论文地址:How to Retrain Recommender System?A Sequential Meta-Learning Method
SML:时序训练+知识转移CNN
Abstract
实际的推荐系统需要定期用新的交互数据来重新训练刷新模型,但因为历史数据往往很多,重新训练特别耗时,所以本文主要就研究推荐系统的模型重新训练机制。作者第一个初衷是在历史数据上重新训练没有必要,因为已经训练过了,同时只在新数据上训练容易过拟合,里面信息太少而且对用户长期偏好影响不剧烈,所以提出了新的训练方法,学习转移过去的训练经验而不是数据,通过一个神经网络组件,为了优化这种“未来性能”,在下一个时期评估推荐准确性
实验表示在两个真实数据集上有巨大的加速,同时比重新训练的效果更好
Introduction
三种重新训练的方法:
-
微调:只在新数据上做更新,非常消耗时间和内存,忽视了长期兴趣偏好信号,容易过拟合
-
基于采样的再训练:从历史和新数据中采样来训练,要保留长期偏好又要仔细选择新的信息,由于抽样导致信息丢失所以通常比用所有历史数据效果更差
-
全部再训练:效果好,但最耗资源
上述方法各有优劣,但是都缺少了明确的再训练的目标,所以一个有效的再训练方法需要考虑这个
全部数据再训练虽然一般是最好的,但是没必要,因为在先前的训练中模型已经从历史数据中蒸馏出了“知识”,所以一种知识迁移的模型应该不使用历史数据也能达到和全部数据再训练一样的效果
作者提出的新的再训练方法主要以下考虑:
- 构建一个知识迁移的组件,将历史数据训练的知识迁移到新的数据上,设计了一个CNN的传输组件,将之前的模型参数作为常数输入,现在的模型视为可训练参数
- 优化转移组件在未来的推荐表现,除了对新收集的数据进行正常训练外,还进一步对转移CNN进行了下一个时间段未来的数据训练。可以视作一个元学习的实例,每个时间段的重新训练视为一个任务,当前时间段的新数据视作训练集,下个时间段的未来新数据视作测试集
本文主要贡献:
