论文地址:MeLU: Meta-Learned User Preference Estimator for Cold-Start Recommendation
论文实现:https://github.com/hoyeoplee/MeLU
本文参考:https://blog.csdn.net/qq_36426650/article/details/109378554
MeLU:元学习用户冷启动+证据候选策略
Abstract
先前的推荐工作主要有两大局限性:1.消费少量物品的用户推荐效果很差;2.证据候选不够充分识别出用户偏好。作者提出MeLU解决了上述问题,同时提供了一个证据候选选择策略,来确定区分物品的定制偏好评估。用两个基准数据集验证了MeLU,所提出的模型比数据集上比两个比较模型减少了至少5.92%的平均绝对误差
Introduction
协同过滤、基于内容或混和系统都很难处理新用户(用户冷启动)和新物品(物品冷启动),因为缺少用户与物品之间的交互信息,为了解决这种问题,比如Netflix就根据最热门电影和电视节目推荐给新用户,这些视频就被称为:evidence candidates(证据候选),系统再根据用户从候选集中选择情况再推荐
先前的冷启动方法主要有:
- popularity-based:根据热门、或者随机等方式为用户提供一定的推荐列表,试图先获取一定的反馈
- evidence candidate:遵循一种策略,事先获得一定的候选物品供用户选择,其次根据交互结果为用户进行推荐
先前的推荐系统主要被两个问题限制:
- 系统应该能够给只打了很少评分的新用户推荐,但系统一般没为这个设计,即使是用户画像依旧基本没提升,比如两个20岁失业男子,一个看了点恐怖电影,一个看了点科幻电影,但推荐列表依旧差不多,因为他们的年龄,状态等等用户信息太相近了
- 现有系统提供的证据候选不可靠:因为都是推荐热门的东西。作者就有意的选择一些不热门的证据候选来提高系统对新用户的效果
本文主要有以下四项贡献:
- 在推荐系统中引入了MAML概念来缓解冷启动问题
- 第一个确定可靠的证据候选的研究来提高初始化推荐性能
- MeLU可以使用每个用户独特的物品消费历史
- 在两个数据集和一个用户调查上对系统和证据候选选择策略进行验证
Method
User Preference Estimator
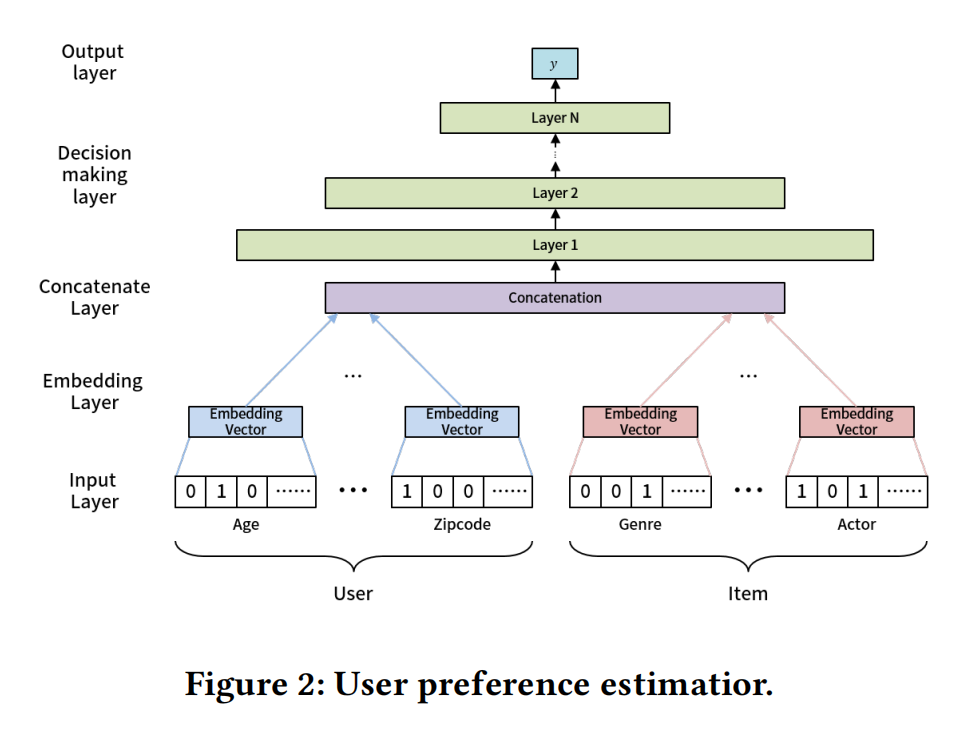
- 输入层(input layer):对于离散变量,embedding映射到连续空间,此处包含的embedding参数;对于连续的变量则跳过embedding层直接与其他向量进行拼接;
- 嵌入层:根据离散的特征,通过嵌入层嵌入到连续的向量空间中;
- 拼接层:将多个特征向量直接拼接起来;
- 决策层:由于用户和物品的向量维度不完全一致,所以无法使用矩阵分解,而使用多层神经网络;
