DETR:transformer用到目标检测
Abstract
作者提供了一个把目标识别变成集合预测问题的方法,主要贡献是提出了一个新的目标函数,通过二分图匹配的方式能够强制模型输出第一无二的预测,另一个贡献是实用了一个transformer的编码器解码器架构。还有就是使用了一个学习目标查询(learned object queries),和全局图像上下文一起做注意力操作让模型能够直接并行输出预测框
主要特点之一是简单,不需要特别的库,第二就是能够简单的拓展到其他任务,比如全景分割
Introduction
端到端的思想直接避免了很多冗余的任务处理,先前目标检测领域里很少有端到端的方法,大部分都需要一个后处理的操作就是nms,non-maximum suppersion非极大值抑制,无论是proposal based方法,还是anchor based方法还是non anchor based方法都会生成很多预测框,nms就是要去除这些冗余的预测框,但由于nms存在使得模型调参变得复杂,而且训练好了模型部署起来也困难,因此一个简单的端到端的系统是大家梦寐以求的
作者就提出不需要先验知识,就是要一个简单的端到端的方法就能取得很好的结果
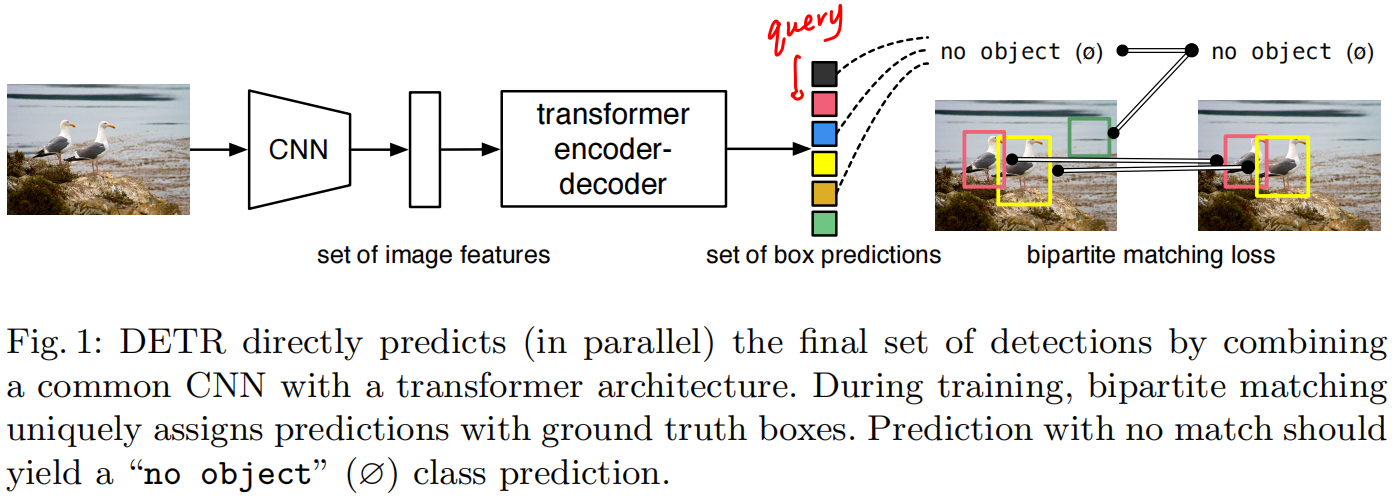
- 先通过CNN抽特征,然后把特征拉直
- 送给transformer的编码器解码器,为什么要用transformer最简单直观的理解就是每个点或特征都会和图片里其他的点或特征有交互,那编码器就大概知道哪块是哪个物体,对于一个物体而言就应该只出一个框而不是多个,所以对于这种全局特征有利于移除冗余的框
- 然后解码器和query做自注意力,query就设置了会出多少个框,作者设定的是固定值100,最后就会出100个框
- 比如上图就通过二分图匹配得到100个框中哪两个框和图中两个框(ground truth)最接近,然后才会去正常的计算分类loss和banding box的loss,至于剩下的框就会标记成没有物体
推理的时候第四步的loss就是不需要的,输出的时候就用一个阈值卡一下模型的置信度,比如置信度大于0.7的就作为前景物体