- 强调了推荐系统中再训练方法的必要性并提出了时序再训练方法作为优化目标
- 提出了一种新的再训练方法仅需要新数据训练,且通过优化未来推荐表现而有效
- 在两个真实数据集上实验
Problem Formulation
假设每次重新训练视作一个任务,通过过去的数据和模型参数得到新模型,用下一个时间段数据测试,可以定义为
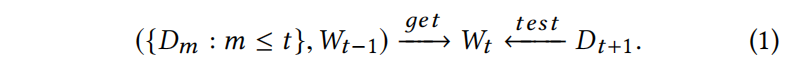
这种就是将所有数据用于重新训练,用 $W_{t-1}$ 作为初始化,耗时长,时间增长计算能力增加。另一个问题就是这种完全再训练缺乏对下个时间段数据 $D_{t+1}$ 的显式优化
所以本文主要只利用新的数据 $D_t$ 通过 $W_{t-1}$ 参数来训练,这样来获得一个在 $D_{t+1}$ 表现不错的模型
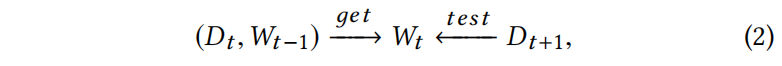
与标准的元学习不同的是任务是一个序列,在先前时间完成后才能转移掉下个时间
Method
Model Overview
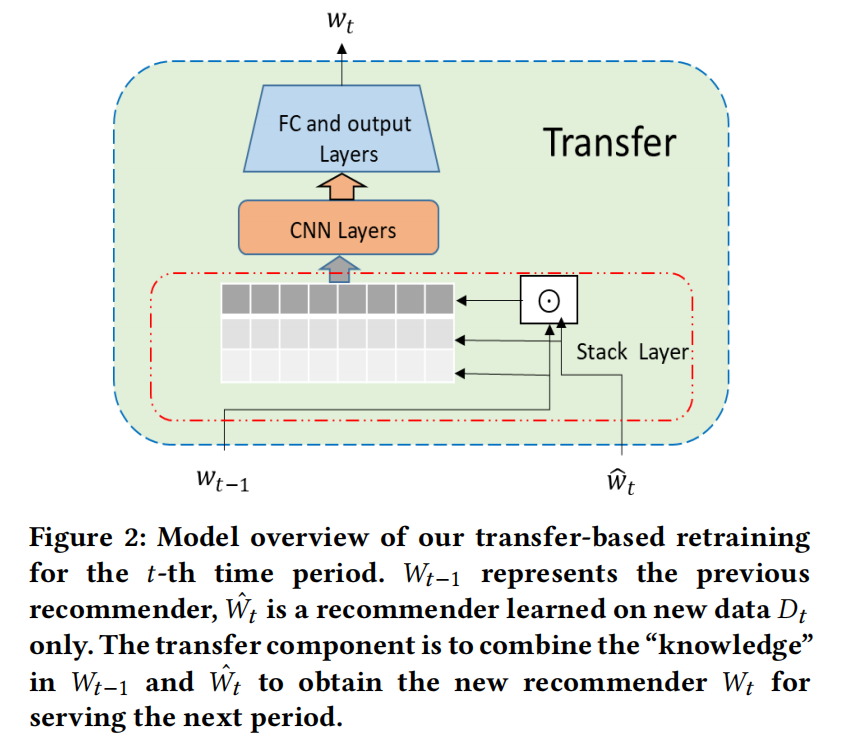
主要由三部分组成:
- 上个时间段的模型 $W_{t-1}$
- 需要从当前时间段数据 $D_t$ 学习出的模型 $\hat{W_{t}}$
- 转移组件将包含有知识的模型 $W_{t-1}$ 和 $\hat{W_{t}}$ 组合形成新的推荐模型 $W_t$
再训练的过程主要包含以下两步:
-
获得 $\hat{W_{t}}$ ,可以通过一个标准的推荐损失获取 $L_r(\hat{W_{t}}|D_t)$
-
获得 $W_t$ ,作为转移组件的输出
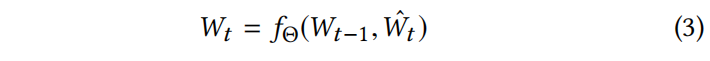
Transfer Design
如果 $W_t$ 和 $W_{t-1}$ , $\hat{W_{t}}$ 是同一形状,所以可以用加权求和来表示,但这种方法表达能力有限,而且不能适应不同维度的关系
