论文地址:ZeRO:Memory Optimizations Toward Training Trillion Parameter Models
本文参考:https://zhuanlan.zhihu.com/p/116484241
pytorch推出的FSDP,完全共享的数据并行API其实也是基于zero的思想
ZeRO:数据切片减少额外的内存开销
Abstract
现有普遍的数据并行模式下的深度学习训练,每一台机器都需要消耗固定大小的全量内存,这部分内存和并不会随着数据的并行而减小,因而,数据并行模式下机器的内存通常会成为训练的瓶颈。这篇论文开发了一个Zero Redundancy Optimizer (ZeRO),主要用于解决数据并行状态下内存不足的问题,使得模型的内存可以平均分配到每个gpu上,每个gpu上的内存消耗与数据并行度成反比,而又基本不影响通信效率
在100B参数下400个GPU并行的情况下,获得一个几乎超线性的加速。可以训练13B的参数,且不需要模型并行,使用模型并行才能运行的大模型使用数据并行方式进行训练,以减少模型并行的额外开销
Introduction
像BERT-large,GPT-2,Megartron-LM这些都很大,一个卡放不下。数据并行方法不能降低每个卡内存的使用,所以如果一个卡是32GB内存,最多能放1.4B模型,如果用流水线并行,模型并行或CPU-Offloading,虽然可以做到更大,但是计算和通讯的效率比有些问题