最终结果发现在大物体上表现比较好,可能是transformer能够全局建模了,但是在小物体上效果就一般了,还有个问题是训练比较慢
Related Work
Object detection
现在大部分的目标检测器都是根据已有的一些初始的猜测来预测,比如tow-stage用的是proposal,single-stage用的是anchor,但最近的工作发现他们的性能和初始的猜测非常相关,所以怎么去做后处理对性能影响很大
Set-based loss:比如先前工作有这种可学的NMS方法和关系网络,但是这些方法虽然用集合目标函数,但性能都比较低,需要一些手工干预人工设计场景才能有比较好的结果,这跟作者的思想就背道而驰了
Recurrent detectors:用编码器解码器的方法都比较老,而且用的RNN,这种自回归模型时效性也会比较差
The DETR Model
Object detection set prediction loss
DETR输出是固定的N个,一般来说这个N应该比图片的物体多很多。输出这么多框需要用二分图匹配方法来确定哪些框是和ground truth是匹配的
具体二分图匹配方法就是假设有工人abc,他们干xyz不同的活有不同的开销,这样组成一个开销矩阵,怎么找到一个最优组合让工人干最省的事,当然可以穷举出来,只是这样复杂度太高,于是就有了匈牙利算法,通过scipy里面的Linear-sum-assignment函数实现
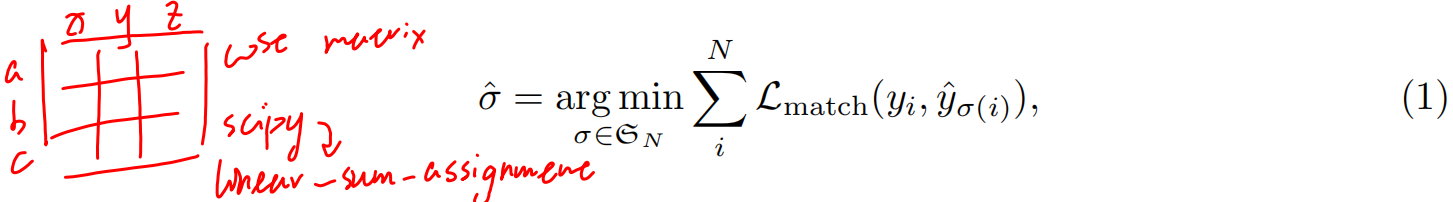
在目标检测里就是有框abc,目标物体xyz,里面填得就是损失,损失包含分类损失和框准不准的损失
作者表示这种找最优匹配和利用人的先验知识是差不多的,只是这里约束更强,一定要得到一对一的结果,只有一个框和ground truth的框是对应的,这样才不会做后续的nms处理等等
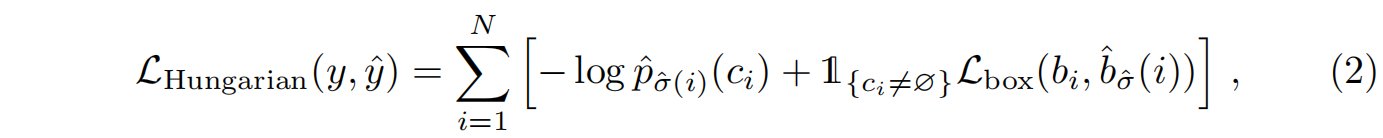
算完最优匹配最后再算真正得目标Loss
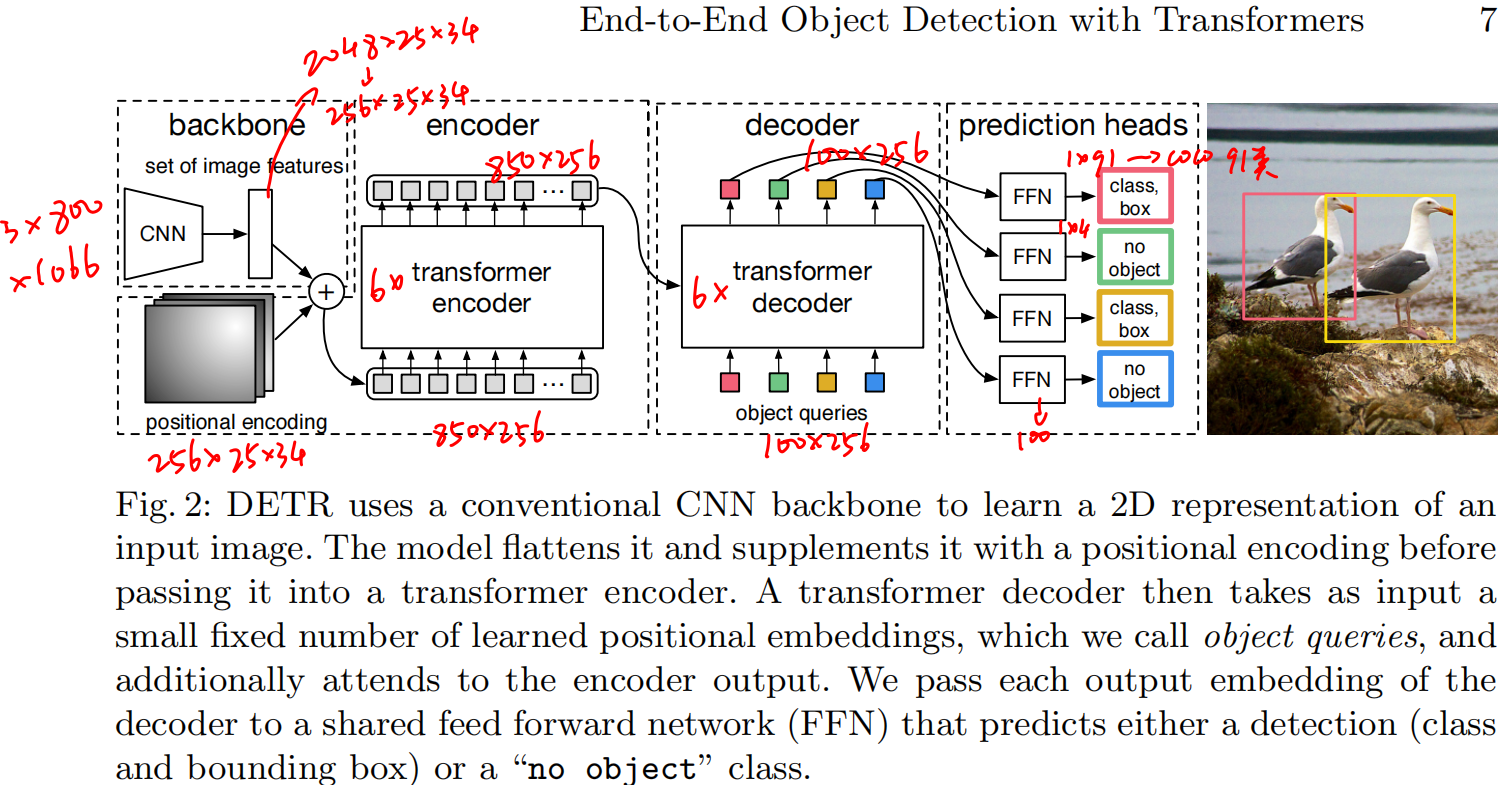
DETR architecture
Experiments