另一种方法是用MLP,理论上MLP是可以达到普遍近似,但是它没有强调同一维的参数之间的相互作用,比如假设模型为矩阵分解,参数为用户嵌入表示, $W_t-W_{t-1}$ 表示用户兴趣变化, $W_{t-1}\odot \hat{W_{t}}$ 的维度反应了用户短期和长期兴趣的重要性,MLP缺乏这种机制
所以作者想设计出能够强调 $W_{t-1}$ 和 $\hat{W_{t}}$ 维度关系,以及抓取不同维度关系的转移组件,所以作者想到了CNN
Stack layer
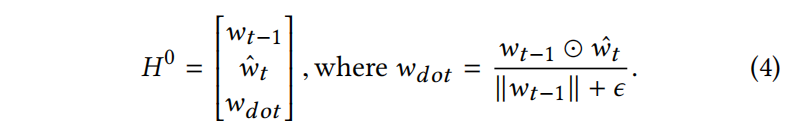
把三个参数堆叠起来看起来像图片,点乘经过了规范化
Convolution layers
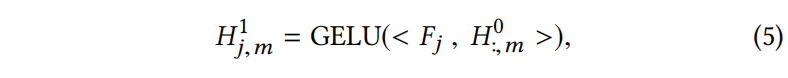
$F_j$ 是1x3的一维过滤器,$H^0_{:,m}$ 是向量 $H^0$ 的第m列,<>是向量内积,GELU是高斯错误线性修正单元激活函数,类似于RELU
比如假设过滤器为[-1, 1, 0]就可以表示 $W_{t-1}$ 和 $\hat{W_{t}}$ 之间的差值,为[1, 1, 1]可以获得在 $W_{t-1}$ 和 $\hat{W_{t}}$ 上比较显著的特征。另一个用一维过滤器的原因是维度的顺序是没有意义的
Full-connected and output layers
最后是全连接和输出层
Sequential Training


Experiment
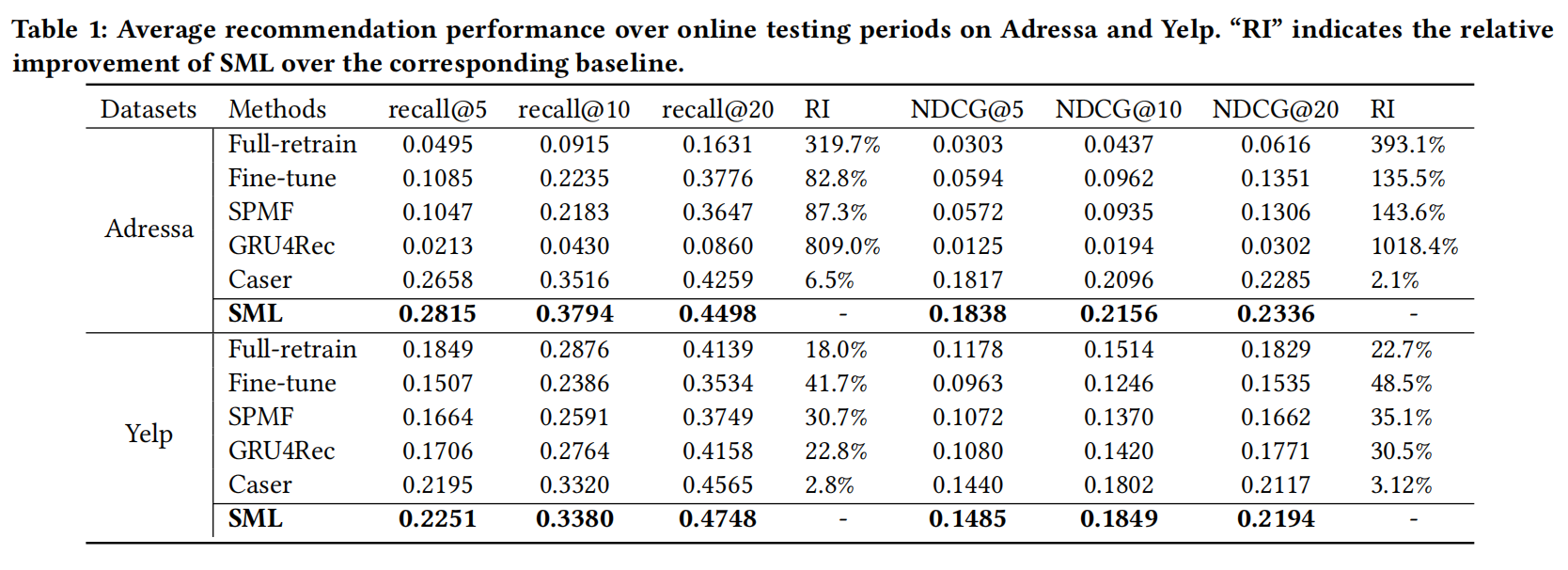
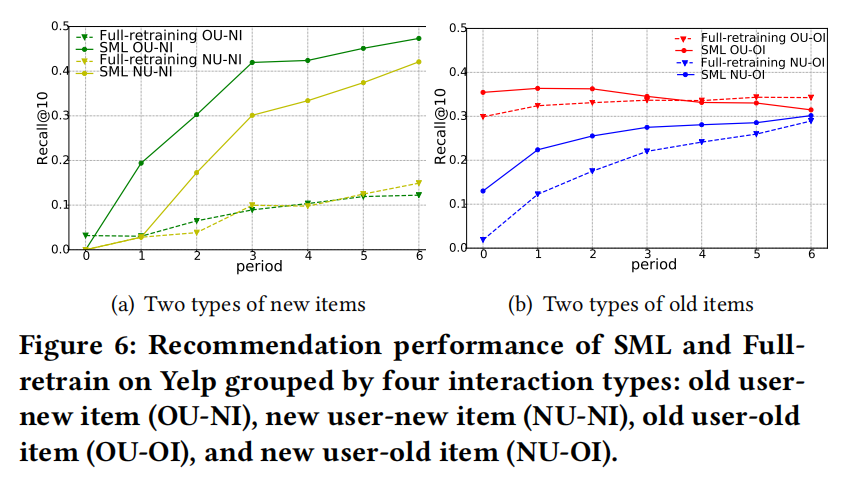
表现略低,但其实这个不是文章主要卖点
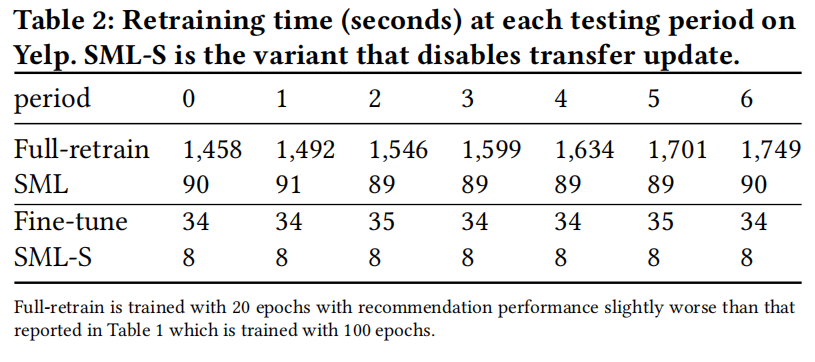
可以看到相比较于微调训练时间少了很多
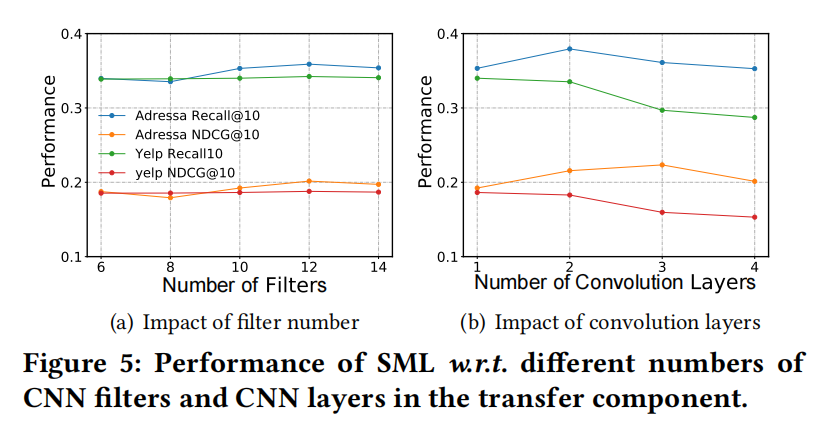
不同CNN过滤器和层数下的消融实验和推荐效果召回率