这些方法里面比较好的是模型并行(张量并行),但是模型并行不能在后面模型做得更大了,因为计算和通讯比不是很好。它主要是将模型垂直切开,每个层都要做通讯导致通讯量很大,对于单机的带宽通讯量负担比较大。如果把使用两个DGX-2结点的40B参数模型测试的话只得到了5Tflops的峰值
对大模型来说内存主要用在了1.保存优化器状态、梯度、模型参数上;2.中间值,暂存的缓存,开内存的碎片化等
Optimizing Model State Memory
核心算法就是把模型切开放在不同地方
Optimizing Residual State Memory
把数据并行ZeRO-DP和优化状态ZeRO-R合起来就是ZeRO
Where Did All the Memory Go?
Model States: Optimizer States, Gradients and Parameters
通过ADAM训练时对于每个w(可训练参数)主要是维护一个梯度的momentum和variance的复制,本来就需要维护w和一个梯度,再维护两个就是翻倍,主要是在混精度训练时问题会更严重一些,而nvidia的卡在半精度(fp16)上计算更快,因为nvidia做了一些很大的矩阵核和一些优化,所以在半精度上会快好几倍
半精度计算就是层的输入和输出都是在fp16上做运算,但是因为这个精度不是很够,可能很多比较小的数加起来还是0,所以权重更新的时候作者使用的是fp32,再转成fp16