- 输出层:则表示优化的目标,可以是点击率,隐式反馈、停留时长等;
Meta-Learned User Preference Estimator
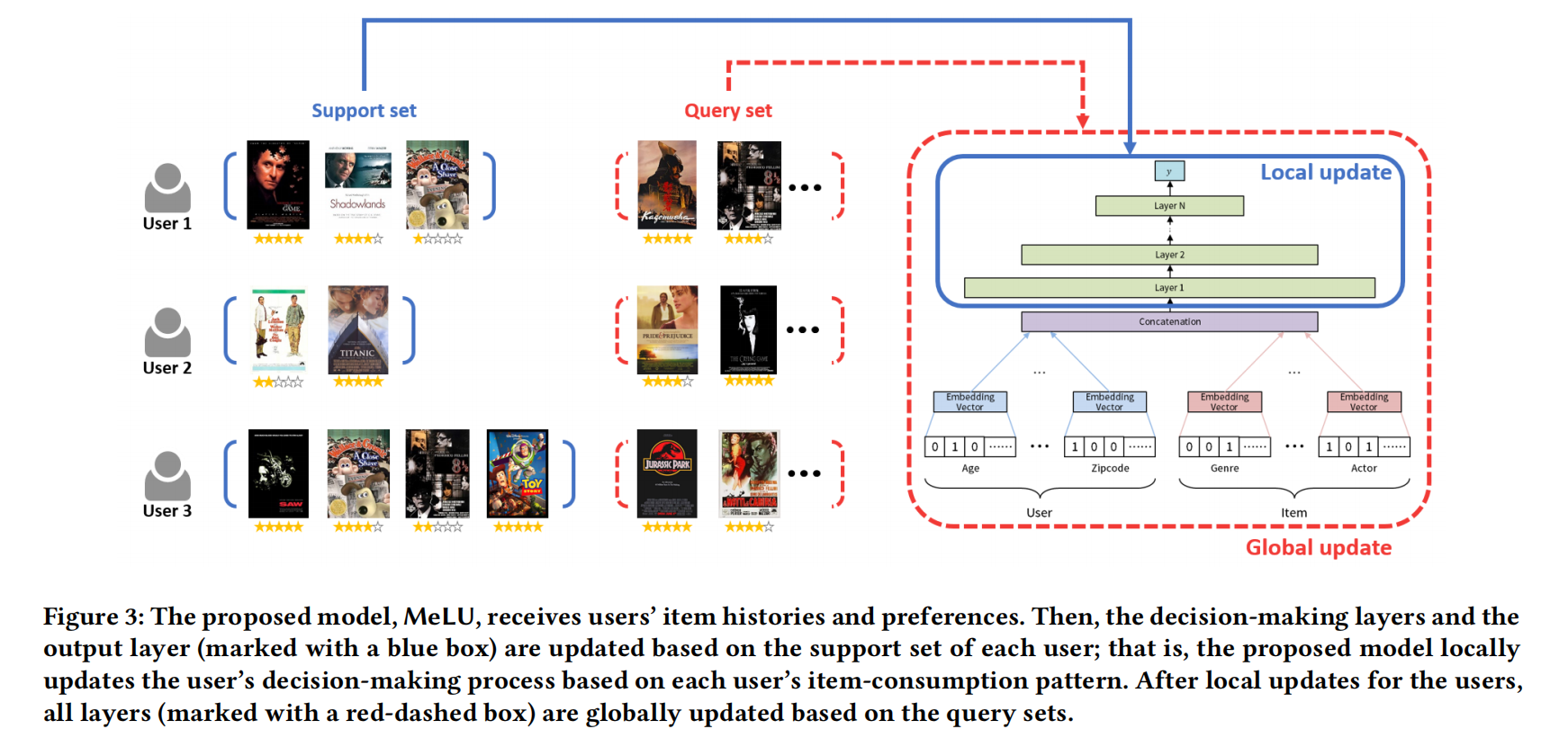

支持集做局部更新(单个用户,也可以说是任务),查询集做全局更新
输入层和嵌入层作为一个整体,其对应的训练参数用 $\theta_1$ 表示,决策层和输出层作为一个整体,其对应的训练参数用 $\theta_2$ 表示。每一轮训练过程中,挑选一定数量的用户,对每个用户(相当于MAML中的Task)进行采样得到支持集,获得少量的交互数据后,计算在支持集上得到的训练loss,并计算对应的梯度实现局部更新。每个用户的局部更新均是在 $\theta_1$ 的基础上进行的
每个用户进行局部更新的目的是,模拟让模型对新的用户进行学习的过程。在全局更新阶段则是对所有用户再次采样得到的查询集上进行的,每个用户的查询集上均可以得到测试loss,并平均后计算梯度
Evidence Candidate Selection
模型中,整个用户的个性化梯度的平均Frobenius范数(矩阵各项元素的绝对值平方的总和开根号)越大(即本地更新的梯度,$||\nabla_{\theta_2^i}L_i(f_{\theta_1},\theta_2^i)||_F$),用户偏好之间的区别就越好,所以将计算梯度时将 $L_1$ 改为了 $L_1/|L_1|$ ,其中||表示反向传播单位误差的绝对值
