
- 主要的解决方法还是在真实的数据上观察商业指标
Summary
- 我们用很多标准来评估模型
- 模型评估标准反应了模型在样本上的表现
- 比如准确率,精确率,召回率,AUC等
- 商业指标反应了模型对实际生产的影响

