论文地址:InferCode:Self-Supervised Learning of Code Representations by Predicting Subtrees
InferCode:预测子树+TBCNN
Abstract
学习代码表示在代码分类,代码搜索,注释生成,bug预测等很多任务都有用,目前的学习方法有一个巨大的缺陷就是主要是在有标注的特定数据集上训练,很难应用到别的任务上去,所以作者提出了InferCode将自然语言处理的自监督学习方法迁移到了抽象语法树上。主要创新点在于通过预测从AST的上下文中自动识别出的子树来训练代码表示,模型使用了基于树的卷积神经网络(TBCNN)作为编码器
Introduction
先前的方法主要有以下限制阻碍效果和泛化性:
- 训练只针对特定任务,且需要提供标注数据或特征
- 尽管一些方法是生成可迁移的代码表示,但是往往仅适配于一些固定的代码单元,比如词元,声明或函数等,不能灵活的为不同的代码单元生成嵌入。这种方法可能会缺失不同类型单元的多元性和重要信息,不能很好迁移到下游任务
- 一些图的方法需要额外构造开销,并且可能引入不准确信息
因此,本文主要的解决目标为:
- 不需要手工标注数据进行训练
- 对于任意可以用抽象语法树表示的代码单元都能灵活的生成嵌入表示
- 泛化性足够强能够使用到各种下游任务
实现以上目标本文有两大支柱:
- 大量的公共代码数据训练
- 自监督学习方法的进步
可以作为编码器,也可以作为预训练模型,使用了多语言联合词库,在五个下游任务上测试
Approach Details
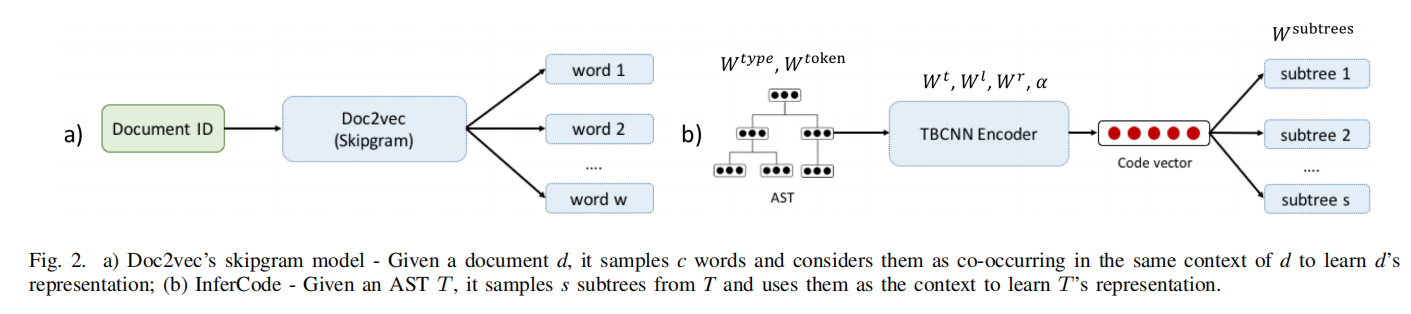
主要步骤如下:
- 对于每个AST识别出子树集合,将所有子树累积在子树词表里面
- 将一个AST丢进TBCNN得到向量,用这个向量来预测上一步识别出来的子树
- 编码器训练好了后作为预训练模型迁移到下游任务
Process to Identify Subtrees
不太考虑粗粒度的子树,比如if,while,for等声明,因为这些子树通常很大,作为一个单独的子树词表的词汇可能太少见了,编码器很难学到有用信息,并且大语法树语法的差异并不一定表示语义差异,编码器很难识别语义相似性

