论文地址:Megatron-LM:Training Multi-Billion Parameter Language Models Using Model Parallelism
论文实现:https://github.com/NVIDIA/Megatron-LM
作者在里面攻击前面方法的主要点就是需要编译器,需要其他包什么的,很繁琐,这个方法只需要在pytorch里面对代码进行一点小修改就行,但这种方便性带来的局限性也就是只能针对transformer做这种操作,不够通用,而前面的方法是希望有更通用的处理方法,所以优点缺点都是在取舍之间反复横跳的
Megatron LM:transformer的语言模型的模型(张量)并行
Abstract
现在的transformer模型越来越大,且内存限制下难以训练,作者提出了一种层内的模型并行训练方法,这个方法不需要新的编译器或者外部包,和之前的pipline的方法是互补正交的关系,只需要在原生的pytorch里面插入一些通讯的操作就行了
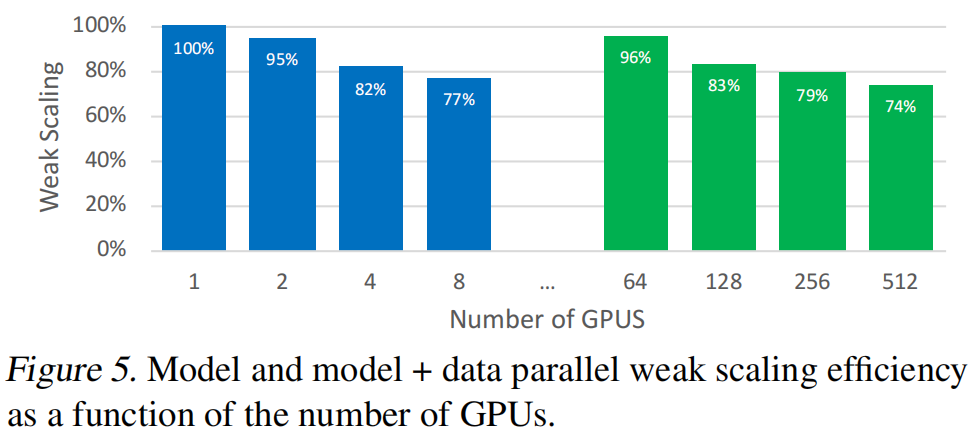
相较于单卡30%的最高峰值,可以达到76%,主要训练的是GPT-2和BERT
Introduction
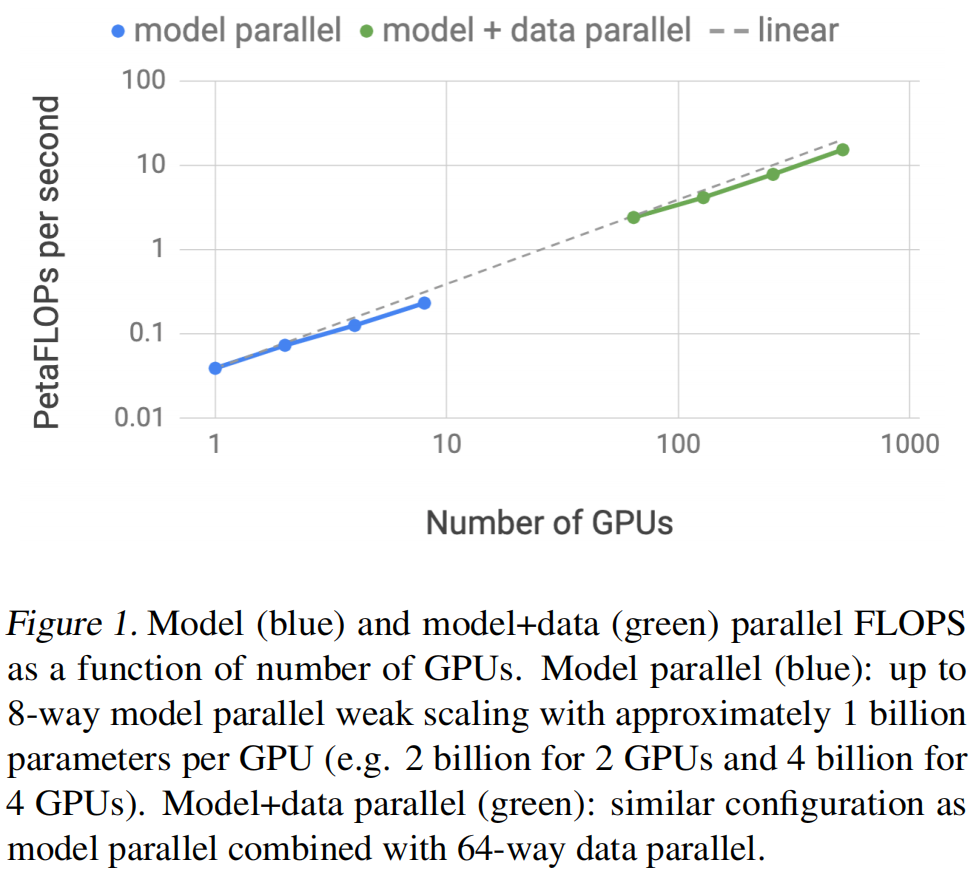
作者表示拿到了基本上增加显卡就可以有线性的提升,好到不真实
主要贡献如下:
- 作者实现了一个简单有效的模型并行方法,只需要做一点点现有的pytorch的transformer的修改就可以了