除了更大的梯度对区分用户有用外,还增加了用户对物品的意识。通过计算gradient-based和popularity-based的值作为平均Frobenius范数和用户-物品对里使用到的交互数。前者表示每个用户在局部更新时的梯度的F范数,并进行归一化;后者是该物品的热门情况,即该物品被用户交互的相对频率,可以反映用户-物品的交互是否频繁。如果梯度的F1范数越大,或者交互越频繁,我们认为这个物品可能是该用户的偏好,给与更高的分数(两个value归一化的乘积)
Experiment
看了下原代码,支持和查询集的划分就比较简单,最后10个是查询集,前面都是支持集
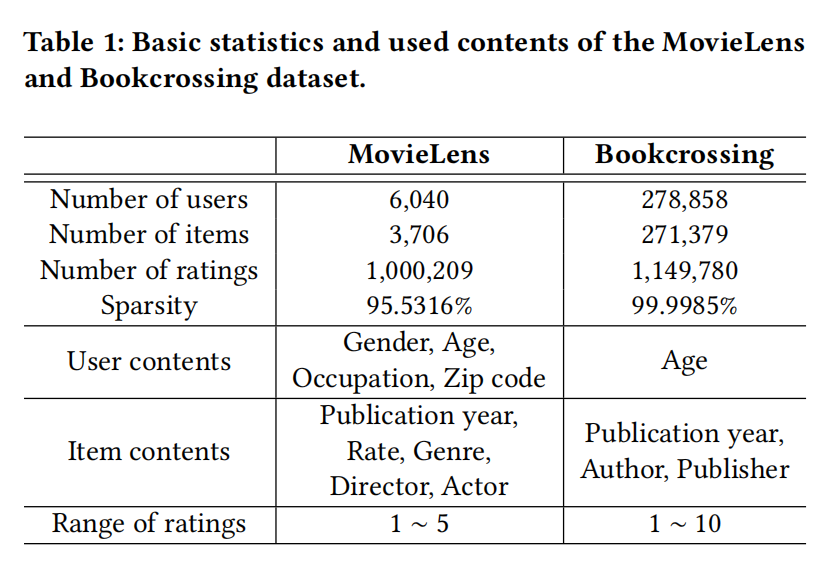
包括MovieLens和Bookcrossing两个数据集
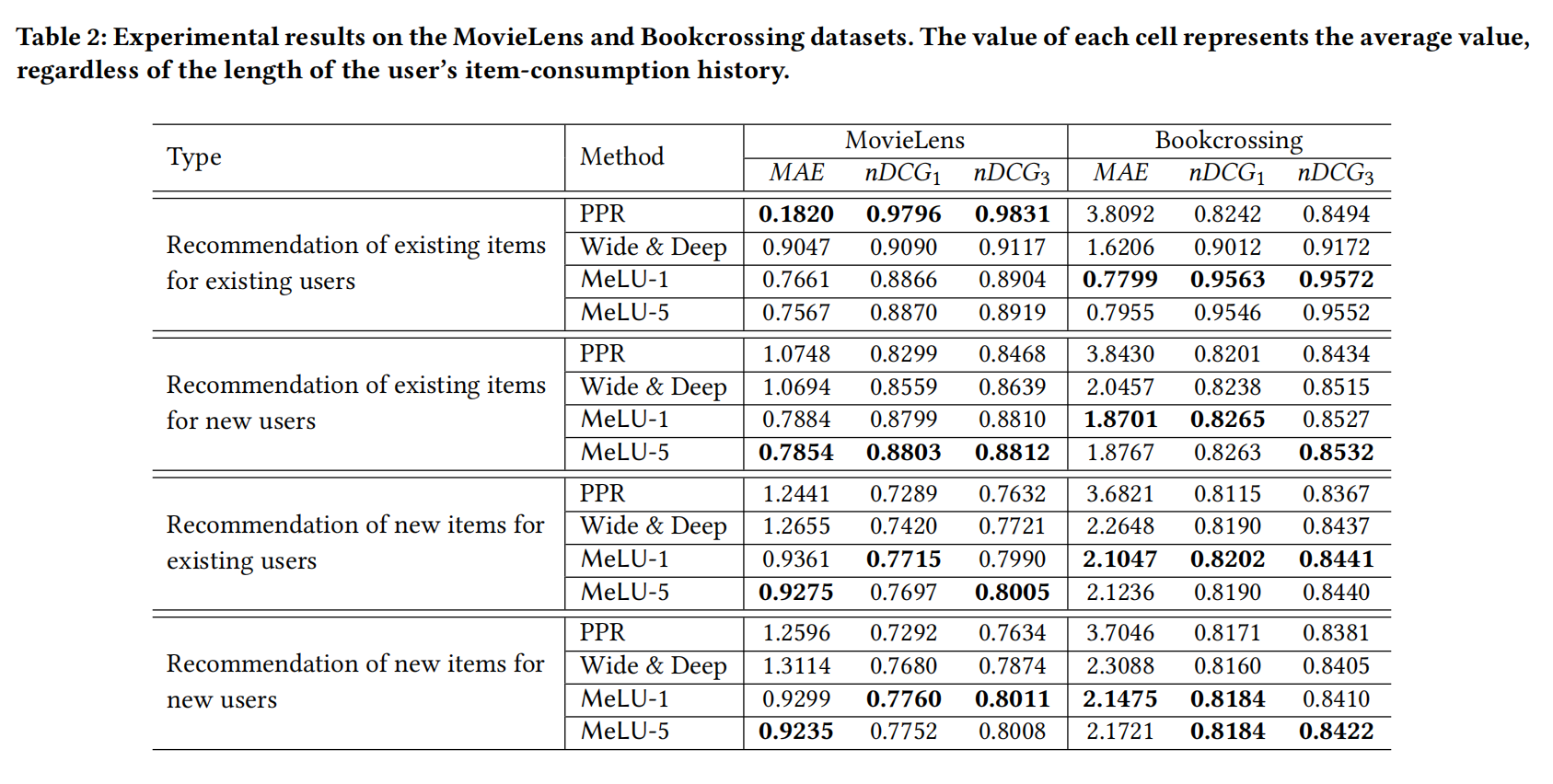
针对四种推荐场景,可以得到相关的结果,其中PPR和Wide&Deep分别是一种基于用户和物品特征的冷启动推荐方法和基于记忆和泛化的推荐模型,MeLU-1和MeLU-5则分别表示局部更新的次数分别是1次和5次
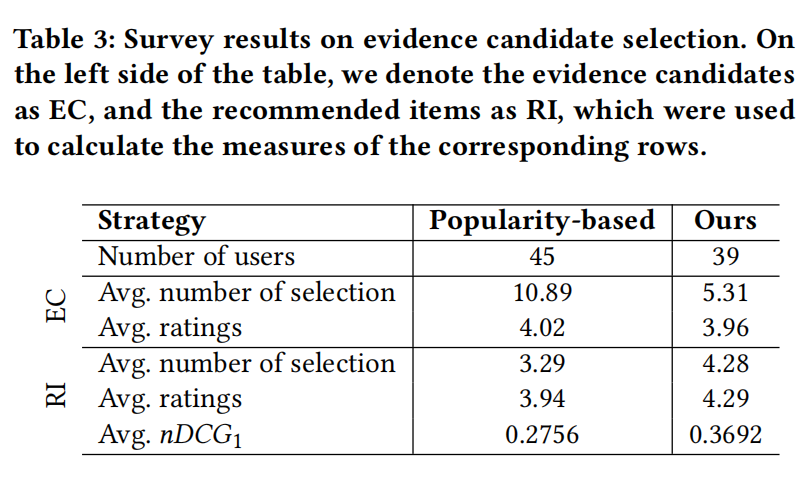
测试候选物品策略,基于热门的方法被选可能仅仅是因为热门,和用户兴趣没关系,作者提出的方法可以在很少交互数据中评估出用户偏好