在这种混精度训练下,假设模型有 $\Phi$ 个字节的参数,在fp16下维护参数和梯度分别都是 $2\Phi$ 个比特(16/8)。但是fp32下,需要存一个w和在ADAM里面两个状态,加起来是 $12\Phi$ ,也就是计算前向和反向的时候只用 $4\Phi$ ,为了更新要存 $12\Phi$ ,这就导致了大量的冗余
对于一个拥有15亿个参数的GPT-2这样的模型,这导致了至少24gb的内存需求,远远高于单独保存fp16参数所需的3gb内存。
Residual Memory Consumption
Activations 在前向的时候不能把一些中间结果删了,因为反向还要用。假设用GPT-2有1.5B个参数,序列长度1000,批量大小32需要60GB内存来存中间值
Temporary buffffers 一个flat的fp32缓冲区将需要6GB的内存
Memory Fragmentation 有可能有30%的内存是碎片化用不了的
ZeRO: Insights and Overview
Insights and Overview: ZeRO-DP
- 数据并行一般比模型并行效率高,因为模型并行导致通讯增加计算减少
- 数据并行内存不有效,需要很多额外开销
- 数据并行和模型并行都需要维护自己要维护的那些w在fp32上的一些中间状态
所以作者就指出对任何一个w在一个GPU上存一份,其他GPU要的时候去取,类似于参数服务器的思想,这样使得内存使用率下降
Insights and Overview: ZeRO-R
Reducing Activation Memory 在MP里面每个输入在每个GPU都复制了一份,每个GPU在接下来可以维护一小部分,要用再取,用带宽来换空间
