Survey:推荐系统元学习综述
Abstract
目前的深度学习推荐系统方法都存在着数据和计算的瓶颈,而元学习方法能够很好的解决这种数据稀少的问题,能够带来更好的提升,特别是在可用数据非常有限的场景,比如用户冷启动或物品冷启动。因此本文主要讨论了现有的推荐系统场景,元学习技术,元知识表示,对于每种推荐场景还对使用元学习来提高模型泛化性的技术细节进行了讨论。最后指出了目前研究的限制以及高亮了未来的领域研究方向
Introduction
现有的推荐系统方法使用多种数据结构的(交互对,序列,图),在预定好的学习算法下通过大量数据从头训练。这些方法都是非常需要计算和数据的,但这里存在着数据量稀少的场景,这也就限制了推荐模型的瓶颈
元学习方法的主要思想就是获取先验知识(元知识),通过原有的多任务训练好后迅速迁移到新任务上,能够在没有见过的任务下表现出不错的泛化性,类似于学习去学习(learn to learn),因其这种快速适应性使得其在图像识别,图像分割,自然语言处理,强化学习等领域都表现优异
早期的元学习推荐系统主要在个性化推荐算法选择,提取元数据集特征并对不同的数据集(任务)选择合适的算法,这种对于元学习的定义类似于自动机器学习里面的研究。后来深度元学习成为了主流,先是主要应用于减轻数据不足(冷启动),以及点击率预测,在线推荐,时序推荐也在元学习策略下
作者调查发现尽管元学习在很多方向都有综述调查,但在近期推荐系统的发展方面还没有,这是第一篇推荐方向的元学习综述
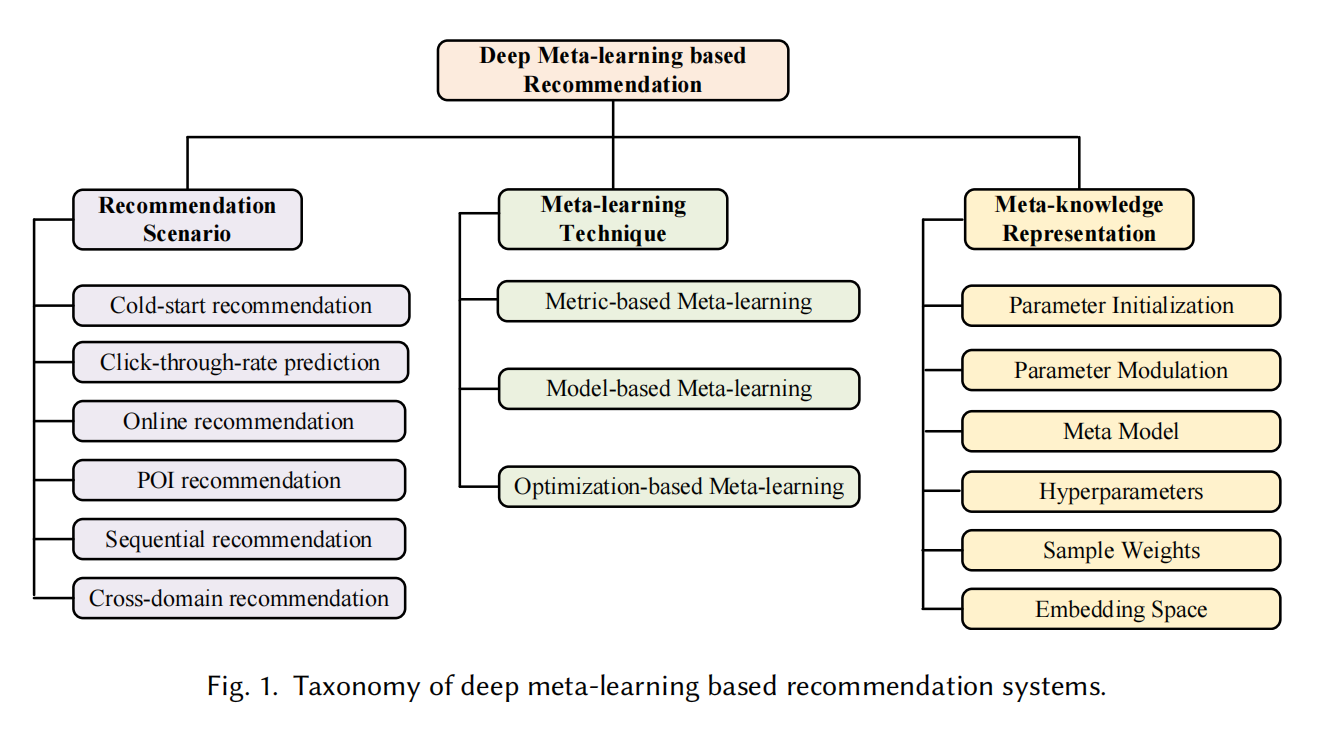
主要以三个方向分别讲解:1.推荐场景;2.元学习算法;3.元知识表示。此外作者还主要讨论了根据推荐场景不同的工作是怎么样利用元学习技术,在不同形式比如参数初始化,参数模型,超参数优化等下提取特定的元知识。还总结了元学习起步时一些常用的任务构建方法
Foundations
本节先总结了不同类别的元学习技术的代表性工作和核心思想,然后介绍了元学习技术里经典的推荐场景
Meta-learning
主要是三种:基于度量,基于模型,基于优化
以下都是元学习方法的介绍,就不赘述了
Recommendation Scenarios
Cold-start recommendation