上图就表示了识别出来的子树,其中 int n = arr.lenth 包含了一个表达式 arr.lenth ,所以把两者都识别出来了
Learning Source Code Representation
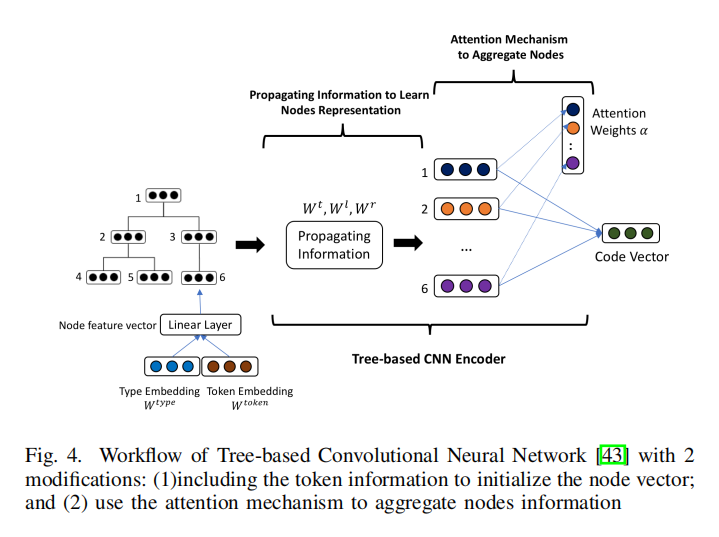
使用了 TBCNN作为编码器,主要和原来的设计有两点不同:
- 将文本信息包含到节点初始化嵌入中,而不是只使用type信息
- 用一种注意机制来代替动态最大池化来组合节点嵌入
通过编码器学习权重主要下面三个步骤:
- 学习结点表示:自底向上,父节点获得子节点及其后辈结点的信息
- 聚合结点信息:要将AST用固定维度的向量表示需要用注意力机制
- 预测子树:得到向量后预测从T中提取出来的子树
Use Case
Code Embedding Vectors for Unsupervised Tasks
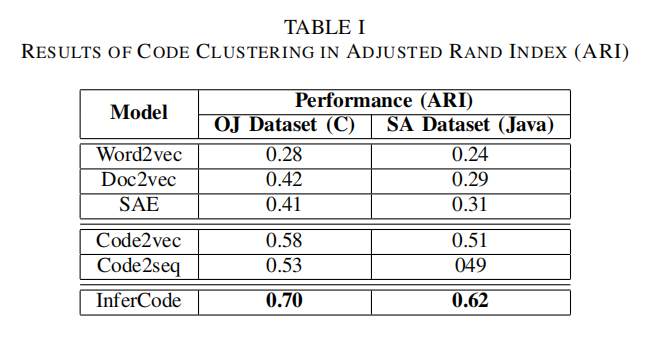
- Code Clustering:将使用预训练输入得到的输出向量使用欧氏距离指标和聚类算法如k-means实现
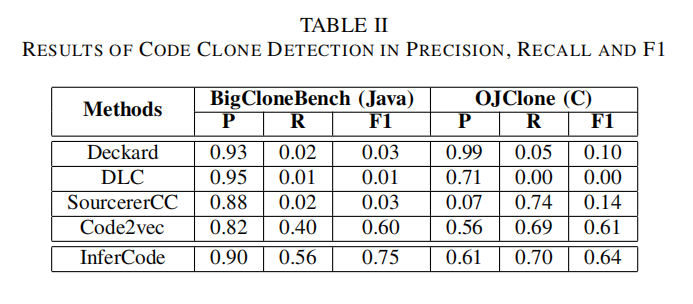
- Code Clone Detection:两个向量做余弦相似度,阈值设定为0.8
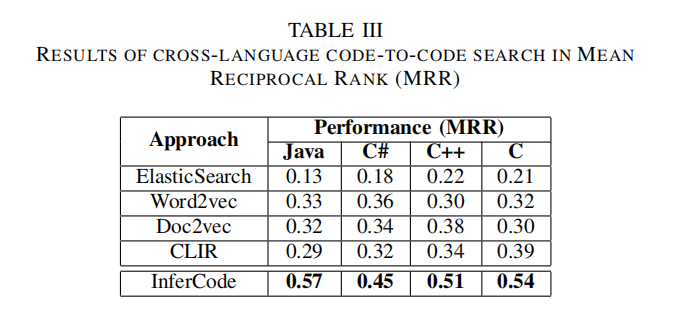
- Cross Language Code-to-Code Search:模型接受5种语言输入,给定一种作为查询,转化为向量空间最近查询
Fine-Tuning for Supervised Learning Tasks
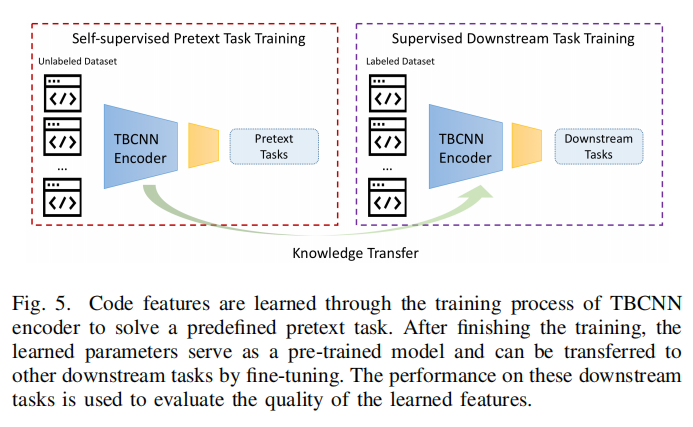
在两项任务上微调:代码分类和方法名命名
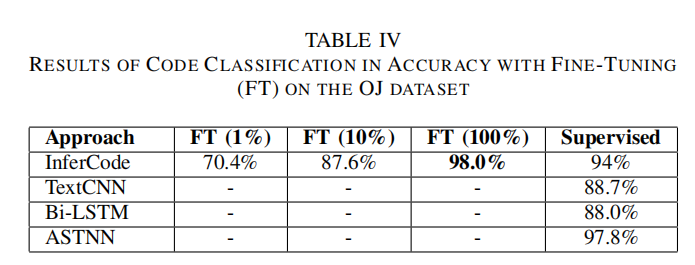
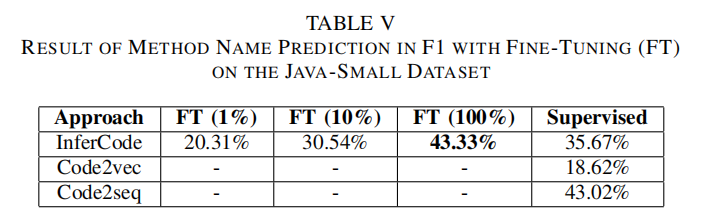
Experiment
代码聚类
代码克隆检测
交叉语言代码到代码搜索
代码分类和方法名命名