Managing Temporary buffffers 开固定大小
Managing fragmented Memory 做内存整理
Deep Dive into ZeRO-DP
三种分割方法:$P_{os}$,$P_g$ 和 $P_p$,也被称作zero-1,2,3
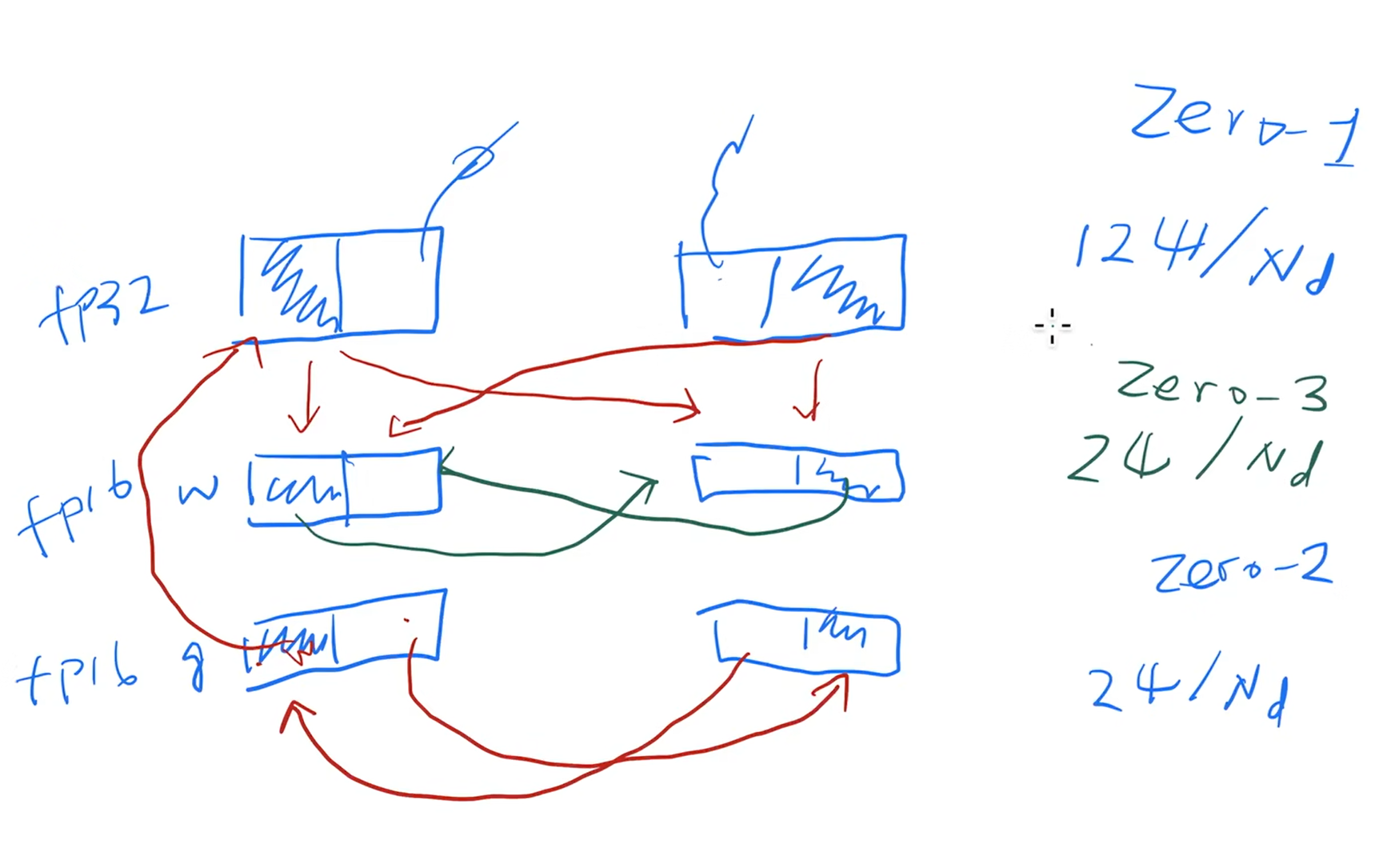
zero-3有一些额外的通讯,也可以做一些异步,因为很多层的时候知道该算什么层可以提前要数据
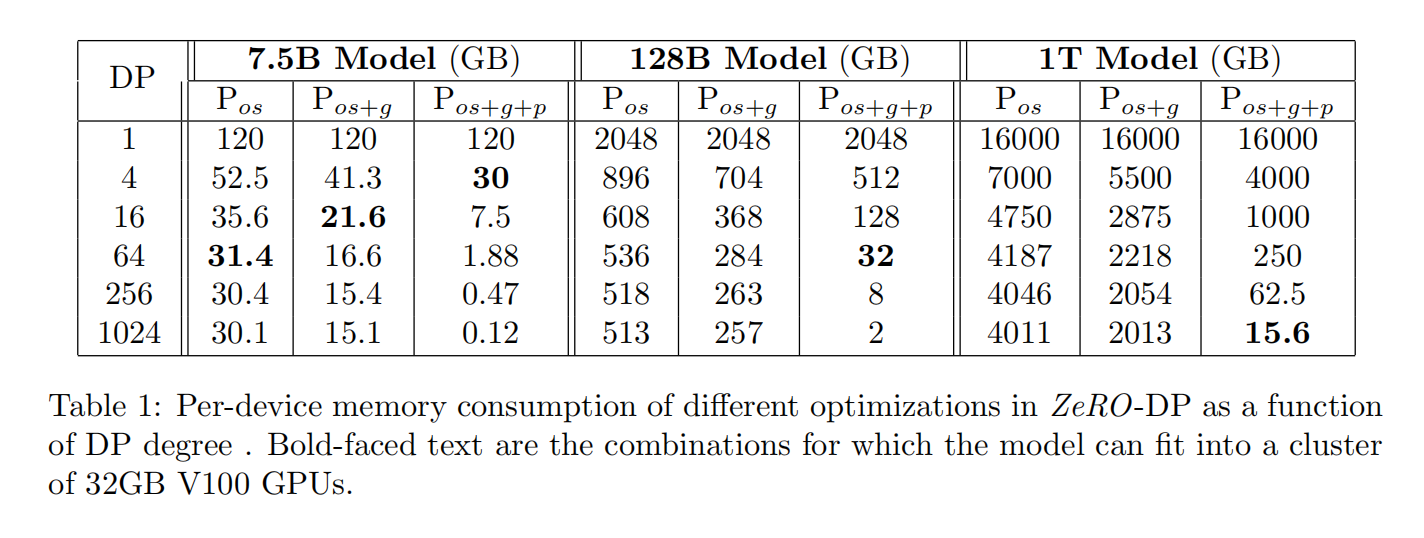
上表是不同模型并行度和gpu下可实现的最大模型(以参数计量),最右边是作者的实现的测量值,左边是理论值。因此,这说明作者提出的内存计算是基本可靠的。按照论文中的假设,理论上Pos,Pos+g,Pos+g+p这三种内存优化模式,相对基线baseline,其内存消耗大致相当于原来的26%,13%,1.7%
Deep Dive into ZeRO-R
P_a: Partitioned Activation Checkpointing
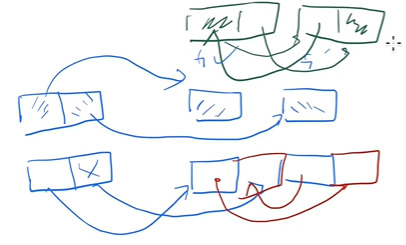
额外的代加是在反向的时候基本要把所有层的输入重新传一遍,但是大部分时候不需要把输入全部复制存在各个GPU里面,这就解决了megatron里面每个输入都需要存的问题,现在只用切开存,变成GPU分之一了
C_B: Constant Size Buffffers