- 做了比较深度的实验分析,在512个GPU上获得了76%规模的效率
- 把BERT类似的模型变大了之后需要注意layer normalizaion的位置
- 对GPT-2和BERT来说模型增大会提高精度
- 展示了在WikiText103、LAMBADA和RACE效果多好
- 开源代码:https://github.com/NVIDIA/Megatron-LM
Model Parallel Transformers
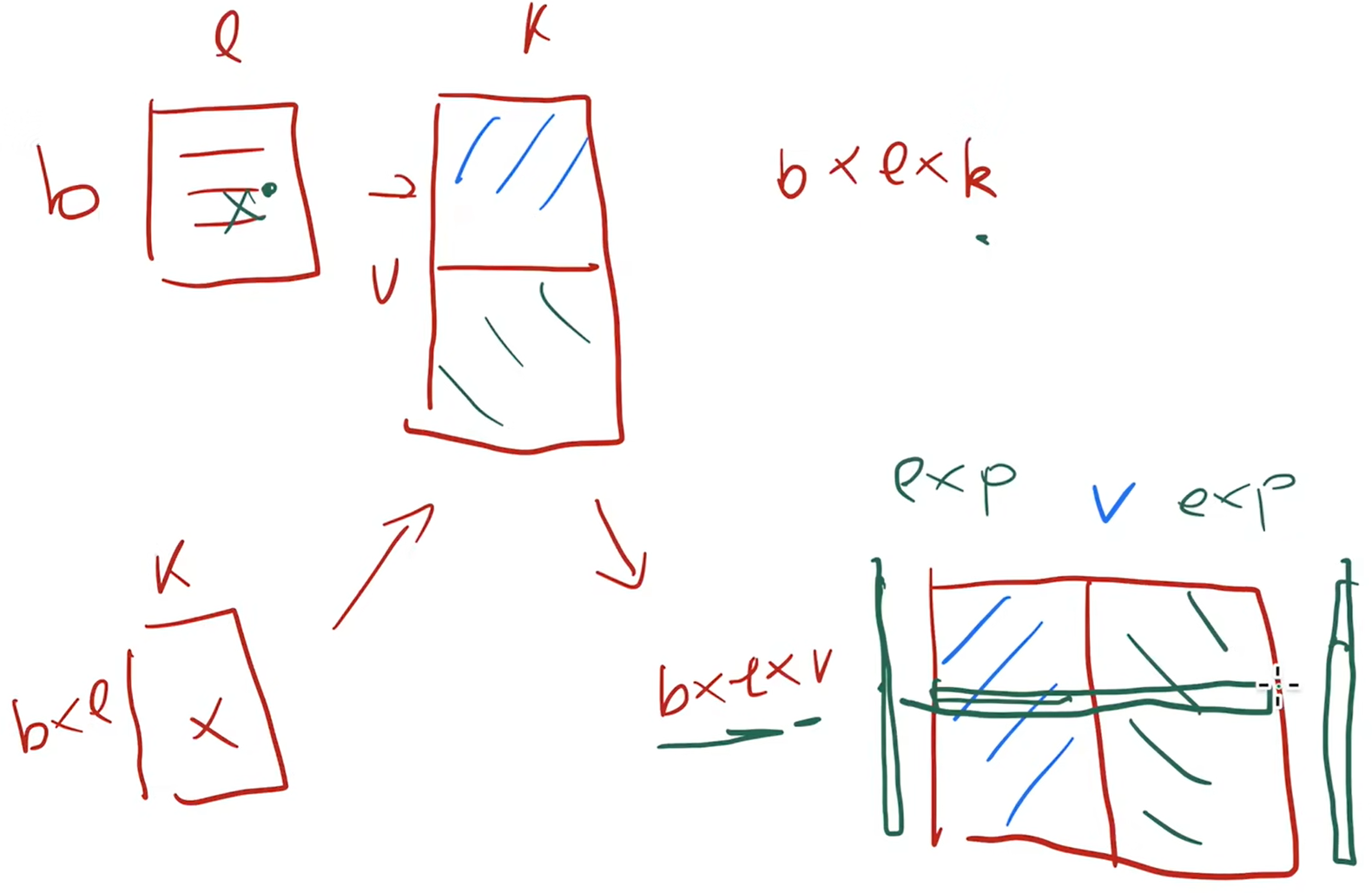
在MLP上假设竖着切一半,开始的X复制到两个GPU上,最后的结果得到的是两个同样的Y,只是各有一半的结果,再做一次allreduce就可以
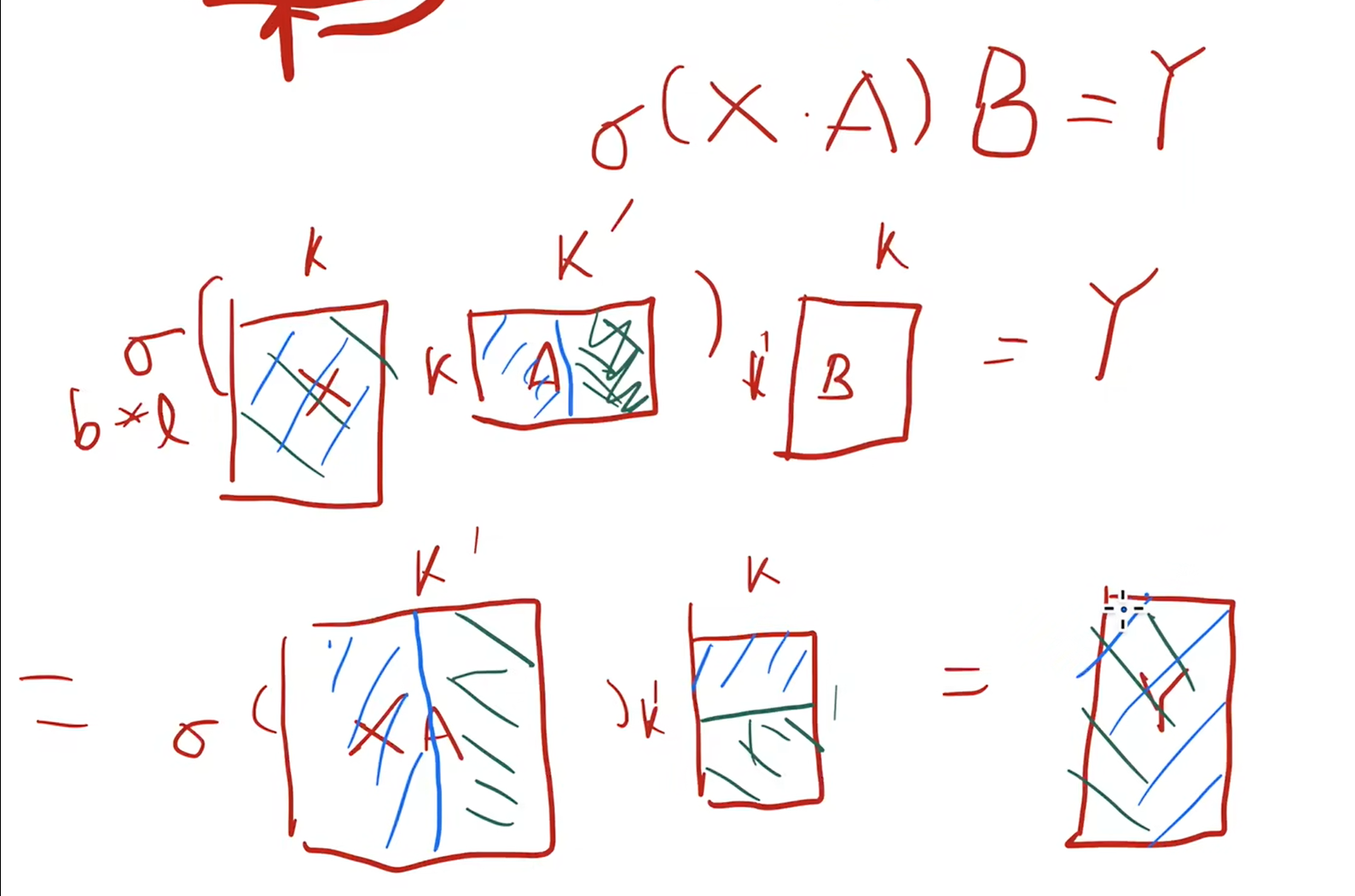
