论文地址:GPipe:Efficient Training of Giant Neural Networks using Pipeline Parallelism
机器学习系统方向往往是自己提出一个大的任务目前解决不了,需要设计一个新系统来解决,但其实很多时候这种假设是现实中不存在的,比如一个特别大特别深的全连接神经网络一个GPU塞不下,确实可以来设计一个系统使它能够训练出来,但是这样其实没什么意义,换一个架构计算、通讯里面的参数都完全变了,之前的优化和设计对真正有用的网络就不合适了
GPipe:把任务切更细使得流水线并行
Abstract
将神经网络变大是有好处的,但变大之后内存需求就超过了单个加速器的容量,把一个模型拓展到多个加速器的时候需要特殊的算法或架构,这些解决方案往往跟架构相关不太好迁移到别的任务上去。为了满足高效并且任务无关的模型并行,作者推出了GPipe,一个流水线并行的包,只要网络可以用层来表示就可以使用它
主要是把不同的子序层通过流水线的方式在多个加速器上执行,做到有灵活性且性能比较好。还使用了一个创新的批量分割算法,当一个模型跨多个加速器进行分割时,结果几乎是线性的加速
在两类网络上做了实验,效果都很好,图片和多语言机器翻译
Introduction
模型变大了是有好处的,模型变大性能变强
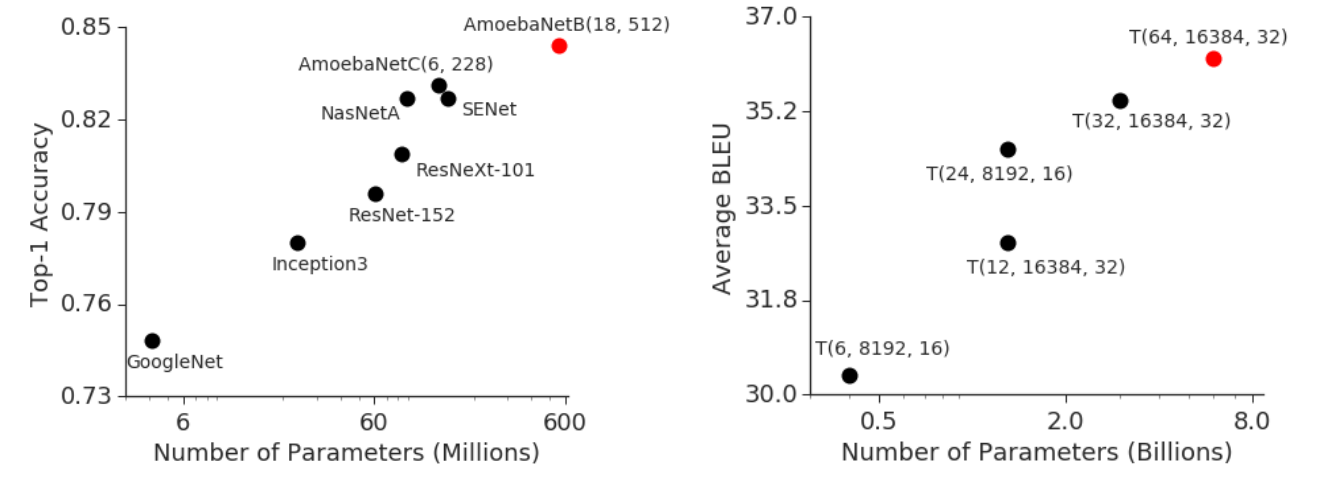
更大的网络存在硬件的局限性,有内存限制和带宽限制,但其实不是不能做大做强,只是成本太大了
正常的做法叫做模型并行,就是把模型切成很多个小块,放到不同的加速器上运行,但这样带来的问题就是到底该怎么切,横着切,竖着切等等
GPipe的两个主要技术:
- re-materialization:把一些中间结果丢掉,下次要用的时候重新计算,这样能减少一些内存占用率
- micro-batches:将小批量再切到更小尺度来流水线并行
The GPipe Library
用了一个叫Lingvo的框架,是基于tensorflow的一个框架,针对变长的语言模型,跟Keras有点像。这个框架有一个很大的特点叫做可重复性,也就是同样的代码不同人复现出来应该是同一个结果,所以它的做法就是把超参数、数据集等等全部都要写在代码里面,所以对于一个网络不管是一个层还是一个数据集,它都是基于同样的一个基类,这个基类本质上是一个字典,把比如batch_size等的key和value存好
一旦做好了版本控制,比如一个结果是某个版本的代码跑出来的,那只要拿出来就可以完美重复前人的工作
Interface
一个神经网络可以定义成一个L层的序列,每一层都可以当作一个前置的函数和其可学习的参数,GPipe还可以告诉用户每一层的开销是什么,比如多少flops。定义好这个任务之后给定把网络切成K块,即K个子序列,每个子序列表示一个单元,假设p_k对应的是第k个单元,切好了就是计算
Algorithm
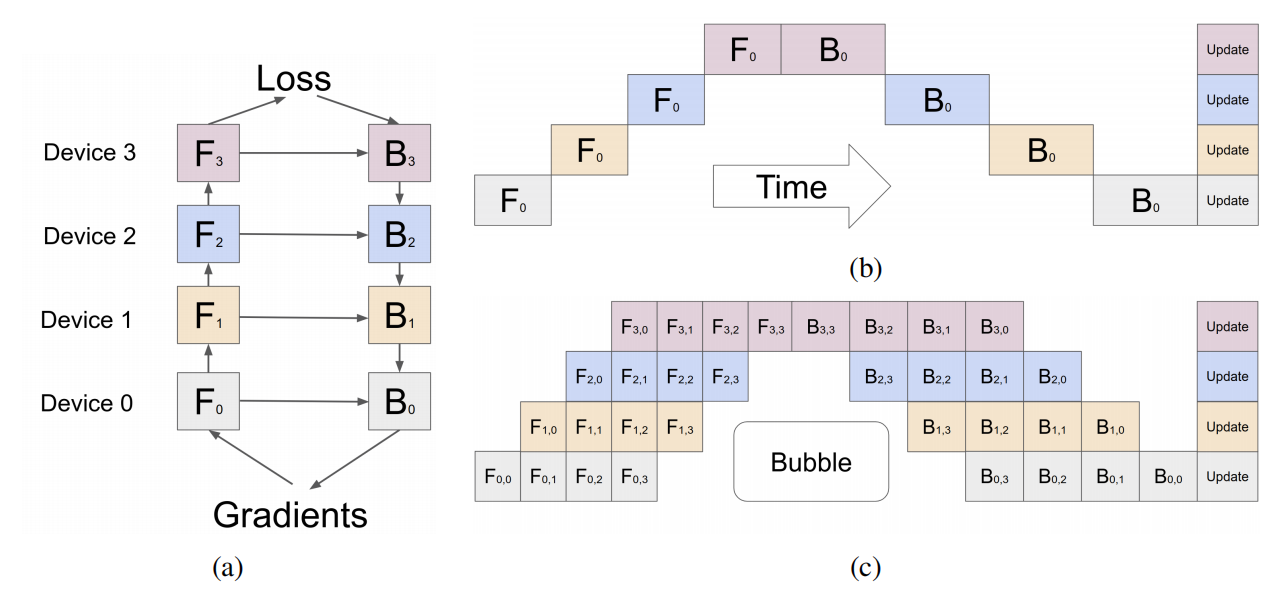
把第k块放在第k个加速器上,这种叫模型并行,本质上其实就是内存翻了K倍,把大模型切下来在GPU能放得下而已,但是数据并行是切数据放到不同的GPU上运行,这样每个GPU保存完整模型并通讯
从下面这个图可以看到,其实粗暴的模型并行方法并没有并行起来,其实就是一个串行,每时每刻其实都只有一个GPU在计算,效果并不好,所以这篇文章就要解决这个问题,提出了流水线并行,具体的方法其实是把数据再切开,把小批量切成微批量,每次在微批量做梯度,最后把梯度加起来就行了