传统的协同过滤方法和深度学习方法都需要大量数据,不局限于交互数据的话,基于内容的方法基于不同的内容信息描述了用户和物品,比如文本信息,知识图谱,社会关系网络等,这样在一定程度上减少了对交互数据的依赖,用这种额外的信息可以增强用户和物品的表示。此外,冷启动也可以视作few-shot的应用,在每个任务上只有少量的样本能够被观察,类似的,这种稀疏的用户物品交互也可以视作元学习任务
Click-through-rate prediction
最近的CTR模型主要包含两部分:embedding层和prediction层,嵌入层学习隐藏表示,预测层通过设计好的模型,但是因为在冷启动下数据量少导致缺乏很好的嵌入学习表示,所以元学习方法依旧能适用于这个场景
Online recommendation
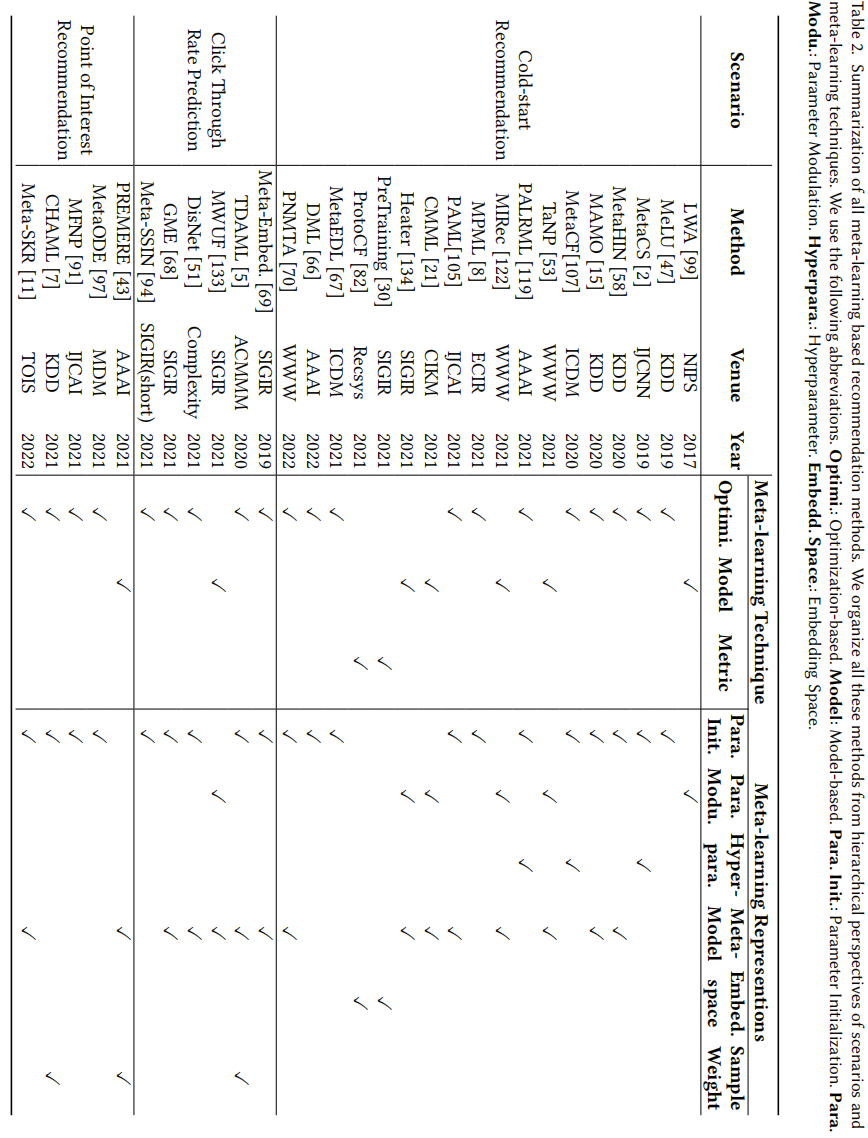
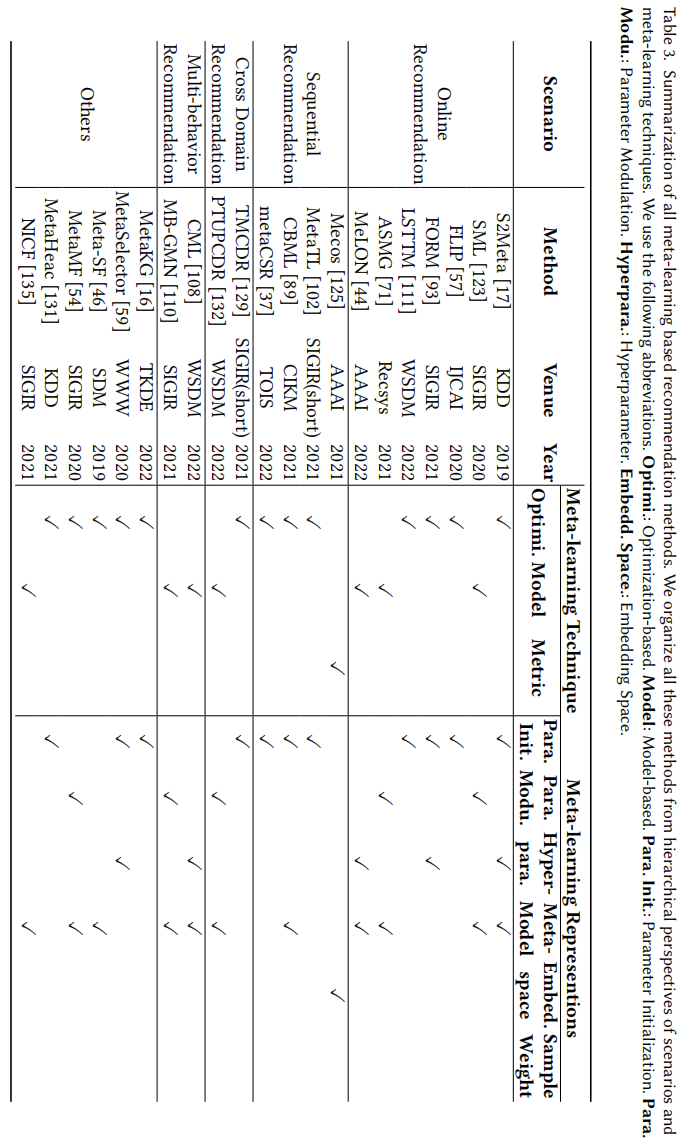
在实际的大规模推荐系统中,实时用户交互数据在时刻被收集,所以有必要周期性的刷新模型获取最新的用户情况。但是全部重新训练开销太大,所以引入元学习方法快速抓取实时的用户交互信息是必要的
Point-of-interest recommendation