在多头attention上,每个头都是独立并行的,有自己的权重,一个简单的方法就是把头分到各个GPU上,假设一半在一个GPU上,另一半在另一个GPU上,算出来跟上面一样,只是一半的结果
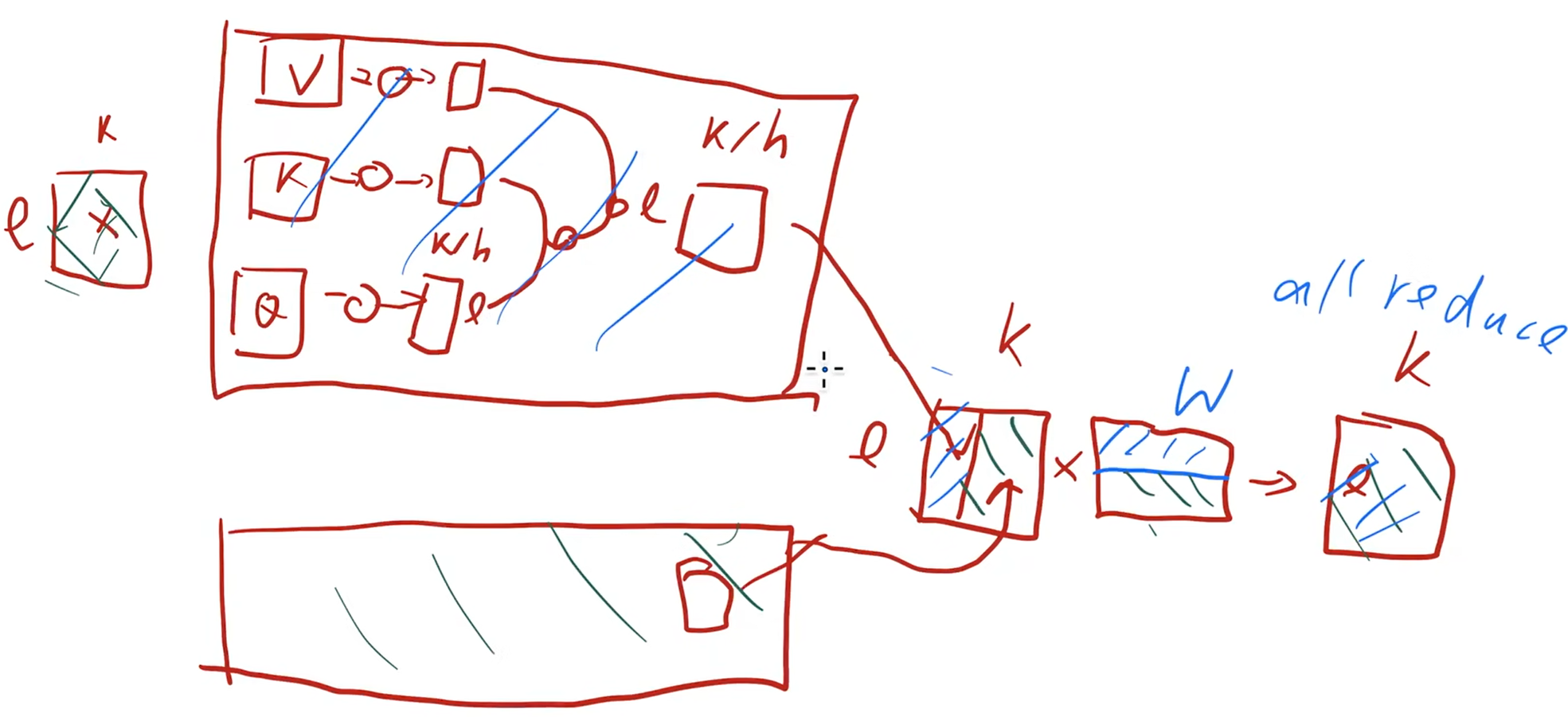
输入层X是batch_size x len,embedding是vocab_size x K,X进去之后变成 bxLxK,一种切法是把embedding切一半,把X复制到两个GPU上,查完了再allreduce
输出层是bxLxK,经过词典后变成了bxLxV,两半各在两个GPU上面,每行是一个样本。一个问题是这个V可能很大,通常有好几万,而K是一万以内的东西,所以每个GPU先算自己的指数,再按行求和