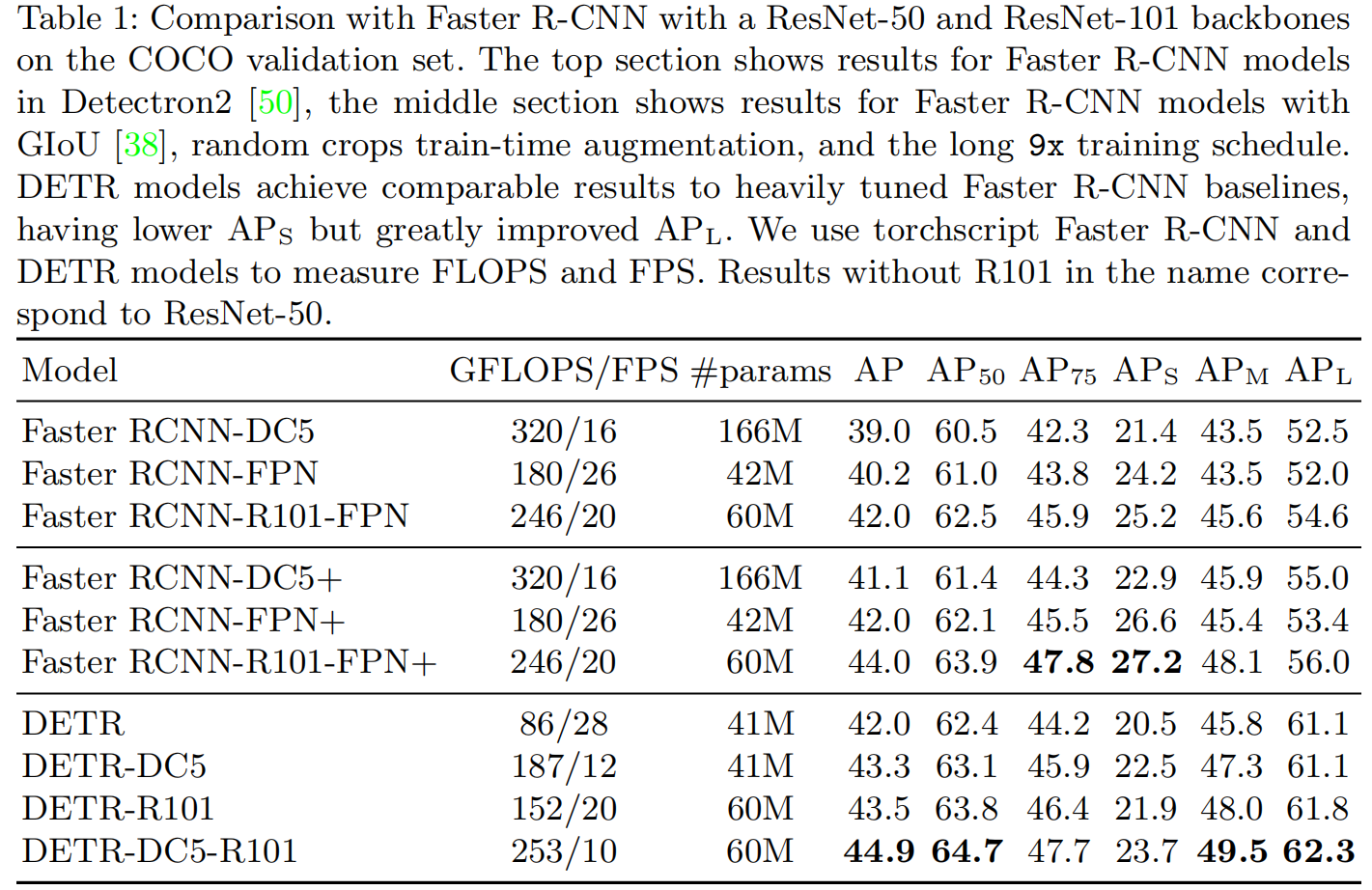
改一改训练策略,不增加参数也提了两个点,但DETR跑的确实比较慢,在FPS上少了一半。同时因为这个框架比较简单,所以处理小物体上不是很好

可以看出点一些基准点做自注意力就已经区分很明显了
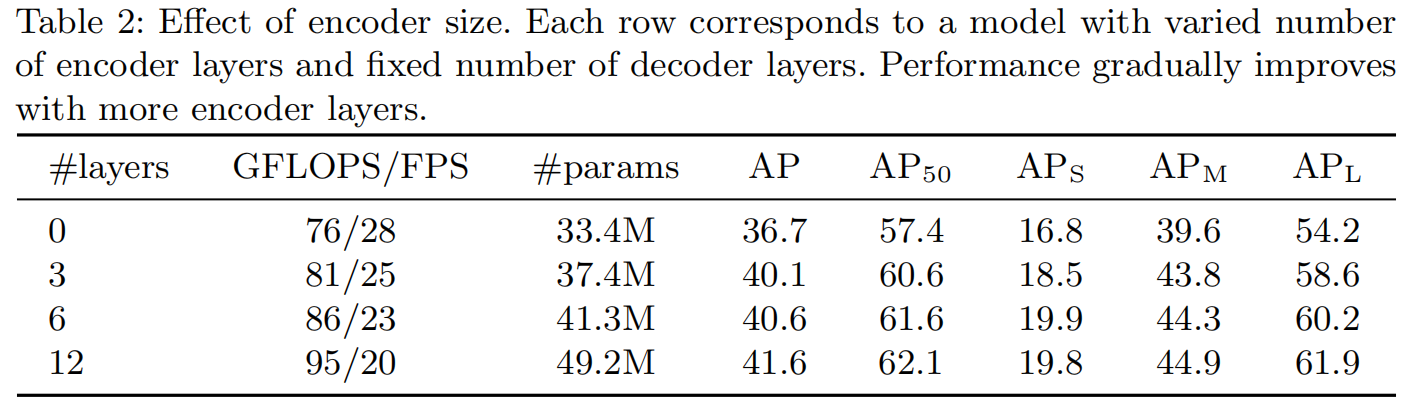
层数越深性能更好
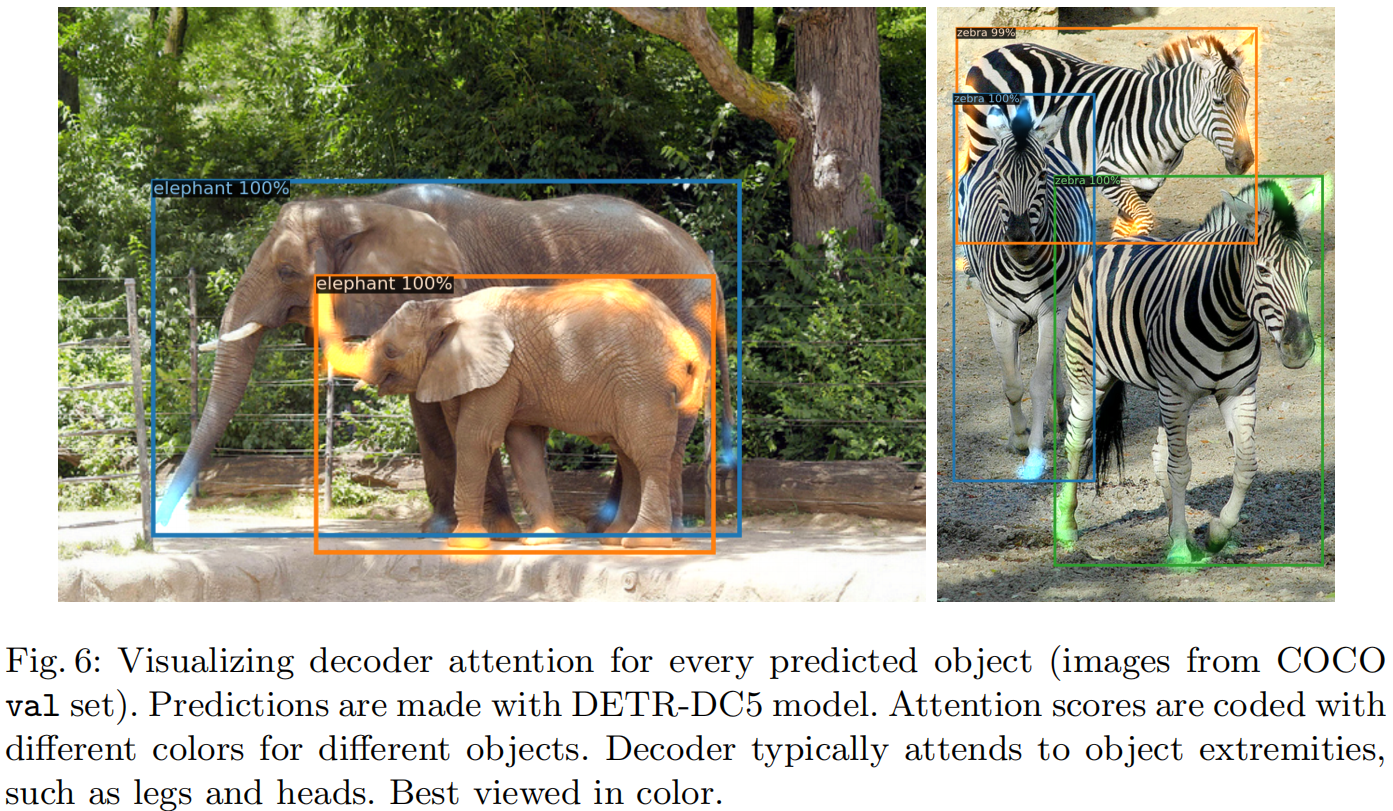
transformer的编码器和解码器一个不能少,编码器学习区分物体,解码器学习边缘处理遮挡物体

看看object query到底学了什么,绿色表示小物体,红色表示大的水平物体,蓝色表示大的垂直物体,上面画了20个object query去问了图片什么内容。同时每个object query都会问中心是不是有一个大物体,可能是和coco数据集有关
Conclusion
作者提出了全新的框架,主要用了transformer和二分图匹配,而且非常简单,效果不错,有潜力扩展在其他任务上。缺点就是训练太长了,小物体效果不好