因为做了切片所以每次发的数据可能比较小,可能几kb的样子,在带宽比较大的情况下是不划算的,所以可以等数据量达到一定程度后一次性发出去,也就是一个buffer等数据,超时了再发出去
作者这里用一个固定大小的buffer填满了再发能够有效利用带宽,怎么设置大小可以通过超时来判断,比如buffer比较大的时候经常超时,就可以把buffer弄得再小一点,现在很多的分布式系统底层都实现了这种逻辑
M_D: Memory Defragmentation
每个GPU维护自己那一块内存在预先开好的一片区域里,当需要新变量时从里面开,这样开的比较久的内存碎片问题会缓解
Implementation and Evaluation
Hardware 400台V100的集群, 800 Gbps的带宽
Baseline Megatron-LM
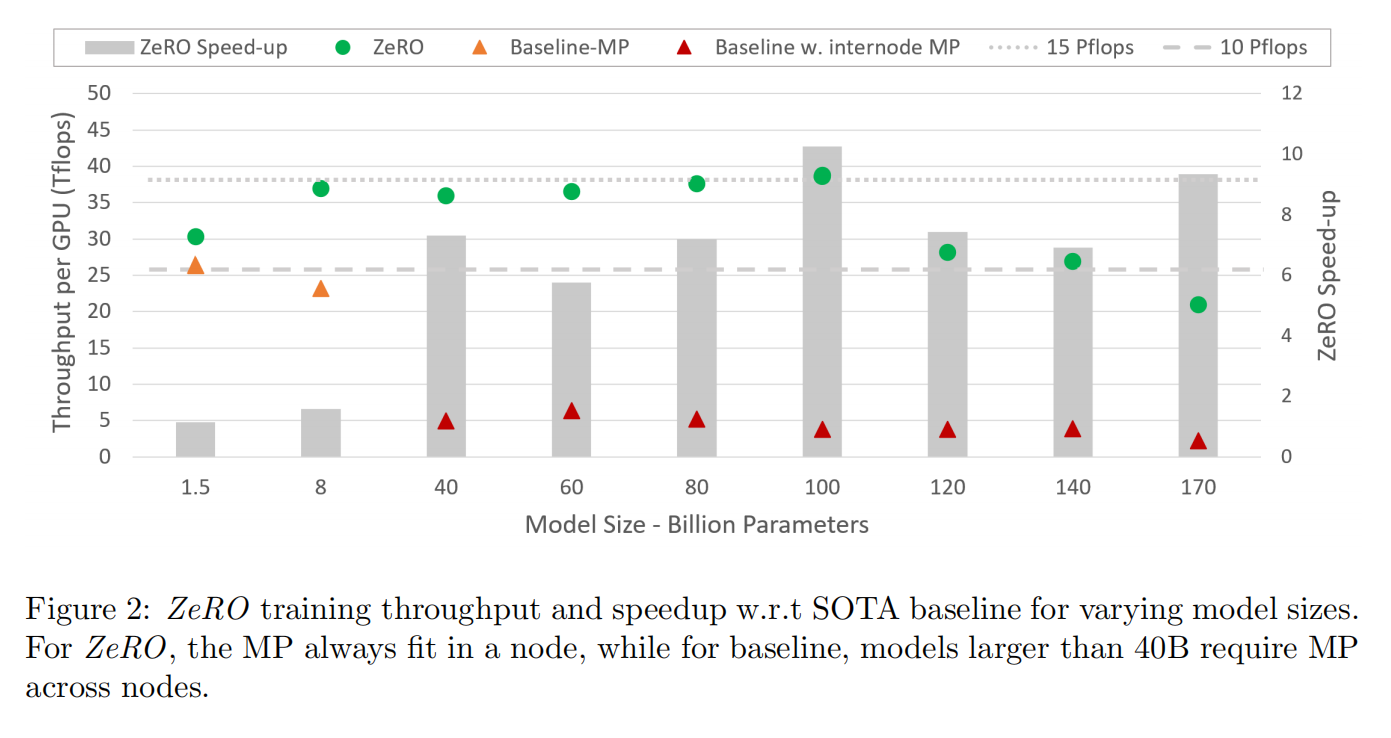
给一个特定大小的模型,用Megatron来实现,当8卡以上时因为megatron需要跨机器就导致效果很低
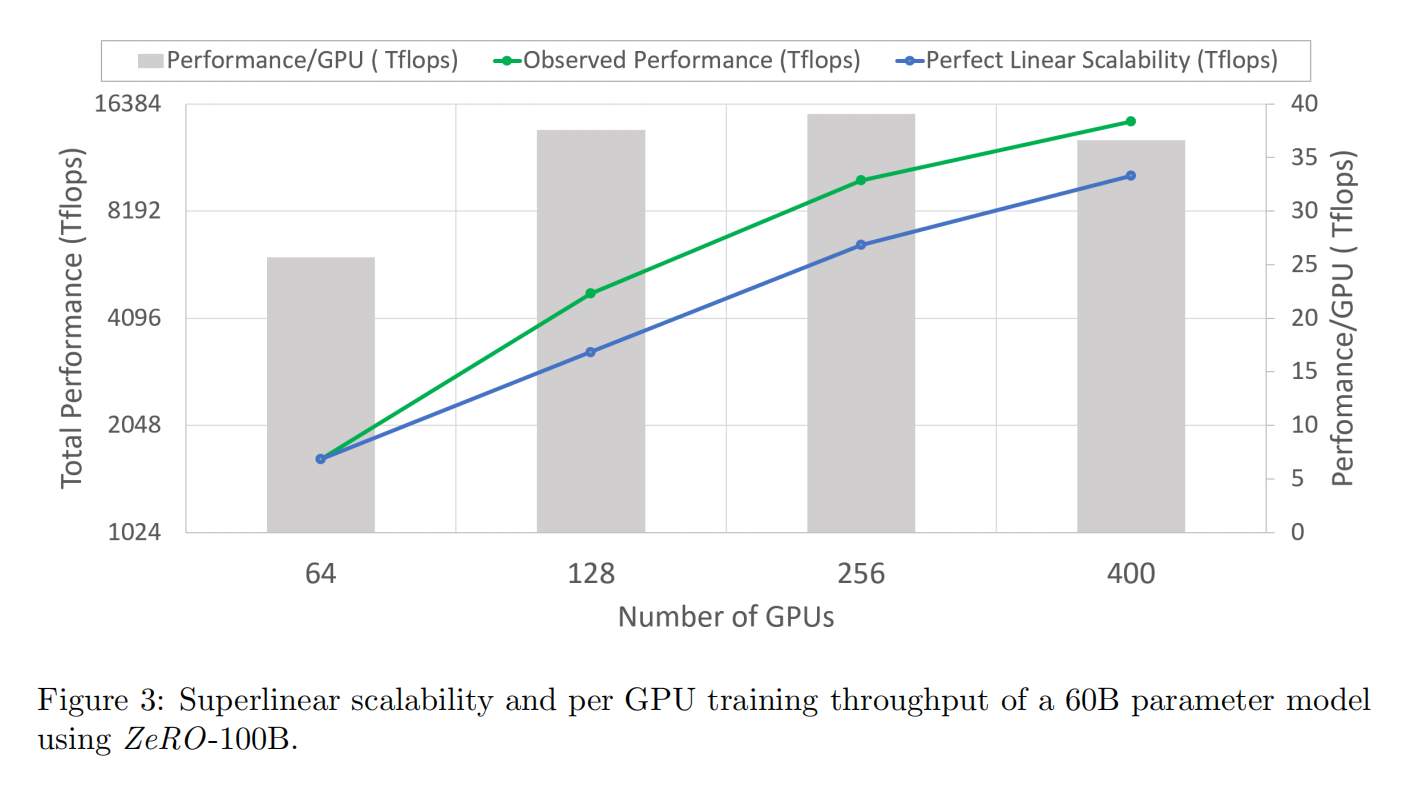
超线性的增长,可以看到在128卡上时性能好了不止2倍,因为划分到每台机器的数据变少了,每台机器拿到的批量大小变大了,更大的矩阵更好利用了GPU性能提升了,以及计算变多通讯不变使得通讯比更好了
Concluding Remarks
在做allreduce的时候不需要把所有结果reduce到所有GPU上,每个GPU负责自己的一块,需要完整数据时才重新发一次