当然这种切块的方法需要每次计算完就做一次allreduce,切多少次就多多少开销,不能异步进行。每块通信量其实是一个固定的值,每次算完是一个bxLxK的大小,all和reduce是两倍的开销,所以这个开销就是o(bxLxKxN),N是块数
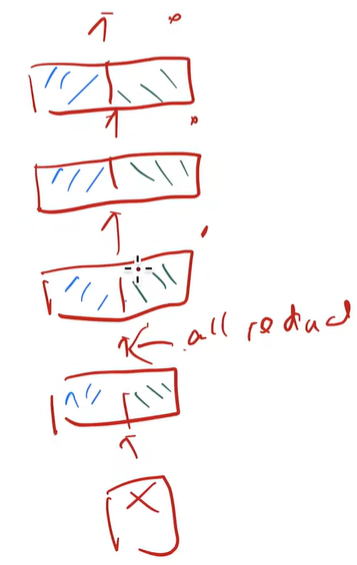
模型并行
- 好处:每个GPU只用维护一块模型就行了
- 坏处:需要GPU数量能被注意力头、层数整除;不能数据计算和数据通信并行,就是不能异步,必须一步步来
Experiments
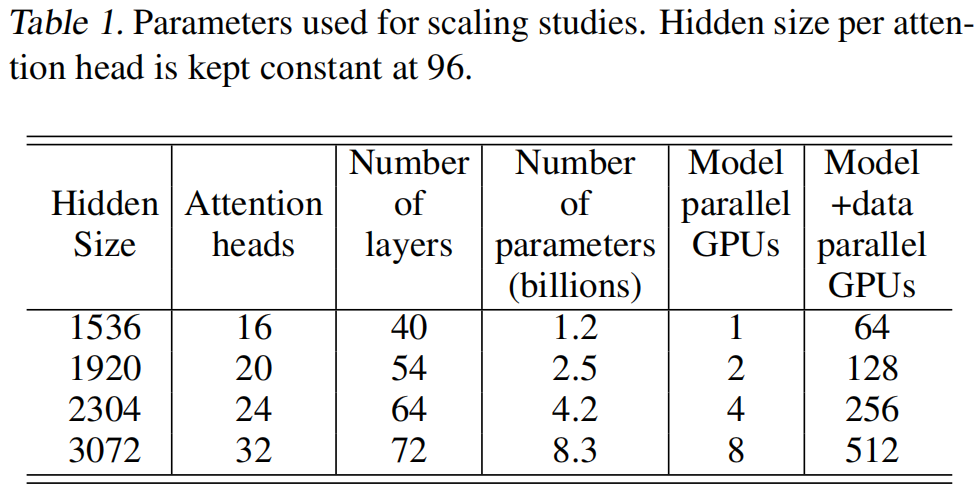
选了1.2b的模型做基线,能放在单卡上
卡多了通信成本也更高了