由于基于地理位置的社交网络的兴起,用户是愿意通过签到记录来分享兴趣点的。相比于一般的产品,音乐等的推荐,POI推荐更依赖于从历史数据中发现时空依赖,因为用户活动很大程度上受到地理空间和时间的限制。但这个场景的数据稀疏性很明显,因为用户必须到达POI共享位置,也就是只有少部分POI被用户访问
Sequential recommendation
时序推荐方法主要利用用户先前交互过的项目序列作为输入,并发现用户兴趣演化的顺序模式。当然,当历史用户信息降低时效果都会急剧下降
Taxonomy
Meta-learning task construction for recommendation
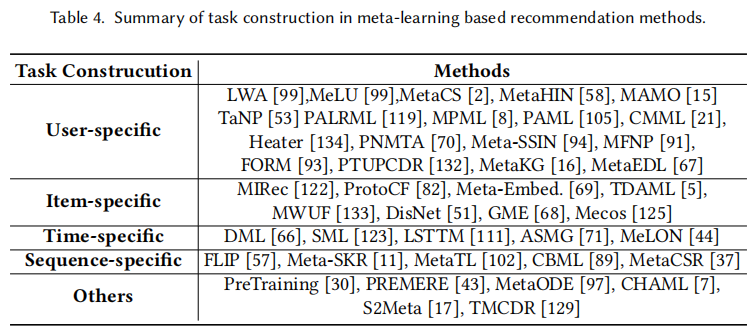
User-specific Task
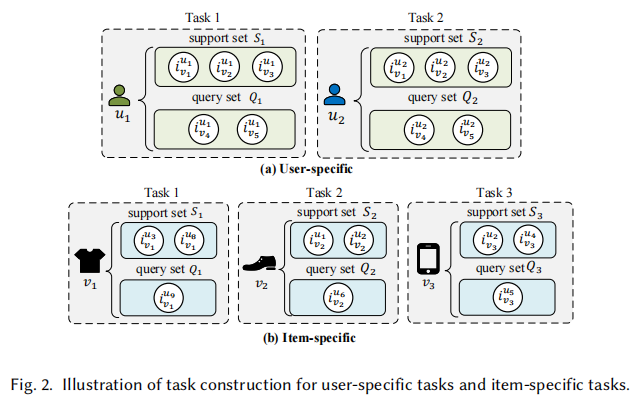
对于用户特定的任务,一个任务的支持集和查询集都来源于同一用户,不同用户就是不同任务。从元学习角度来说,就是希望在大量用户特定数据集上训练,然后元知识可以作为先验知识,从而在没见过的用户上表现良好