下面这个图c就是把小批量切成4分,切得块足够多的时候,所有GPU同时做运算的占比会增加
Performance Optimization
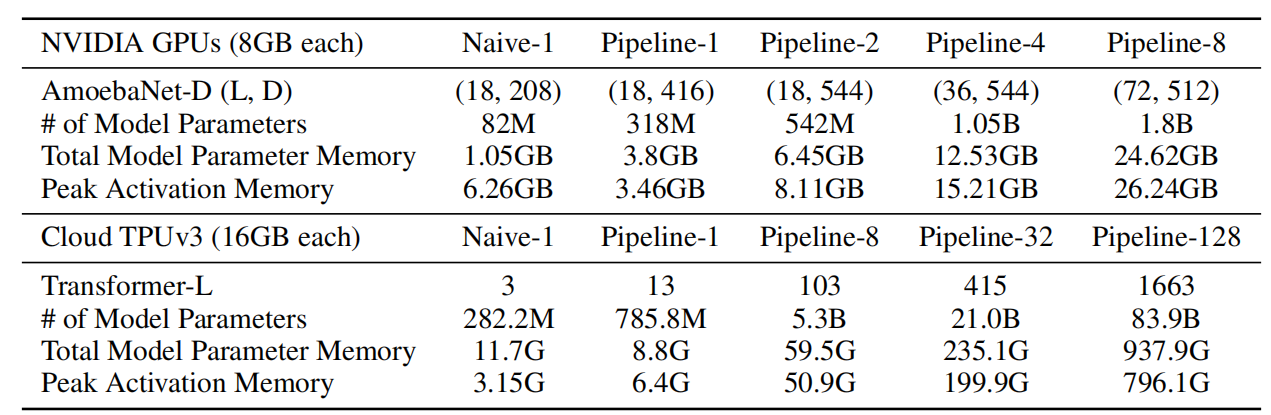
还是有大量信息还是要放在激活内存里的,因为有一些计算的中间值是不能丢掉的,比如计算链式法则的中间结果,这个大小往往和批量大小n和隐藏层大小d相关,是一个nxd的大小,所以有可能会特别大
编译器常见的作法是用计算来换空间,把中间结果丢掉,只存输入,下次要的时候再一个个算。作者的具体做法是每个加速器维护一个单元,只会存边界的信息,其他地方信息就丢掉
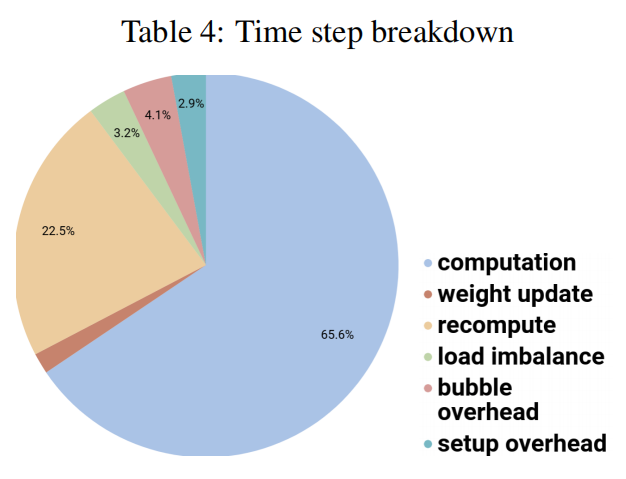
作者指出只要对数据切块M>=4K,那流水线的开销就可以忽略不计了,但因为重新计算带来的额外开销大概在30%,还有一部分开销是通讯开销
一个重点是要平衡各种开销,不然就容易产生瓶颈
Performance Analyses
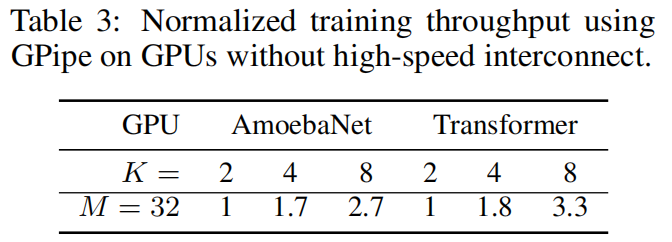
把小批量切成多少块有用,因为CNN不那么均匀,维度减少的时候通道由在增加,所以切起来会产生瓶颈,用了8块卡也才翻了3倍,但是对于transformer这种固定维度的效果就很好
模型并行每次通讯的数据比数据通讯要少
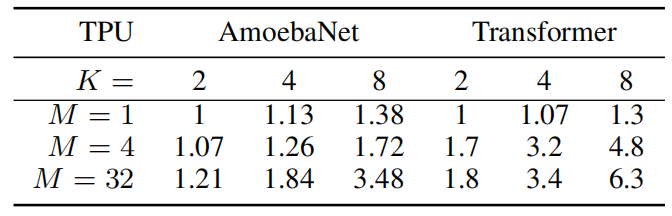
额外开销占比大概30%
Conclusion
- 高效性:近乎线性的增加效率
- 灵活性:能支持任意的层级网络
- 可靠性:同步梯度下降,理论上和单卡运行是一样的