Item-specific Task
与用户特定任务差不多,看图2b就行
Time-specific Task
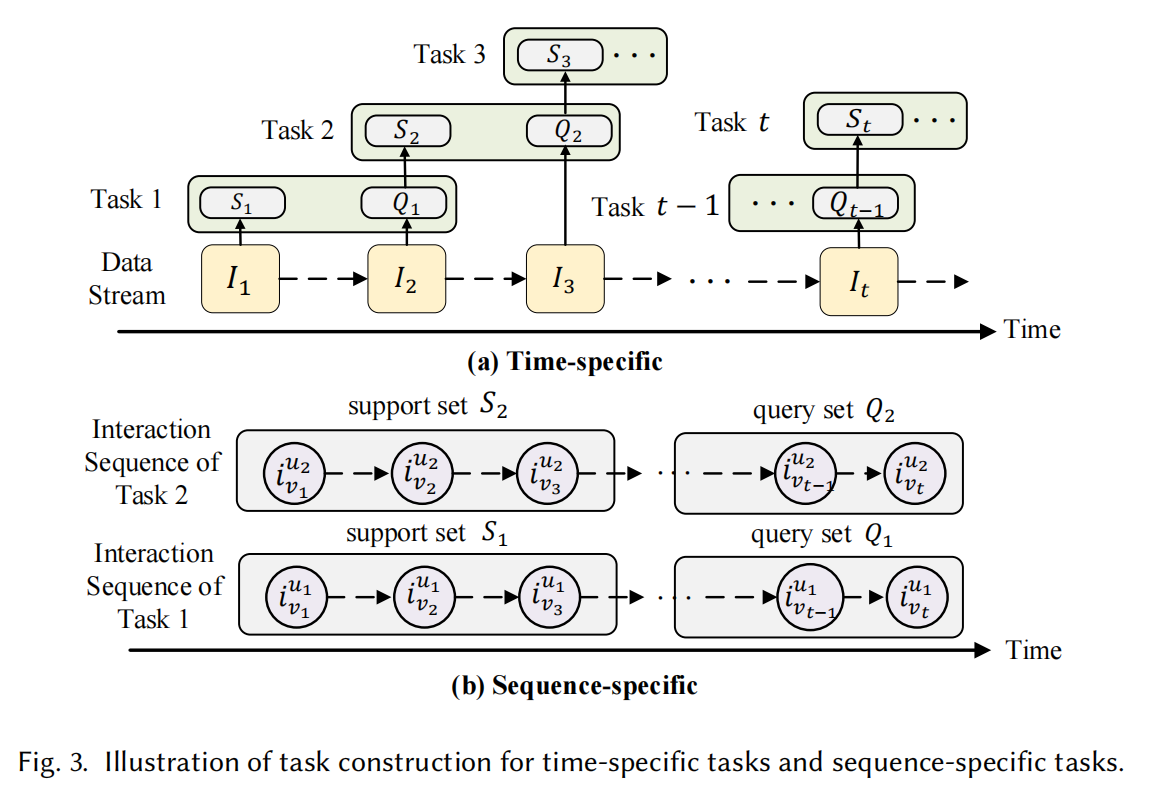
根据不同的时间槽划分任务,主要用当前时刻作为支持集,下一时刻作为查询集
Sequence-specific Task
时序特定任务也是按时间信息构建的,但是划分了不同用户或会话作为不同的任务,前K个交互数据视作训练集,后续t-K个交互视作查询集,图3b
Others
还有按场景视作任务的,在POI推荐系统中以城市视作任务的,在跨领域推荐系统中通过聚类两组有交集的用户,一组视作支持集,一组视作测试集,每组的任务是在源领域上学习嵌入分布使其在目标领域上有不错表现
Meta-learning Methods for Recommendation Systems
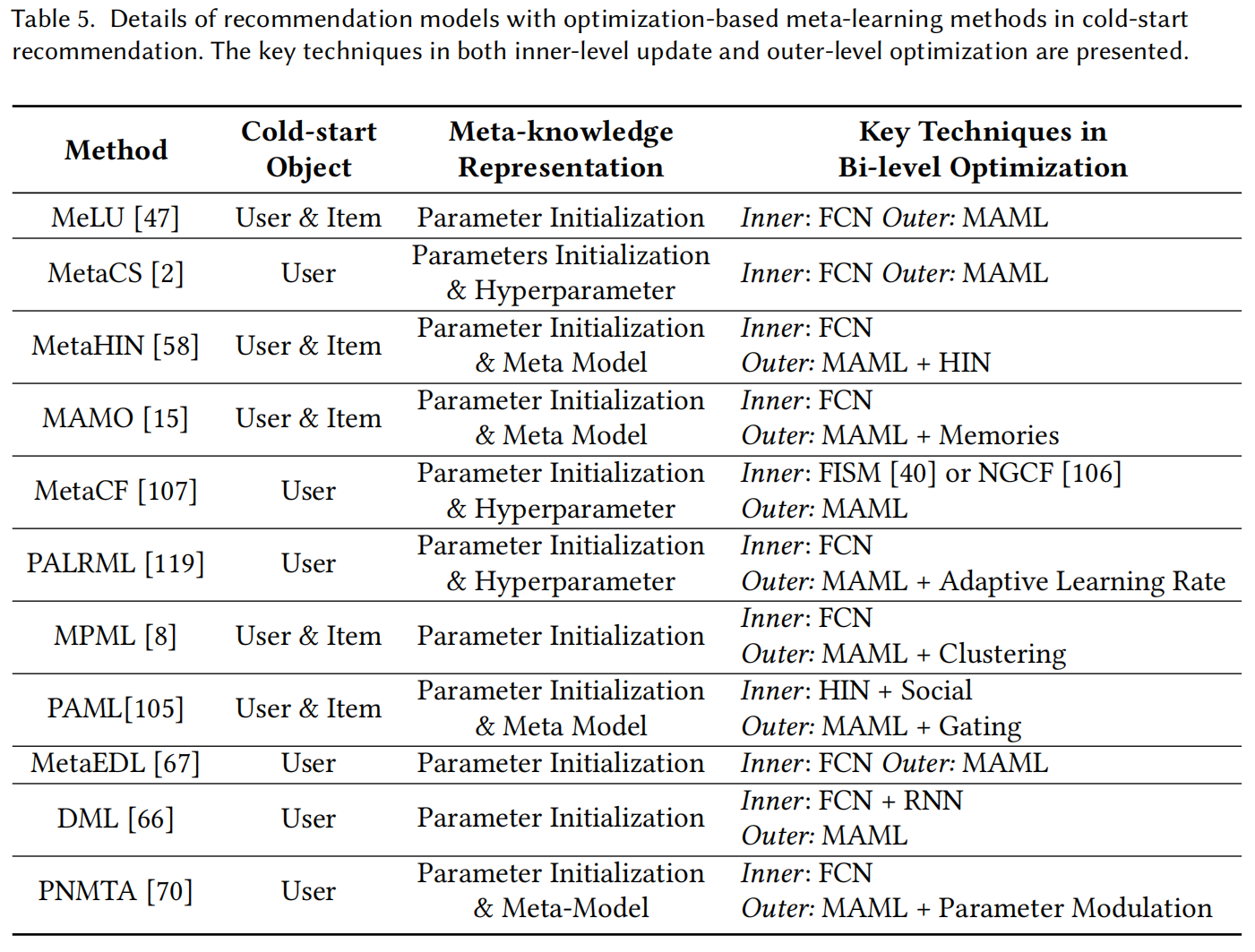
Meta-learning in Cold-start Recommendation
Meta-learning in Online Recommendation